23 分钟阅读
AgentTrust:面向Agent的工具调用防火墙
现在讨论 Agent 安全,已经不能只盯着模型会不会说错话。到了 Agent 场景里,真正危险的瞬间往往发生在工具调用之前。

https://arxiv.org/pdf/2605.04785
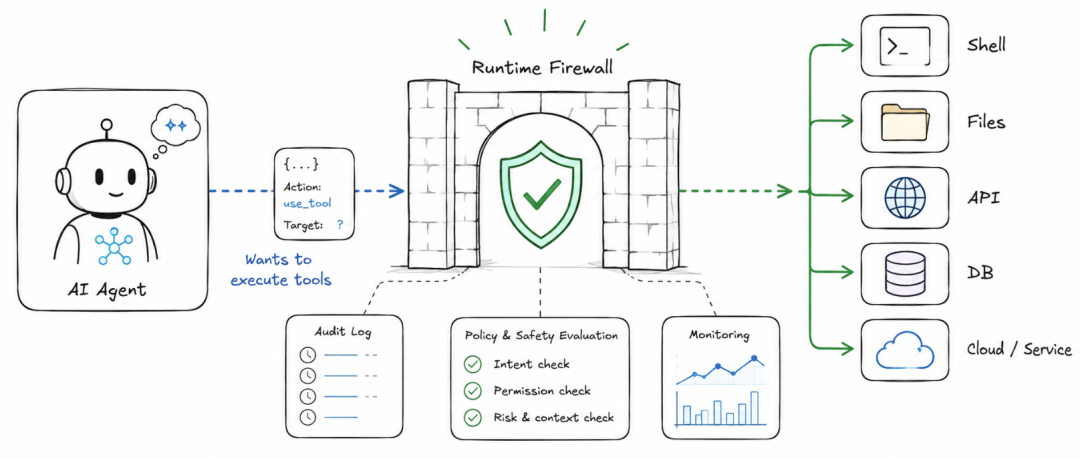
Agent风险往往发生在“动作落地”之前
事后评测能衡量 Agent 行为,但动作已经发生; 静态规则护栏可以实时拦截,但容易漏掉混淆命令和多步攻击链; 容器、gVisor、seccomp 这类沙箱能限制执行环境,却不理解动作本身的业务语义。
AgentTrust的本质:工具调用防火墙
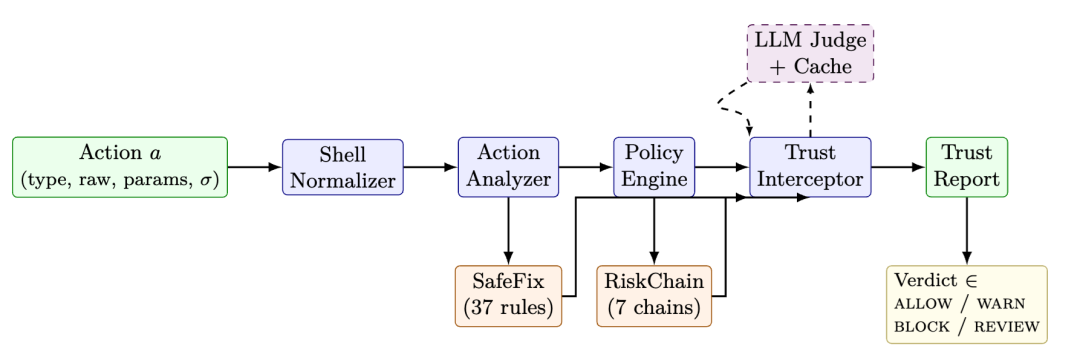

实验结果

价值与启发
局限性
写在最后
同专题推荐
查看专题AI Agent 的零信任框架:五大风险、三层架构与八阶段实施流程(Anthropic,2026.5)
2026 年 5 月,Anthropic 发布了一份面向企业 AI Agent 部署的安全白皮书:《Zero Trust for AI Agents》。
Agent IAM 系列(一):Agent 不是服务账号
这是「Agent IAM 系列」第一篇。本文讨论的是:为什么 Agent 不能再被当作普通服务账号,企业 IAM 正在进入自治身份治理时代。
【SoK】自迭代训练的"对齐衰减":当AI学会不再做我们想让它做的事
自迭代训练正成为大语言模型能力进化的核心范式。然而,当模型开始通过自我生成的数据或信号进行递归训练时,一种被研究者称为“对齐衰减”的深层风险浮出水面——模型不再向人类意图收敛,反而在迭代中逐渐偏离。