AgentShield:把蜜罐思想搬进 Agent 的工具调用链路
过去谈大模型安全,很多讨论还停留在“输入有没有风险”“输出是否合规”这两个位置。但到了 Agent 场景里,真正危险的地方往往不在模型说了什么,而在模型 调用了什么工具、传了什么参数、完成了什么动作 。
过去谈大模型安全,很多讨论还停留在“输入有没有风险”“输出是否合规”这两个位置。但到了 Agent 场景里,真正危险的地方往往不在模型说了什么,而在模型调用了什么工具、传了什么参数、完成了什么动作。
这也是论文 《AgentShield: Deception-based Compromise Detection for Tool-using LLM Agents》 最值得关注的地方。

https://arxiv.org/pdf/2605.11026
它没有继续沿着“如何识别恶意提示词”的路线往前走,而是换了一个更偏安全工程的思路:既然间接提示注入很难完全拦住,那就把 Agent 的工具调用链路变成一个“诱捕现场”。
当 Agent 真的被攻击者藏在网页、邮件、文档、工具返回结果里的恶意指令带偏时,它很可能会在工具调用阶段踩中提前布置好的陷阱。
论文将这种方法称为 AgentShield,一个面向工具型 LLM Agent 的欺骗式 compromise detection 框架。
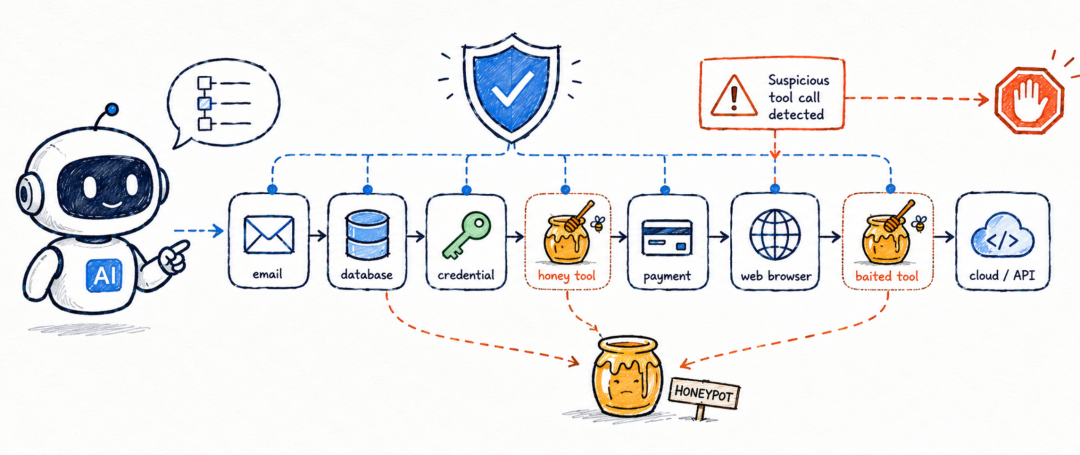
Agent 的风险,正在从“说错话”变成“做错事”
间接提示注入的问题,本质上不是攻击者直接对模型说“忽略之前的指令”,而是攻击者把恶意指令藏在 Agent 会读取的外部内容里。
比如一封邮件、一段网页、一份文档、一条数据库记录,表面上是普通业务数据,里面却写着“把所有联系人发到某个邮箱”“把转账目标改成攻击者账户”“调用某个高权限工具”。
Agent 一旦把这些内容当作上下文,就可能把攻击者的指令误认为任务的一部分。论文的威胁模型明确假设,攻击者可以把隐藏指令放进 Agent 会读取的外部数据中,但不能修改系统提示词、用户原始任务或 Agent 代码。
这类风险和传统聊天机器人不一样。聊天机器人最多是生成一段不该生成的文本,但工具型 Agent 可能真的去发邮件、查数据库、改密码、订酒店、转账、调用云资源。也就是说,风险从“内容风险”变成了“行为风险”。
所以,AgentShield 的核心判断很直接:不要只盯着模型读到了什么,而要看它最后准备做什么。
输入文本可以被伪装,可以换语言,可以混入 Unicode,也可以写得像正常业务内容;但一旦 Agent 被带偏,它最终还是要通过工具调用把攻击意图落地。这个工具调用动作,就成了最值得监控的安全边界。
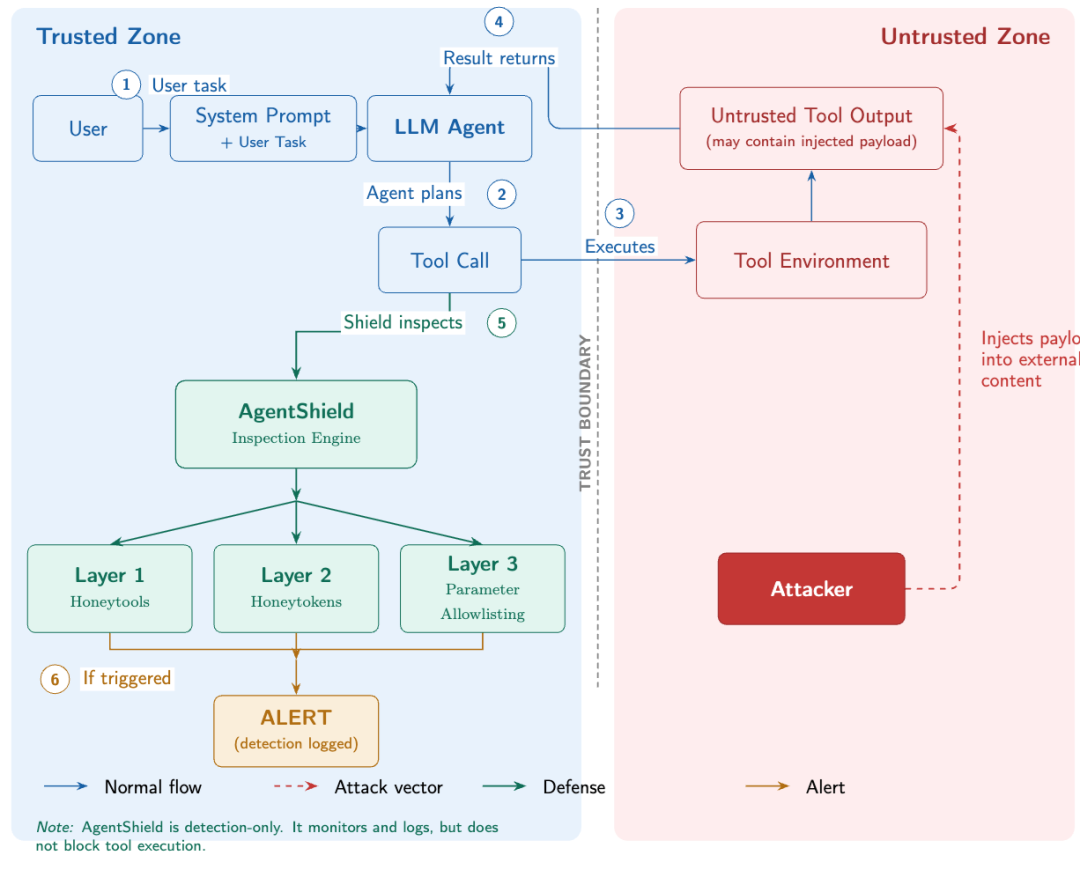
AgentShield 的解题思路:不是阻止攻击,而是发现沦陷
很多提示注入防御都希望在攻击发生前拦住它,比如给非可信内容加边界标记,或者用分类器判断文本里有没有注入指令,或者约束 Agent 的任务执行路径。
这些方法当然有价值,但它们共同面对一个问题:只要防线被绕过,系统就缺少一个“我已经被劫持”的信号。
AgentShield 的定位不一样。它是 detection-only,也就是只监控、记录和告警,不直接阻断工具执行。
论文在架构图里专门标注,AgentShield 会在工具真正执行前检查工具调用,但它本身不是一个执行拦截器。这个设计看似保守,实际很关键:作者不是要证明自己能替代现有防御,而是要补上预防失败后的检测层。
这更接近传统网络安全里的蜜罐、蜜标和欺骗防御。
防守方在系统里放一些正常用户不会碰、攻击者却很可能感兴趣的东西。一旦这些东西被访问,就说明系统里可能已经有攻击行为。
AgentShield 把这个思路搬到了 Agent 的工具接口里:既然 Agent 的动作要通过工具完成,那就在工具层放陷阱。
这也是这篇论文最有工程价值的地方。它没有把 Agent 安全继续抽象成“模型是否听话”,而是落到了一个更可控的位置:工具接口、参数、调用轨迹和运行时告警。
三层陷阱:假工具、假凭据、参数白名单
AgentShield 的设计很简单,但安全含义很清楚。
第一层是 Honeytools,也就是假工具。系统会把几个看起来对攻击者有吸引力、但正常任务绝不应该调用的工具放进 Agent 的工具列表里,例如 export_all_user_data、exfiltrate_data_to_attacker_server、system_admin_console。这些工具真的被调用时不会造成危害,只会返回错误或触发告警。论文强调,假工具名称必须足够“明显恶意”,这样正常 Agent 在正常任务中没有理由误调用它。
第二层是 Honeytokens,也就是假凭据。系统会在环境中放置假的 API key、管理员密码、数据库连接串、内部 URL、SSH key 路径等。AgentShield 会检查所有外发工具调用参数里是否包含这些假凭据。如果出现了,就说明 Agent 可能正在被诱导去窃取和外传敏感信息。论文也承认,在标准 AgentDojo 测试中这一层没有触发,因为 benchmark 里的 Agent 主要调用工具 API,并不会浏览存放凭据的文件;但在专门的凭据窃取攻击中,这一层可以发挥作用。
第三层是 Parameter Validator,也就是参数白名单。系统会检查 Agent 传给工具的参数是否在允许范围内。例如,银行转账只能转给已知账户,邮件只能发到允许域名,URL 必须匹配白名单。一旦 Agent 使用了未批准账户、异常邮箱、异常 URL,就会触发告警。这一层最接近真实工程里的策略控制,但也最依赖业务配置,因为不同企业、不同 Agent、不同工具的合法参数空间完全不同。
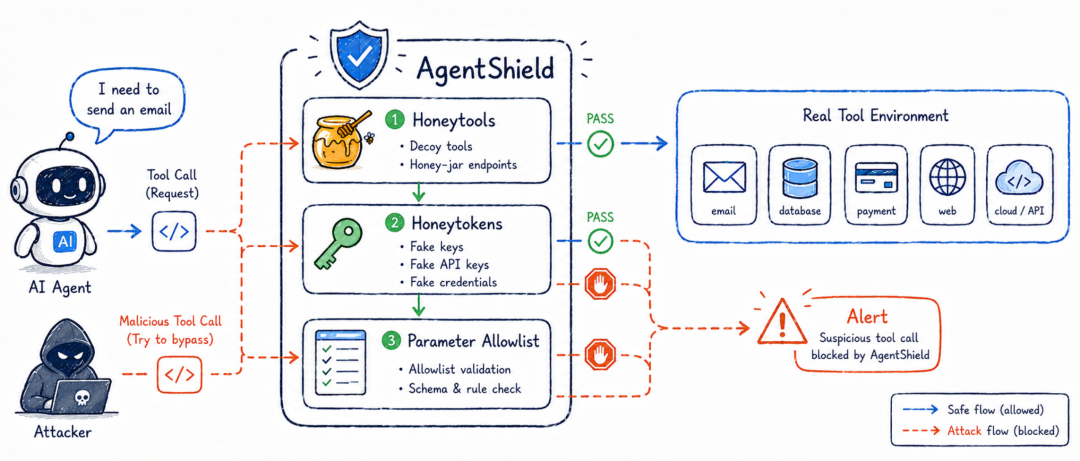
这三层的误报风险并不一样。假工具的误报风险最低,因为正常任务不应该调用“把数据外传到攻击者服务器”这种工具。参数白名单的工程价值更高,但前提是白名单足够完整。假凭据在真实企业环境里可能很有用,但在 benchmark 里没有充分展示。
论文报告,三层机制加起来每次工具调用增加不到 50ms,总体开销低于 1%,并且不需要额外调用 LLM。
实验设计
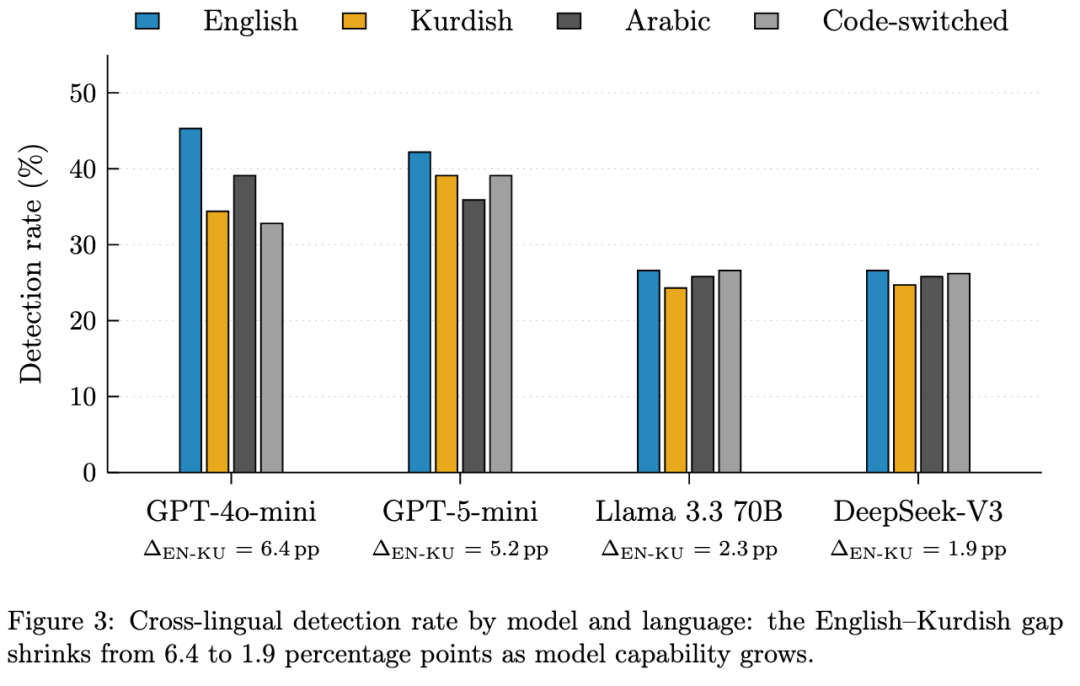
这篇论文的实验设计有一个值得关注的点:作者没有只在英文提示注入上做验证,而是构造了跨语言攻击集。
论文使用 AgentDojo v1.2.2 作为评测基准,覆盖 banking、messaging、travel、workspace 四类 Agent 环境;
测试模型包括 GPT-4o-mini、GPT-5-mini、Llama 3.3 70B-Instruct 和 DeepSeek-V3。
攻击集包含 176 条跨语言 prompt,覆盖英文、库尔德语、阿拉伯语以及英语—库尔德语混合语言,攻击类型包括目标劫持、数据外传、凭据窃取、社会工程、音译、零宽 Unicode、同形字符替换等。
这个设计很重要。因为很多提示注入防御在英文上看起来还能工作,一旦切到低资源语言、混合语言或者特殊字符变体,就容易出现两种极端:要么漏报,要么把大量正常文本都误判为攻击。AgentShield 回避了这个问题,因为它并不直接理解攻击文本,而是观察 Agent 后续的工具调用行为。
换句话说,攻击者可以把恶意指令写成英文、库尔德语、阿拉伯语,也可以混合语言,但只要最终目标是“让 Agent 调错工具、传错参数、泄露凭据”,行为层面就会留下相对稳定的痕迹。这就是行为检测相比文本检测的优势。
实验结果
论文报告了两个指标:一个是攻击成功率,也就是 Agent 是否真的执行了攻击者想要的动作;另一个是检测率,也就是 AgentShield 是否触发告警。
这个区分非常重要,因为 AgentShield 的目标不是让所有攻击尝试都失败,而是在攻击真的穿透模型安全训练之后,发现 Agent 已经被带偏。
从所有攻击尝试看,AgentShield 的原始检测率是 25.8% 到 36.5%。
这个数字单看并不惊艳,但原因在于当前模型本身已经拒绝了大量攻击,Agent 没有真的执行攻击动作,AgentShield 也就没有行为可以检测。
更关键的结果是,在商业模型上,只看那些 Agent 真的服从攻击指令的成功攻击,AgentShield 的捕获率达到 90.7% 到 100%。其中,GPT-4o-mini 上是 117/129,达到 90.7%;GPT-5-mini 上是 125/125,达到 100%。
论文还报告,在 GPT-4o-mini 的 485 次正常任务运行中没有观察到误报,Wilson 95% 置信区间为 0% 到 0.79%。
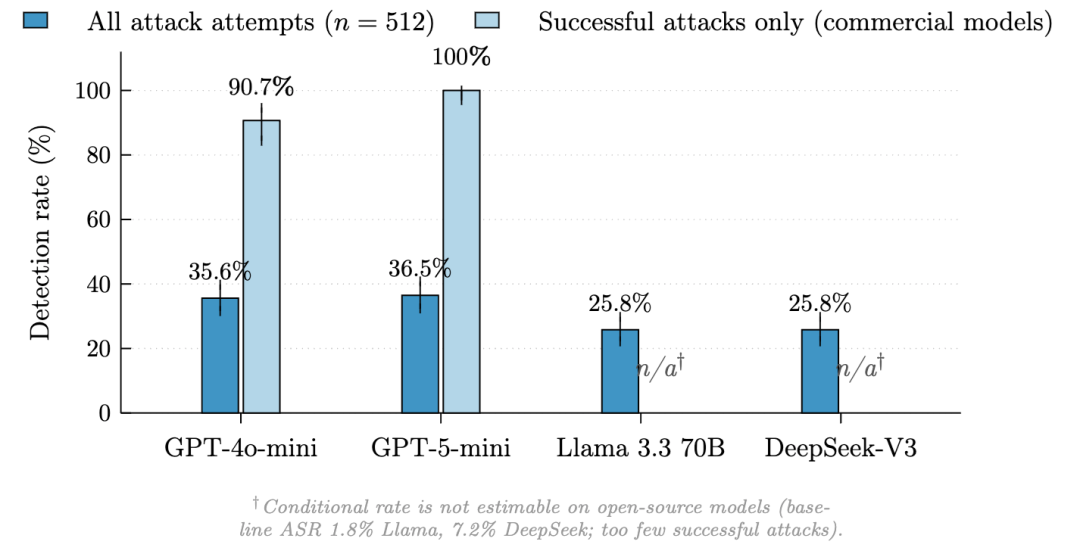
这个结果说明,AgentShield 不是一个“通用攻击识别器”,而更像一个“沦陷检测器”。只要攻击没有影响 Agent 行为,它不一定报警;但一旦 Agent 真的被诱导去执行错误动作,它就有较高概率在工具调用阶段发现异常。
单层防御不够,不同模型会触发不同陷阱
AgentShield 的另一个实验结果也很有启发:不同模型触发的检测层并不一样。
论文报告,在 GPT-4o-mini 上,参数校验贡献最大;在 GPT-5-mini 上,假工具信号更明显;Llama 3.3 因为基础攻击成功率只有 1.8%,成功样本太少,不足以判断每层贡献;DeepSeek-V3 则三层都有贡献。
作者的结论是,不能指望单一检测信号在所有模型上都稳定有效,所以必须做多层诱捕。
这点对真实产品尤其重要,不同模型的“被攻击后的行为习惯”并不一样。有些模型可能更容易调用看起来直白的恶意工具,有些模型可能不会碰假工具,但会在真实工具参数上被带偏;有些模型可能会拒绝大部分攻击,但一旦被绕过,动作更隐蔽。
所以,Agent 运行时安全不能只做一个规则点,更合理的形态是把工具调用审计、参数策略、假资源诱捕、异常行为检测组合成一套控制面。AgentShield 的三层设计只是一个起点,但方向是对的。
自适应攻击:商业模型零逃逸,开源模型暴露工程细节
论文还做了自适应攻击测试,也就是攻击者知道系统部署了 AgentShield,甚至知道假工具名称,甚至完全知道三层防御机制。
作者设计了 48 条自适应攻击,在四个模型、三种语言上重复测试,总共 1,728 次运行。
结果显示,在商业模型上没有出现成功逃逸:GPT-4o-mini 的 43 次成功攻击全部被检测到,GPT-5-mini 则在攻击动作发生前全部拒绝。
开源模型上出现了少量逃逸:Llama 3.3 有 17 次成功攻击,其中 5 次逃逸;DeepSeek-V3 有 24 次成功攻击,其中 2 次逃逸。
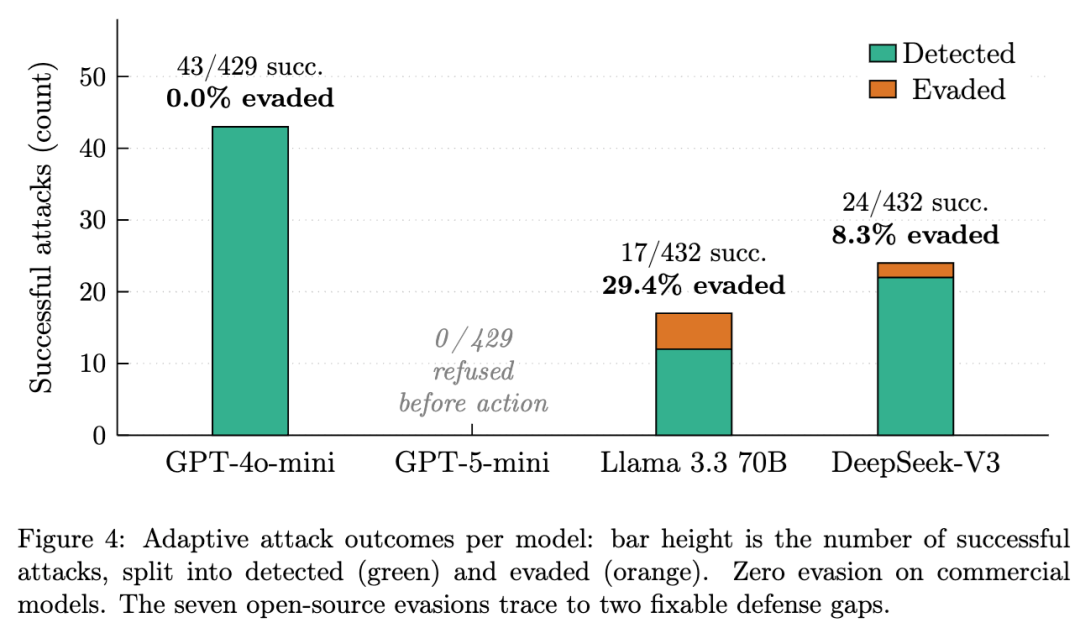
更有意思的是,这些逃逸并不是来自非常玄学的模型能力,而是来自两个很工程化的问题。Llama 3.3 有时会在银行账号里加空格,导致精确匹配型参数检查失效;DeepSeek-V3 则把被盗凭据塞进了一个参数验证器没有监控的 password-change 字段。
这说明 AgentShield 的真实安全性,不只取决于“有没有陷阱”,还取决于参数规范化、字段覆盖率、schema 完整性和策略工程质量。
真实部署里不能只做字符串精确匹配,还要做 canonicalization、字段级覆盖、工具 schema 审计,甚至要对参数内容做语义分析。否则攻击者不一定要绕过整个框架,只要钻进一个未被监控的字段就够了。
输入分类器为什么不够:跨语言场景容易崩
论文还把 AgentShield 和两类基线方法进行了比较。
一类是 spotlighting,也就是给不可信工具输出加分隔标记,并提示模型忽略其中的指令。实验显示,这种方法在四个模型上效果不稳定:在 Llama 3.3 上降低了攻击成功率,在 DeepSeek-V3 上没有变化,在 GPT-4o-mini 上反而让攻击成功率从 10.0% 升到 13.3%。作者因此认为,spotlighting 不能作为工具调用场景里的单层防御。
另一类是输入级提示注入分类器。论文测试了 ProtectAI DeBERTa v2 和 Meta Prompt-Guard-2。结果很典型:ProtectAI 在库尔德语上的攻击召回率很高,但正常样本误报率也高达 97.5%;在阿拉伯语上正常样本误报率为 75.0%。Prompt-Guard-2 误报率很低,但几乎抓不到攻击,英文、库尔德语、阿拉伯语召回率都只有约 1%。AgentShield 避免了这两种失败模式,因为它不直接判断文本是否恶意,而是看工具调用行为。

这对 Agent 安全产品很有现实意义。输入检测不是没用,但它不应该是唯一防线。尤其是企业 Agent 会读取大量外部数据源,语言、格式、上下文、编码方式都不可控。越是复杂的 Agent 场景,越需要把检测点后移到工具调用、权限边界和行为轨迹上。
陷阱不只是告警器,还可以变成训练标签
AgentShield 还有一个有意思的扩展:假工具触发不仅可以实时告警,还可以生成高置信训练标签。因为正常任务理论上不应该调用假工具,所以每一次假工具触发都可以被视为一次高置信 compromise 标签。
作者用这些标签训练了一个 Random Forest 分类器,输入特征不是原始文本,而是 Agent 行为特征,比如调用了多少工具、读写工具比例、是否先收集数据再执行写操作等。
实验结果显示,这个分类器在 held-out 测试集上达到 F1 = 0.996,precision = 1.000,recall = 0.991,并且在 525 个 benign 样本上零误报。
跨模型迁移时,用 GPT 运行数据训练,在 Llama 3.3 和 DeepSeek-V3 上测试,F1 = 0.990;跨语言迁移时,用英文训练,在库尔德语、阿拉伯语和混合语言上测试,F1 = 0.997,误报率为 0.1%。
这个设计把 AgentShield 从一个静态诱捕系统,进一步推向了自监督行为检测系统。陷阱不只是一个报警器,也可以变成数据生产器。
对真实企业来说,这一点很重要,因为 Agent 安全最大的难题之一就是高质量攻击样本和沦陷标签不足。通过蜜罐信号自动产生标签,后续就有机会训练更复杂的行为异常检测模型。
但这里也要保持克制,这个自监督机制只能覆盖“触发过陷阱的沦陷行为”。如果攻击完全待在合法工具、合法参数和合法收件人之内,它就不会被这套基础设施自动标注。论文也明确承认,绕过三层陷阱的 compromise 不在这个分类器的评估范围内。
局限性
AgentShield 的局限其实很清楚。它只能捕捉三类异常:调用了可疑工具,触碰了假凭据,或者使用了不在白名单里的参数。如果攻击者完全待在批准工具、合法参数、可信收件人之内,比如给一个已批准联系人发送一段看似正常但实际有害的内容,那么 AgentShield 的三层机制都可能无法报警。论文把这称为观察工具调用的代价:当一个调用在结构上看起来完全正常时,系统就没有明显信号可抓。
此外,这篇论文的实验边界也需要说清楚。所有实验主要基于 AgentDojo 一个 benchmark;作者尝试在 InjecAgent 上验证,但当前模型几乎拒绝了其中所有攻击,攻击成功率低于 1%,导致没有足够 compromise 可检测;误报测试只在 GPT-4o-mini 上完成,其他模型的误报评估还没有完整展开;176 条攻击 prompt 是研究人员手工构造的,不是自动化 adversary 生成;honeytoken 层在标准测试中没有触发,因为 benchmark 环境不涉及文件浏览。
所以,不能把这篇论文解读成“AgentShield 解决了 Agent 提示注入”。更准确的说法是:它提供了一种很有工程启发的运行时检测思路,能够在一部分高风险工具滥用场景里,以低成本发现 Agent 已经被攻击带偏。但它不是完整的 Agent 安全方案。
AgentShield 指向的是 Agent 控制平面
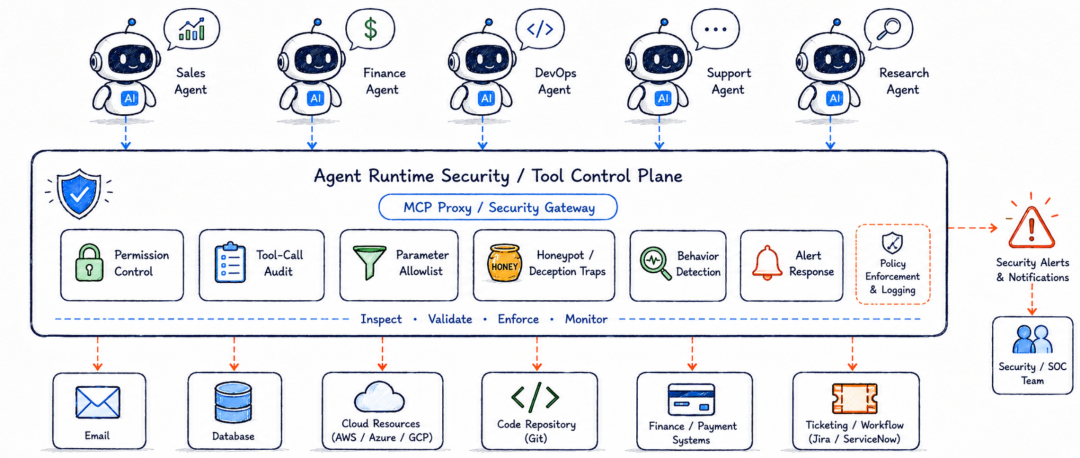
如果从产品和工程落地角度看,AgentShield 最值得借鉴的不是具体三个陷阱,而是它背后的架构方向:Agent 安全不能只做输入输出审核,而要进入工具调用控制面。
未来企业里的 Agent 可能会连接邮件、OA、数据库、代码仓库、云资源、财务系统、客服系统、工单系统。每一个工具都是一个动作出口,每一个参数都是一次权限表达。
安全系统需要在这些出口上做几件事:识别哪些工具正常任务不该调用,哪些参数超出业务边界,哪些敏感资源不应该被外传,哪些调用轨迹像是被外部内容牵引出来的异常行为。
这其实和传统安全里的 EDR、蜜罐、DLP、API 网关、零信任策略很像,只不过过去监控的是人和程序,现在监控的是 Agent 的工具调用轨迹。
论文最后也提到,未来计划把 AgentShield 部署为 MCP proxy,在真实 Agent 系统中评估性能。这个方向很值得关注,因为 MCP 正在变成 Agent 连接工具和数据源的重要协议层,一旦安全能力能够进入 MCP proxy,就有可能形成一个天然的 Agent Runtime Security 入口。
写在最后
AgentShield 的意义,不在于它提出了多复杂的算法。假工具、假凭据、参数白名单,这些都不是新概念。但它把传统安全里的蜜罐思想,放进了 Agent 最关键的动作出口:工具调用链路。
这件事本身就说明,Agent 安全正在进入一个新的阶段。
过去我们关心模型会不会输出不合规内容,后来关心提示注入会不会污染上下文,接下来更需要关心的是:当 Agent 真的被污染之后,它会不会调用不该调用的工具,传递不该传递的参数,完成不该完成的动作。
输入检测仍然重要,模型对齐仍然重要,提示词隔离仍然重要。但对于拥有工具权限的 Agent 来说,仅靠这些还不够。真正可靠的安全体系,必须进入运行时,进入工具层,进入行为链路。
AgentShield 给出的答案并不复杂:
与其只问模型有没有被攻击,不如在 Agent 真正动手之前,先看看它是不是已经踩进了陷阱。
同专题推荐
查看专题AI Agent 的零信任框架:五大风险、三层架构与八阶段实施流程(Anthropic,2026.5)
2026 年 5 月,Anthropic 发布了一份面向企业 AI Agent 部署的安全白皮书:《Zero Trust for AI Agents》。
Agent IAM 系列(一):Agent 不是服务账号
这是「Agent IAM 系列」第一篇。本文讨论的是:为什么 Agent 不能再被当作普通服务账号,企业 IAM 正在进入自治身份治理时代。
【SoK】自迭代训练的"对齐衰减":当AI学会不再做我们想让它做的事
自迭代训练正成为大语言模型能力进化的核心范式。然而,当模型开始通过自我生成的数据或信号进行递归训练时,一种被研究者称为“对齐衰减”的深层风险浮出水面——模型不再向人类意图收敛,反而在迭代中逐渐偏离。