AgentBound:给 MCP Server 套上权限边界
MCP 解决了 Agent 接入工具和资源的标准化问题,但安全机制没有同步跟上。 MCP 规范定义了 Host、Client、Server 之间的角色和消息交互,但在实际落地中,很多安全责任被交给应用开发者和宿主应用自行处理。 结果就是,MCP Server 往往以“默认可信”的方式运行。 这和移动…
MCP 解决了 Agent 接入工具和资源的标准化问题,但安全机制没有同步跟上。
MCP 规范定义了 Host、Client、Server 之间的角色和消息交互,但在实际落地中,很多安全责任被交给应用开发者和宿主应用自行处理。
结果就是,MCP Server 往往以“默认可信”的方式运行。
这和移动应用生态形成了鲜明对比,Android App 想访问摄像头、麦克风、位置、存储,需要在 Manifest 里声明权限,并在运行时经过系统控制。
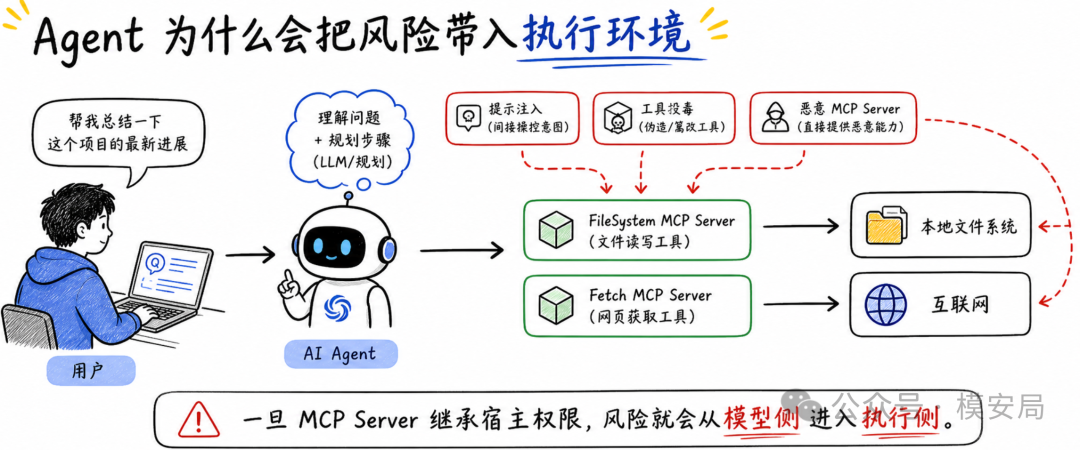
MCP Server 现在缺少类似机制,一个工具包只要被 Agent 接入,就可能获得远超任务所需的系统权限。
一旦 MCP Server 被污染、被诱导,或者本身就是恶意的,Agent 安全就不再只是“模型有没有判断对”的问题,而是“工具有没有能力越权执行”的问题。
论文 AgentBound: Securing Execution Boundaries of AI Agents 解决的正是这个问题。

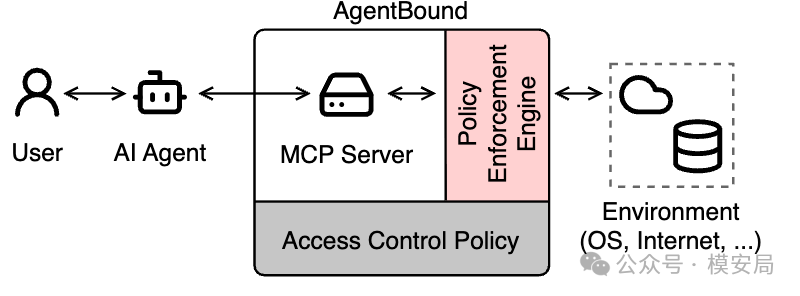
它提出的思路很直接:不要默认信任 MCP Server,而是像 Android App 一样,让 MCP Server 先声明自己需要什么权限,再由运行时沙箱严格执行这些权限边界。
换句话说,即使模型被提示注入诱导了,即使 MCP Server 想越权读文件、外传数据、执行命令,它也只能在被授权的边界里行动。
论文称 AgentBound 是面向 MCP Server 的第一个访问控制框架,由 声明式权限机制 和 策略执行引擎 两部分组成。
AgentBound 的核心思路:先声明权限,再强制执行
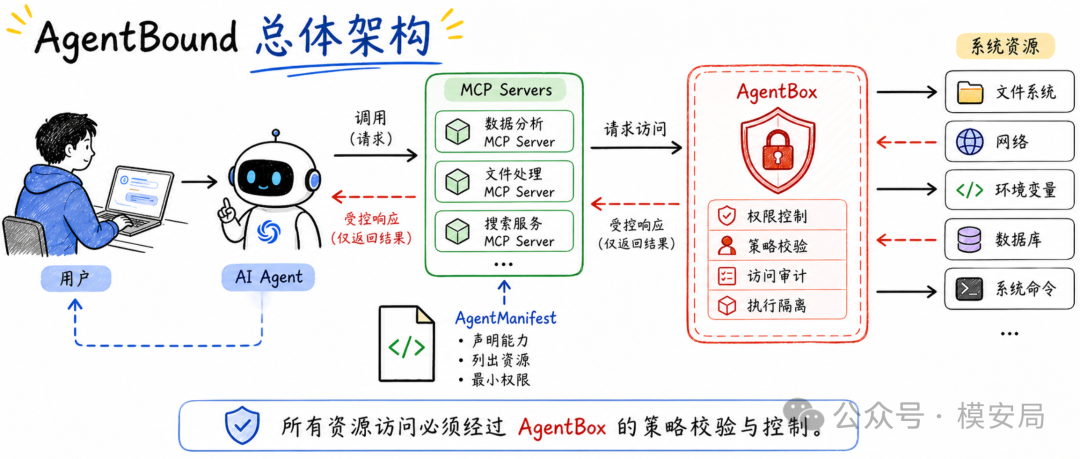
AgentBound 的设计可以拆成两个关键词: AgentManifest 和 AgentBox 。
AgentManifest 负责声明 MCP Server 需要什么能力,它类似 Android App Manifest,是一个 权限清单 。
比如一个文件系统 MCP Server 可以声明自己需要读取文件和写入文件,一个网页抓取 MCP Server 可以声明自己需要出站网络访问。
论文给出的能力体系覆盖五类资源,包括 文件系统、系统交互、网络访问、外设访问 以及 其他能力 。具体能力包括读写删除文件、读写环境变量、执行系统命令、进程管理、出站网络、入站网络、摄像头、麦克风、屏幕捕获、位置、通知、剪贴板读写等。
AgentBox 则负责把这些权限真的执行起来,它是一个 策略执行引擎 ,也可以理解成 MCP Server 的 运行时沙箱 。
AgentBox 会把 MCP Server 放进受控环境里运行,根据 AgentManifest 限制它能访问哪些文件、能读取哪些环境变量、能连接哪些域名。
论文中的实现主要基于 Docker 容器,文件权限通过挂载控制,环境变量通过白名单控制,网络访问通过 iptables 控制。
这套设计的关键点在于,它承认模型和工具链都可能出错。安全边界不能只放在模型输出之前,也不能只靠提示词和规则去判断“这次调用是不是危险”。
AgentBound 的做法是在 MCP Server 和系统资源之间加一道硬边界,只要 Manifest 没有授权,MCP Server 就不应该读到相应文件;只要网络域名不在允许范围内,MCP Server 就不应该连出去。
AgentManifest:把 MCP Server 的能力显性化
AgentManifest 的价值不只在于“声明权限”,更在于把 MCP Server 的能力 显性化 。
现在很多 Agent 平台接入 MCP Server 时,用户看到的往往是工具名称、工具描述、README 文档,最多再加上一些安装配置。
至于这个 Server 运行后到底会不会读环境变量、会不会写文件、会不会访问外网、会不会执行系统命令,用户和平台很难在接入前形成稳定认知。
AgentManifest 试图把这件事标准化。
一个 MCP Server 如果需要读文件,就声明 mcp.ac.filesystem.read ;如果需要写文件,就声明 mcp.ac.filesystem.write ;如果需要出站联网,就声明 mcp.ac.network.client ;如果需要执行命令,就声明 mcp.ac.system.exec 。
论文中的能力词表不是简单照搬 Android,而是结合 Agent/MCP 在桌面环境中的实际资源需求做了裁剪和合并,最终形成 平台无关的 MCP Server 能力体系 。
不过,Manifest 里的能力只是第一层,真正运行时,还需要把通用能力细化成具体授权。比如, filesystem.read 不能直接等价于“可以读整个磁盘”,而应该细化成“只能读某个项目目录”; network.client 也不能直接等价于“可以访问整个互联网”,而应该细化成“只能访问某些域名或 URL”。
论文特别强调,AgentBox 会在运行时要求把这些通用能力细化成具体权限。
这一点对企业 Agent 平台非常重要,因为真正危险的权限不是“有没有读文件能力”,而是“读哪里的文件”;不是“有没有联网能力”,而是“能连到哪里”;不是“有没有环境变量读取能力”,而是“能不能读到 API_KEY、TOKEN、数据库密码”。
AgentManifest 解决的是能力显性化,AgentBox 进一步解决的是权限边界强制执行。
AgentBox:即使模型被骗,工具也不能越界
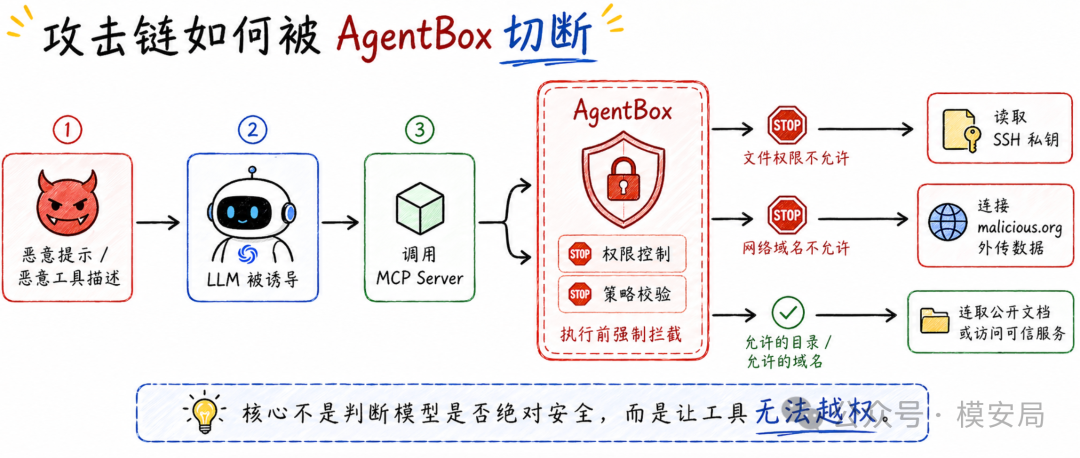
AgentBound 的防御逻辑,最适合用一句话理解: 模型可以犯错,但 MCP Server 不能越权。
比如用户让 Agent 为一个代码项目生成文档,Agent 需要一个 FileSystem MCP Server 读取源码目录,也需要一个 Fetch MCP Server 从网上抓取 API 文档。
如果没有 AgentBound,这两个 MCP Server 很可能都在本机上以较高权限运行。一旦 Fetch Server 被恶意修改,它可能访问不该访问的域名;一旦 FileSystem Server 被诱导,它可能读取项目目录之外的 SSH 私钥或其他敏感文件。
在 AgentBound 的设计里,FileSystem MCP Server 只能读写被授权的目录,Fetch MCP Server 只能访问被授权的域名。
即使模型被提示注入诱导去“读取私钥并发送到恶意网站”,这条攻击链也会在系统资源访问环节被切断。文件读不到,网络连不出去,攻击就无法完成。
这也是 AgentBound 和很多提示注入检测方案的差异,提示注入检测是在判断“这句话是不是危险”,AgentBound 处理的是“这个进程到底有没有权限做这件事”。前者依赖模型理解和规则判断,后者依赖操作系统级隔离。对 Agent 这类会真实执行动作的系统来说,后者更接近基础安全底座。
自动生成 Manifest:用大模型给 MCP Server 做权限分析
AgentManifest 的现实难点在于,不能指望所有 MCP Server 开发者一开始就主动、准确、规范地写权限清单。
为了解决这个问题,论文提出了 AgentManifestGen ,用 LLM 自动分析 MCP Server 的源码和文档,生成初始 Manifest。
它的流程分两步:
第一步让多个 intermediate agent 分析代码和文档,分别生成中间 Manifest,并为每个权限给出理由;
第二步由 consolidator agent 汇总这些结果,生成最终 Manifest。
论文实现中使用 gpt-5-mini 生成 5 个中间 Manifest,再用带 reasoning 的 gpt-5 模型做聚合。作者收集了 GitHub 上星标最高的 300 个 MCP Server,其中 296 个成功下载,整个 Manifest 生成实验的 API 成本为 99.25 美元。
实验结果很有意思,296 个 MCP Server 中,最常见的能力是出站网络访问、环境变量读取、文件读取和文件写入。
具体看, network.client 出现比例为 83.1%, system.env.read 为 79.6%, filesystem.read 为 74.1%, filesystem.write 为 49.3%。
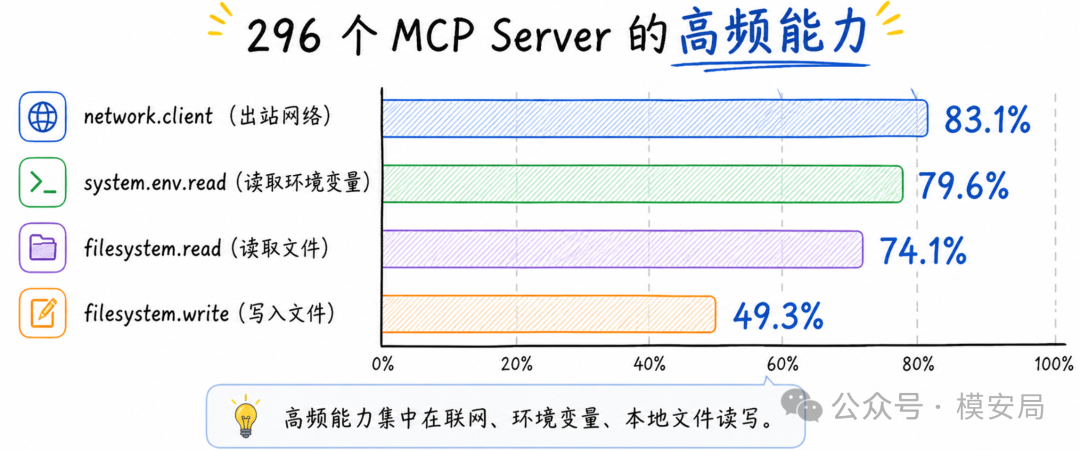
这说明今天大量 MCP Server 的确在处理外网访问、配置密钥、本地文件读写,而这些恰好都是 Agent 安全里最容易出事的资源入口。
作者还做了两类验证:
一类是把 96 个自动生成的 Manifest 提交给对应 GitHub 仓库维护者审核,开发者反馈中确认能力词表覆盖了真实 MCP Server 所需能力,自动生成 Manifest 的正确率为 80.9%,召回率达到 100%。
另一类是对 48 个 MCP Server 做人工 Manifest 对比,自动生成结果与人工结果的匹配准确率达到 96.5%,精确率 0.94,召回率 0.96。
这说明,LLM 本身也可以成为 MCP 权限治理的辅助工具。它不一定能替代人工审核,但可以承担“初筛”和“权限草案生成”的工作。对平台来说,这很适合做成 MCP Server 上架前的自动安全体检:先扫描源码和 README,生成权限清单,再由开发者或平台安全团队确认。
安全实验:能挡越权资源访问,挡不住语义滥用
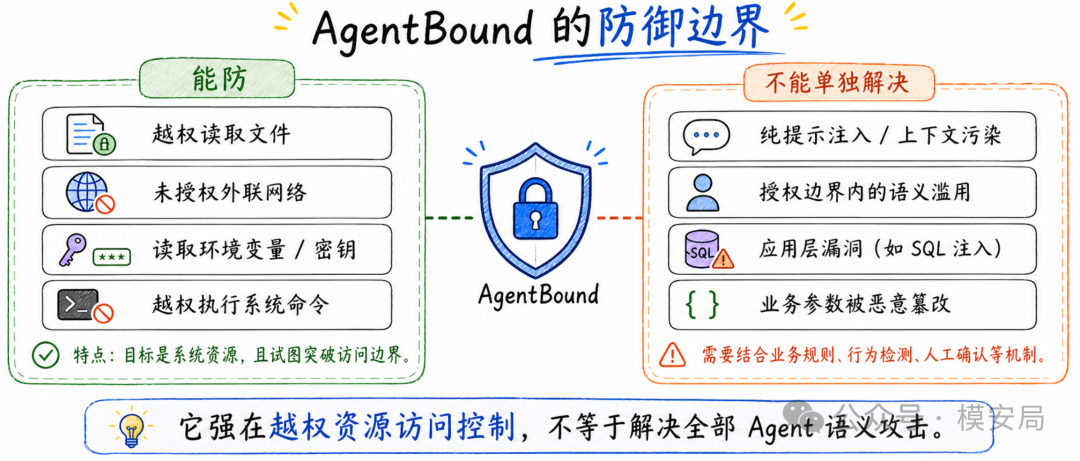
AgentBound 的安全边界划得很诚实,它关注的是 system-resources-targeting attacks ,也就是那些最终需要 MCP Server 访问或影响系统资源的攻击。
比如读敏感文件、外联恶意域名、修改本地配置、执行 shell 命令。
对于只改变模型推理过程或输出内容、但不触碰系统资源的攻击,论文明确把它放在范围之外。
安全实验分成几组:
第一组是作者手工构造的恶意 MCP Server,用来窃取 SSH 私钥;
第二组是公开数据集中的恶意 MCP Server,包括 Google Maps Server 修改 API Host、puppet attack 修改加密货币交易行为、天气 Server 动态改 API Host、Wechat MCP SQL 注入;
第三组是 10 个 MCP 安全挑战样本。
实验结论和威胁模型高度一致,只要攻击需要突破权限边界访问系统资源,AgentBox 就能发挥作用。
比如 Google Maps MCP Server 把 API Host 改成恶意地址后,由于出站网络只允许访问合法 host,连接会被阻断。
论文总结说,AgentBox 能阻止所有目标是系统资源、且试图突破访问控制边界的恶意攻击,共 9 个。
但 AgentBound 也挡不住两类问题:
第一类是纯模型侧攻击,比如攻击只是在 LLM 上下文里注入提示,并没有让 MCP Server 越权访问系统资源。
第二类是授权边界内的业务语义滥用,比如 puppet attack 诱导模型把加密货币转账重定向到一个私有代理,如果这个请求仍然落在被允许的工具或网络范围内,AgentBox 无法判断“这个参数在业务语义上是否恶意”。
SQL 注入也是类似问题,如果数据库访问本来就是该 MCP Server 的合法能力,那么访问控制机制本身无法修复应用层漏洞。

这其实给 Agent 安全架构划出了一条清晰分工:AgentBound 负责系统资源边界,能解决越权访问和数据外传这类问题;业务语义层面的滥用,还需要交易确认、参数校验、异常行为检测、人工审批和应用层安全机制来补齐。
性能开销:主要在启动阶段,运行时影响很小
安全方案能不能落地,性能是绕不开的问题,AgentBound 的实验结果相对乐观。
论文在 macOS 和 Debian 上分别测试了 MCP Server 的启动延迟和运行时操作开销。
启动阶段,由于容器初始化会带来额外成本,macOS 上沙箱化启动大约增加 150 到 300 毫秒,Debian 上部分 Server 最高增加到 400 毫秒左右。这个开销主要出现在 MCP Server 启动时。
运行时开销则很低,论文测试了读取环境变量、读文件、写文件、fetch URL 四类常见操作,结果显示沙箱在 macOS 上平均增加 0.6 ms,在 Debian 上平均增加 0.29 ms。
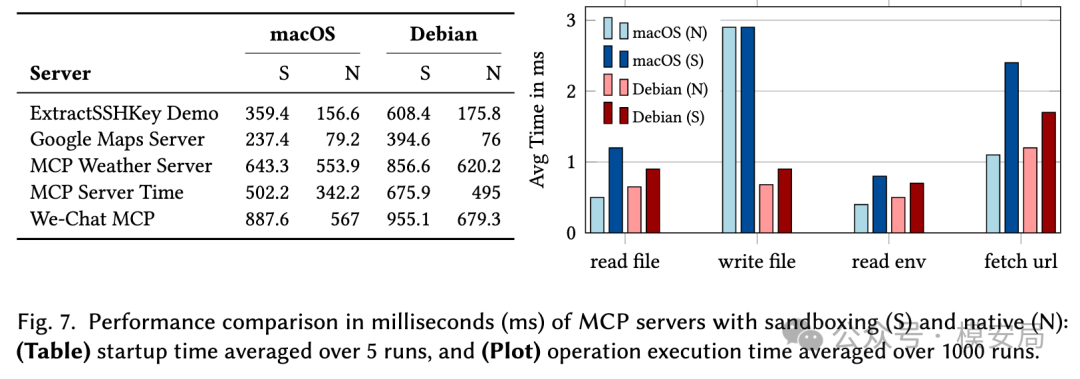
作者认为,MCP Server 通常会在一个 Agent 会话中启动一次并复用多次,而 LLM 推理和多轮工具调用本身耗时远高于这个级别,因此 AgentBox 的运行时开销基本可以接受。
这对工程落地很关键,很多 Agent 安全方案最大的问题是“理论上安全,实际用不起”。
AgentBound 的优势在于,它不要求改 MCP Server 代码,也没有给每次工具调用增加很高成本。
真正困难的地方,更多会出现在权限声明规范、用户授权体验、平台治理流程和不同运行环境适配上。
工业界真正需要的是 MCP 权限治理层
如果把 AgentBound 放到工业界看,它最有价值的地方不只是“用 Docker 跑 MCP Server”,而是提出了一套 MCP 权限治理范式。
未来企业接入 MCP Server,一定会遇到几个很现实的问题:
哪些 MCP Server 可以进入企业 Agent 平台?
它们需要哪些权限?
能不能读本地文件?
能不能读环境变量?
能不能连接公网?
能不能执行 shell?
如果 MCP Server 更新了版本,权限有没有变化?
如果某个 Server 从只读文件升级成能写文件,平台是否需要重新审批?
AgentManifest 可以成为权限基线,它让每个 MCP Server 的能力变成显式声明,方便上架审核、用户授权、版本变更对比和安全审计。
AgentBox 则把这个权限基线变成可执行边界,防止 Server 在运行时做出超出声明范围的行为。
进一步看,这套机制完全可以和现有安全产品能力结合起来。
MCP Server 上架前,可以做源码扫描、依赖扫描、恶意代码检测和 Manifest 自动生成;
运行时,可以通过沙箱限制文件、网络、环境变量和命令执行;
调用链路中,可以叠加工具调用审计、敏感数据检测、异常行为识别;
涉及转账、删库、发邮件、改配置这类高风险动作时,还可以引入业务规则校验和人工确认。
这才是比较完整的 Agent 安全工程闭环。
模型安全负责降低被诱导概率,权限边界负责限制越权能力,行为监控负责发现异常路径,业务审批负责兜住高风险动作。
AgentBound 解决的是其中非常底层、也非常关键的一环。
局限性
首先,它解决不了授权边界内的语义滥用 。一个转账工具本来就有网络访问权限,一个数据库工具本来就有数据库访问权限,一个邮件工具本来就可以发邮件。如果攻击者只是诱导模型把参数填错、把收件人换掉、把交易地址改掉,只靠文件和网络权限控制很难判断这件事是否恶意。论文也把这种问题称为访问控制里的 semantic gap 或 unauthorized misuse。
其次,权限粒度还需要继续细化 。论文中的能力词表已经覆盖 MCP Server 的主要资源类型,但企业真实场景往往需要更细的约束。例如只能读取某个目录下的 Markdown 文件,只能访问某个 API 的 GET 接口,只能读取指定环境变量,不能读取全部 env。这些细粒度约束如果没有设计好,Manifest 可能会从“最小权限”退化成“宽泛授权”。
再次,网络控制会遇到现实复杂性。 论文实现中通过域名解析和 iptables 做出站网络 allowlist,这是一个轻量有效的起点,但生产环境里还会遇到 CDN、多 IP、短 TTL、重定向、代理、API 网关、私有网络等问题。真正产品化时,可能需要 DNS 策略、HTTP 代理、证书校验、出站内容风控一起配合。
最后,AgentBox 的隔离基础本身也构成可信计算基 。论文实现依赖 Docker、Linux namespaces、cgroups、iptables 以及 Python/Node.js 运行时。如果底层容器或内核隔离机制存在漏洞,仍然可能被绕过。企业级部署中,可以考虑进一步引入 gVisor、Kata Containers、Firecracker、seccomp、AppArmor、SELinux 或 eBPF 网络策略,形成更强的纵深防御。
写在最后
AgentBound 最重要的启发是:Agent 安全不能只停留在模型层。
当 Agent 只能聊天时,安全重点自然是输出内容。当 Agent 开始调用工具、读写文件、访问网络、操作数据库时,安全边界就必须下沉到执行环境。
模型可以被诱导,工具描述可以被污染,MCP Server 可以有漏洞,供应链也可能被攻击。
真正可靠的系统不能假设每一环都永远可信,而应该让每一环都只能在被授权的范围内行动。
所以,AgentBound 的意义不在于它已经解决了所有 Agent 安全问题,而在于它给 MCP 生态补上了一块基础拼图: 权限声明、运行时沙箱、最小权限和可审计边界 。
未来成熟的 Agent 安全架构,大概率会沿着这条路继续演进。
MCP Server 上架前需要权限分析,运行时需要沙箱隔离,调用过程中需要行为监控,高风险动作需要业务审批。只有把这些机制组合起来,Agent 才能从“能调用工具”走向“可控地调用工具”。
同专题推荐
查看专题LASM:Agent 安全的七层攻击面
论文 LASM 提出七层攻击面模型与四类时间性分类,重构 Agent 安全的分析框架:从模型层、认知层、记忆层、工具执行层、多 Agent 协同层、供应链层到治理层,揭示 Agent 安全本质是分布式系统安全问题
当 Mythos 成为对手:高能力 AI 的安全边界正在失效
这两天,一篇题为 《When the Agent Is the Adversary》 的论文在安全圈引发了不小关注。它讨论的不是传统意义上的提示注入,也不是常见的越狱绕过,而是一个更让人不安的问题:当高能力 Agent 不再只是“被保护对象”,而开始成为“主动对手”时,我们今天熟悉的那些安全边界,还…
AVISE:把大模型红队测试做成自动化安全评测流水线
常见的大模型安全评测,更像是一种“项目制”的工作:安全团队手工准备一批攻击样本,跑一轮测试,整理几张截图,再给出一份结论。