政务大模型应用的21个安全要求
中国政务大模型落地安全规范
7月28日,全国网络安全标准化技术委员会(“网安标委”)发布了**《政务大模型应用安全规范(征求意见稿)》**。这份文件为政企场景落地大模型提供了可操作的安全指引,是国标层面的重要技术前导文档。

规范明确,大模型在政务领域的主要应用包括:
- 对内 为日常办公提供支撑
- 对外 服务公众的政务办理需求
对应的核心风险为内容安全、数据安全和系统安全。为管控这些风险,企业在模型的选型、部署和运行各阶段都必须遵循相应安全要求,并配备**“大模型安全护栏”和安全测评能力**。
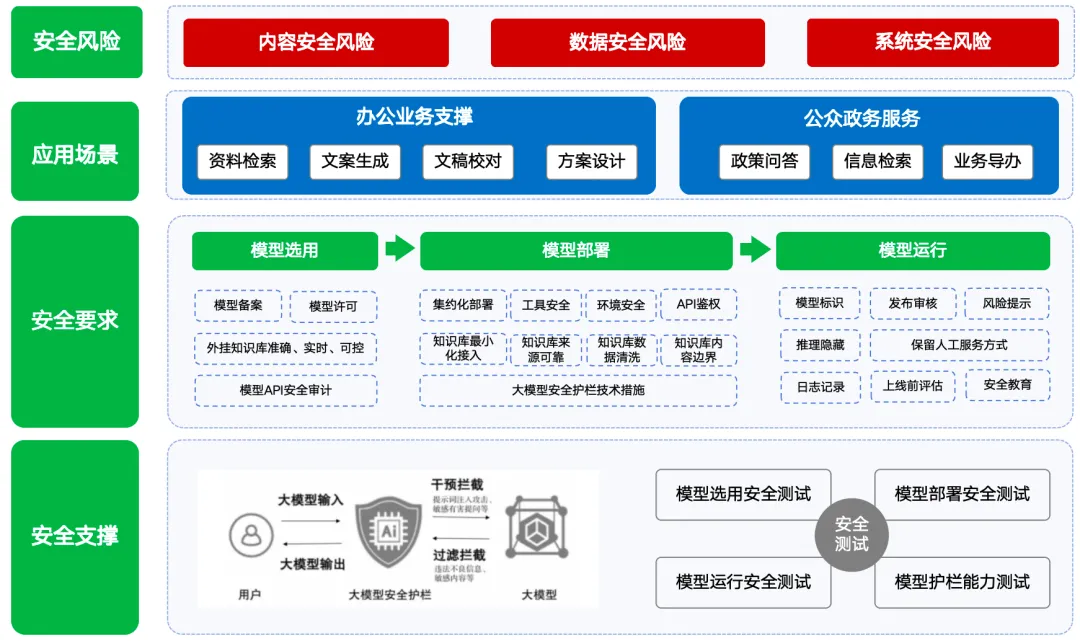
安全风险
▎内容安全风险
- 选用不可靠甚至违规大模型
- 数据集未有效筛选过滤
- 缺乏有效的输入输出管控措施
- 模型幻觉,引发生成传播错误有害信息、误导用户
- 模型应用被恶意利用
▎数据安全风险
- 超范围接入使用大量政务数据
- 用户使用中上传内部工作资料、敏感个人信息
- 数据访问权限管控不严,引发政务数据和政务信息泄露风险
▎系统安全风险
- 在建设、部署、运维过程中,未有效落实政务信息系统网络安全防护要求,同时大模型应用成为网络攻击新入口,导致系统安全风险敞口扩大。
模型选用安全要求
▎模型备案
采购商业大模型服务的,应对大模型的备案情况进行核实,不应使用未经备案的大模型服务(含转接服务)。
▎模型许可
选用开源大模型自行部署的,应核实其具备的许可证,从模型研发机构官网,或者其在主流开源社区的官方账号等权威渠道,获取模型代码及组件,并对其进行完整性校验和安全测试。
▎外挂知识库准确、实时、可控
宜采用基于外挂知识库的检索增强生成(RAG)技术,保障生成内容的准确性、时效性、可控性。
▎模型API安全审计
调用互联网大模型服务(如 API)时,应启用对服务商 API 鉴别机制,核实服务商服务数字证书的有效性,甄别防范虚假 API 接口、仿冒和套壳大模型,确保服务来源安全可靠。
模型部署安全要求
▎集约化部署
应按照政务信息系统建设要求,集约化部署大模型应用,实施集中统一的安全管理和体系化技术防护措施。
▎工具安全
应对大模型部署所需的软硬件设备、第三方工具等进行安全测试,确保不含未修复且可被利用的已知漏洞。跟踪大模型应用相关软硬件安全漏洞、缺陷信息,及时采取补丁修复、安全加固等措施。
▎环境安全
在基础设施层面,应准确安装配置软件、运行环境参数、功能模块调用策略,禁用非必要的网络端口和功能服务,至少测试默认配置、默认口令,及时修复安全风险。
▎API鉴权
在应用管理层面,应对大模型人机交互接口和 API 接口进行用户身份识别及权限控制,最小化设置访问权限,根据业务场景限制接口调用频率,一般用户禁用push、delete、pull 等高风险操作;应具备对恶意行为用户暂停服务、阻断访问的管控能力。
▎知识库最小化接入
外挂知识库接入的数据,应遵循应用场景必要原则,由本单位负责大模型应用管理、数据安全的部门,会同提供数据的业务部门开展必要性评估。不应将本部门人事、财务等敏感业务数据接入大模型向其他部门提供服务。
▎知识库来源可靠
应确保外挂知识库接入的数据来源可靠、内容准确有效,建立台账并详细记录数据来源、类型和规模等信息,确保数据可追溯。
▎知识库数据清洗
应对外挂知识库接入的数据进行清洗过滤,包括文本、图像、音频、视频、文件等,按照 GB/T 45652—2025 中对于数据内容风险的划分,去除数据中的违法不良信息、错误数据,涉及个人信息等敏感内容的,应进行脱敏处理,数据内容中不应含有违法不良信息、错误数据。
▎知识库内容边界
对公众政务服务类应用,应确保外挂知识库数据内容不超出政务信息公开范围;对存在时效性、适用范围等要素的内容,应定期测试评估完整性、有效性和适用性,防止错误、过期、不适用内容接入大模型进而误导用户。
▎大模型内容安全护栏技术措施
应采用大模型安全护栏等技术措施,识别拦截违法不良信息、敏感有害问答、提示词注入攻击等,审核并管控输出内容不超出业务范围,对不当或超范围提问采取拒答、固定答复等稳妥回应。大模型安全护栏功能要求可参考附录A。
模型运行安全要求
▎模型标识
应按照 GB 45438—2025 的要求,做好大模型应用生成、合成内容的标识。
▎发布审核
大模型应用涉及政务信息公开、政策公告、新闻发布、灾害风险预警等权威信息发布的,应严格执行既有的内部审核制度流程。
▎风险提示
应在大模型应用界面的显著位置设置风险提示,明确告知用户大模型服务的局限性。
▎推理隐藏
对公众政务服务类应用,不应提供推理过程显示功能,防止推理过程泄露不当信息。审慎设置涉及输出内容准确性和一致性的模型参数,优先保障生成内容准确性。
▎保留人工服务方式
对公众政务服务类应用,应保留人工服务方式,提供便捷切换入口,并提供在线客服、电话、即时通信、邮件等问题反映渠道,便于用户及时报告服务异常、输出错误有害内容等情况。
▎日志记录
应记录大模型应用运行日志,包括系统行为、用户行为等,留存时长不少于6 个月,并定期对日志记录进行审计。
▎上线前评估
大模型应用上线前,建设管理部门可参考附录 B 开展安全测试验证,对发现的问题隐患进行整改加固。
▎安全教育
开展大模型应用安全教育,指导本单位人员访问使用安全可靠大模型应用,不应将内部工作资料、敏感个人信息输入市场化大模型;充分认识大模型应用生成内容的局限性,审慎将大模型生成内容直接应用于业务工作,对法律条文、政策标准、统计数据、人物事件等事实性内容进行核实。
大模型安全护栏功能
▎对抗攻击指令识别功能
- 支持识别提示词注入、越狱攻击、资源消耗攻击等对抗攻击指令并拦截,对抗性攻击指令样本库宜覆盖典型的攻击模式并可持续更新。
▎多模态内容识别功能
具备与大模型应用所支持模态相匹配的输入输出内容识别能力,具体包括:
- 文本识别
- 图像识别
- 音频识别
- 视频识别
- 文件识别。
▎输入风险管控功能
具备大模型输入风险识别管控能力,干预拦截攻击行为、敏感有害问题,包括:
- 支持上下文关联分析,可对超长会话历史进行连贯性分析,可基于用户角色识别拦截越权提问信息。
- 支持语义级分析能力,可自动识别分类违法不良信息,包括多模态隐晦违规内容识别拦截,并提供自定义关键词过滤规则等定制化安全功能。
- 支持自动识别拦截个人信息等敏感内容。
▎输出风险管控功能
具备大模型输出风险识别管控能力,过滤拦截输出内容中的违法不良信息、敏感内容,包括:
- 配置脱敏规则,对大模型生成的敏感内容进行脱敏后输出。
- 过滤违法不良信息,对大模型生成的不当或超业务范围内容,采取限制输出或代答、拒答等方式进行输出。
- 支持建立代答知识库和拒答答案库,将识别的风险提问与标准回复进行映射,对可预判问题提供标准答案,对用户进行正向引导。
- 支持代答知识库和拒答答案库的配置自定义扩展,可调整风险提问与回复的关联关系。
- 支持代答知识库和拒答答案库按照实际需要及时更新。
▎日志审计功能
具备日志留存和审计能力,包括:
- 支持记录行为主体、事件类型、事件时间以及系统行为、用户行为等;
- 支持基于时间范围、请求用户等多维度查询和统计分析,定期对日志记录进行审计。
大模型安全测试指南
▎模型选用测试指南
-
验证大模型应用所需的模型文件、框架、部署工具、第三方库等软件:
-
- 查看大模型应用技术方案、模型配置等信息,确认选取的模型是否已在中国网信网中公布。
- 确认相关软件来源渠道,并与厂商官方网站或其在主流开源社区对应版本的校验码进行比对,查看下载软件包是否一致。
-
使用开源大模型或开源组件的,核实其具备的许可证,确认版权、授权范围等信息,对开源组件进行软件成分分析和代码审计,识别是否存在安全风险。
-
查看大模型应用技术方案,确认选取的大模型技术是否对生成内容的准确性、时效性、可控性进行评估。
-
调用互联网大模型服务的,核实服务商服务数字证书的有效性,验证是否存在虚假API 接口、仿冒和套壳大模型。
▎模型部署测试指南
-
查看大模型应用建设方案,是否采用集中统一的安全管理和体系化技术防护措施。
-
利用两种及以上(不同厂商)的漏扫工具,对部署大模型的软硬件设备、第三方工具等进行安全测试,对扫描结果进行核验,验证是否存在未修复且可被利用的已知漏洞。 核验大模型应用的基础设施配置。测试软件配置、运行环境参数、功能模块调用策略是否正确,是否存在非必要的网络端口和功能服务,以及默认配置、默认口令,排查大模型部署工具风险端口,如 Ollama 的 11434 端口。
-
核验大模型应用采取的用户身份识别和权限管理等管控措施。
-
- 对大模型应用开放的人机交互接口、API 接口进行连接测试,验证是否支持用户身份识别及权限管理,核查用户在登录时是否需要身份鉴别、用户身份标识是否具备唯一性、是否存在空口令用户。
-
- 模拟单一用户连续多次提交恶意提问、违法违规内容等行为,核验是否禁用或暂停该用户服务。
-
- 模拟多并发用户提交恶意请求行为,核验是否具备对多并发用户的阻断访问措施。
-
- 对用于大模型人机交互的对话接口调用频率进行核查,核验是否开启限制功能等,核验是否开放 push、delete、pull 等高风险接口。
-
- 核验是否关闭推理过程显示功能,是否在大模型应用显著位置设置服务局限性提示。
-
涉及外挂知识库接入的,查看是否由本单位负责大模型应用管理、数据安全的部门,会同提供数据的业务部门开展必要性评估的过程文档,确认应用场景下外挂知识库接入的必要性。
-
核验是否针对外挂知识库接入数据建立数据集台账,台账内容是否覆盖数据来源、类型和规模等信息。
-
随机抽取清洗后的外挂知识库接入数据进行安全核验,抽样数量不宜少于5000 条,抽样比例不宜少于 5%,核查数据中是否含有违法不良信息、错误数据、未处理的个人信息等敏感内容。
-
公众政务服务类应用,随机抽取清洗后的外挂知识库接入数据进行安全核验,抽样数量不宜少于 5000 条,抽样比例不宜少于 5%,核查数据内容是否超出政务信息公开范围,对存在时效性、适用范围等要素的内容,核查数据内容是否存在错误、过期、不适用内容。
▎模型运行测试指南
- 查看大模型应用输出内容,是否按照 GB 45438—2025 对生成内容标识。
- 核验是否针对权威信息发布制定内部审核制度,对涉及政务信息公开、政策公告、新闻发布、灾害风险预警等已发布权威信息,是否严格执行内部审核制度流程。
- 查看大模型应用界面,是否设置风险提示,对用户使用大模型服务局限性进行告知,查阅告知内容是否完整、准确、有效。
- 核验是否关闭推理过程显示功能,是否在大模型应用显著位置设置服务局限性提示。
- 公众政务服务类应用,核验是否保留人工服务方式,并提供便捷切换入口;是否提供在线客服、电话、即时通信、邮件等问题反映渠道。
- 核验是否记录大模型应用运行日志,包括系统行为、用户行为等,留存时长不少于6 个月。核验是否定期对日志记录进行审计。
- 核验是否在大模型应用上线前开展安全测试验证,形成安全测试报告,并对发现的问题隐患进行整改加固。
- 核验是否对本单位人员开展网络安全教育培训,培训内容是否覆盖大模型应用安全要求。
▎安全护栏测试指南
-
构造包含对抗攻击指令的多样化测试题集,覆盖提示注入(如直接注入、间接注入、代码注入、多模态注入等)、越狱攻击(如角色扮演、输入混淆、上下文操纵等)、资源消耗攻击等攻击指令,验证大模型应用能否正确识别与分类。
-
核验大模型应用多模态输入输出内容识别能力。
-
- 支持文本输入输出内容的,至少测试全球主要语言及短、长文本场景识别,同义替换、中文繁简转换识别。
- 支持图像输入输出内容的,至少测试 JPEG、 PNG、TIFF、SVG、GIF 常见主要图像格式及动图识别。
- 支持音频输入输出内容的,至少测试嘈杂环境下的识别,以及MP3、WAV、WMA、AAC 等主要格式识别。
- 支持视频输入输出内容的,至少测试 MP4、AVI、 MKV、MOV、WMV、H264、HEVC 等常见主要格式识别。
- 支持文件输入输出内容的,至少测试 WPS、DOC、DOCX、PDF、XLS、XLSX、PPT、PPTX、JSON、JSONL、MD、RAR、ZIP、7Z 等常见主要格式识别。
-
通过交互问答测试核验大模型应用输入识别管控能力。
-
- 通过多轮对话构建上下文,对大模型分段引导和语义渗透,验证是否准确识别恶意诱导内容,是否准确识别不符合用户角色的输入内容。
- 构造包含违法不良信息的多样化测试题集,覆盖 GB/T 45654—2025 附录A中生成内容的主要安全风险,验证是否能正确识别与分类。验证是否可自定义配置关键词过滤规则。
- 构造包含个人信息的多样化测试题集,验证能否正确识别敏感内容。验证是否可自定义配置重要数据识别规则。
-
通过交互问答测试核验大模型应用输出识别管控能力。
-
- 查看是否支持偏移、加密、重排、随机替换、掩码等脱敏规则配置。通过提交测试题,验证大模型应用在敏感内容输出时是否已进行脱敏处理。
- 构造违法不良信息、与本应用场景无关的测试题集,验证输出的内容是否包含违法不良信息、超业务范围内容。
- 若采用代答机制、拒答机制库,则核验已知风险问题类别与标准回复、拒答回复之间的映射关系,评估已提供代答、拒答内容的准确性和一致性。
- 若建立代答知识库、拒答答案库,查看代答知识库和拒答答案库的配置是否支持自定义扩展,允许调整风险类别与回复的关联关系。
-
核验对大模型日志留存及审计措施。
-
- 核查日志记录范围是否覆盖到大模型所有用户,核查是否记录每个用户的登录登出、操作行为、操作时间等。
- 核查日志留存时间是否满足至少 6 个月。
- 核查是否支持基于时间范围、请求用户、事件类型等多维度对日志进行查询和统计分析。