面向AI的15个攻击策略
MITRE的AI攻击策略解读
MITRE ATLAS是一个基于真实观察和攻击示例的人工智能系统对抗威胁知识库,它模拟MITRE ATT&CK框架,关注人工智能系统的安全风险。本文详细描述了15个攻击阶段以及每个阶段可能使用的技术能力。
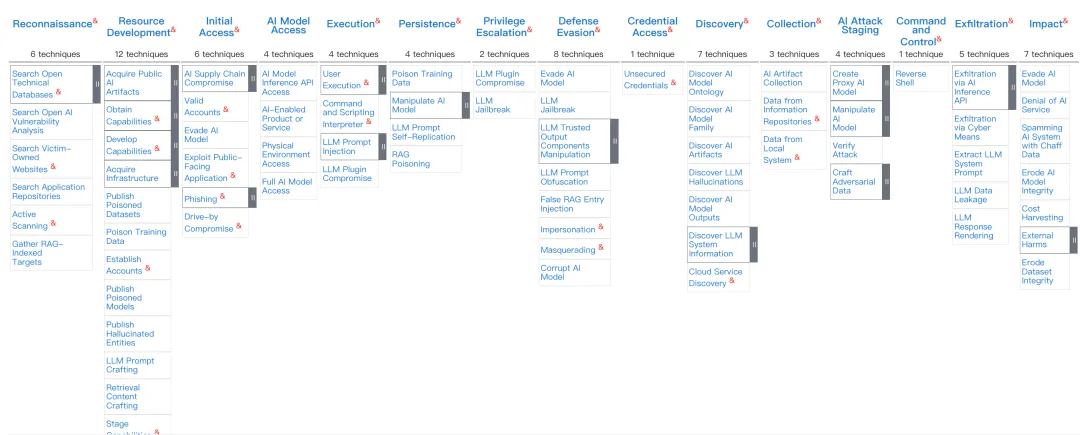
**▎**侦查(Reconnaissance)
侦查是指攻击者主动或被动地收集可用于支持目标定位的信息,此类信息可能包括受害组织的人工智能能力和研究成果的详细信息。攻击者可以利用这些信息来辅助其生命周期的其他阶段,例如利用收集到的信息获取相关的人工智能制品、锁定受害者使用的人工智能能力、根据受害者使用的特定模型定制攻击,或推动和引导进一步的侦察工作。此策略使用到的技术有:
- 搜索公开的技术数据库:攻击者搜索公开的研究和技术文档,以了解受害组织内部人工智能的使用方式和位置。攻击者可以利用这些信息识别攻击目标,或调整现有攻击以提高其有效性。
- 搜索已公开的AI漏洞研究资料:关于常见人工智能模型的漏洞,通常有大量的研究资料可供参考。一旦确定目标,攻击者很可能会尝试识别针对此类模型的任何现有研究成果。这不仅包括阅读可能识别成功攻击细节的学术论文,还包括识别此类攻击的现有实现。
- 受害者拥有的网站:攻击者可能会搜索受害者拥有的网站,以获取可用于定位的信息。受害者拥有的网站可能包含有关其人工智能产品或服务的技术细节,以及业务运营和关系的详细信息,包括部门/分部名称、实际位置以及关键员工的数据,例如姓名、职位和联系方式。
- 搜索应用商店:攻击者可能会在定位过程中搜索开放的应用程序存储库。例如,Google Play、iOS App Store、macOS App Store 和 Microsoft Store。
- 主动扫描:攻击者可能会探测或扫描受害系统以收集目标信息。
- 搜索RAG索引数据源:攻击者可能会识别检索增强生成 (RAG) 系统中使用的数据源,以进行目标定位。通过精确定位这些数据源,攻击者可以专注于毒害或以其他方式操纵人工智能所依赖的外部数据存储库。
**▎**资源开发(Resource Development)
资源开发是指攻击者利用各种技术,创建、购买或窃取/窃取可用于支持攻击目标的资源。这些资源包括 AI 组件、基础设施、账户或能力。攻击者可以利用这些资源来协助其生命周期的其他阶段,例如AI 攻击准备阶段。此策略使用到的技术有:
- 获取公开的人工智能成果:攻击者可能会搜索公共资源,包括云存储、面向公众的服务以及软件或数据存储库,以识别 AI 组件。这些 AI 组件可能包括用于训练和部署模型的软件堆栈、训练和测试数据、模型配置和参数。
- 获取基本能力:攻击者搜索并获取用于其行动的软件功能,这些功能可能专门用于基于人工智能的攻击,也可能用于恶意目的的通用软件工具。
- 针对性开发能力:攻击者开发定制能力来支持作战行动。这个过程包括识别需求、构建解决方案和部署能力。用于支持对AI系统进行攻击的能力本身并不一定基于AI。例如,设置包含对抗信息的网站,或创建包含混淆的渗透代码的 Jupyter 笔记本。
- 准备基础设施:攻击者购买、租赁或租用基础设施,基础设施解决方案包括物理服务器或云服务器、域名、移动设备和第三方 Web 服务。基础设施还可以包括物理组件,例如用于降低或破坏 AI 组件或传感器性能的对抗措施,例如印刷材料、可穿戴设备或伪装物。
- 发布中毒数据集:攻击者对训练数据进行投毒并将其发布到公共位置。被毒害的数据集可能是新的数据集,也可能是现有开源数据集的毒害变体。这些数据可能会通过入侵AI供应链被引入受害系统。
- 训练数据投毒:攻击者通过修改底层数据或其标签来毒害 AI 模型使用的数据集。这使得攻击者能够在基于这些数据训练的 AI 模型中嵌入一些不易被检测到的漏洞。数据中毒攻击可能需要修改标签,也可能不需要。
- 建立账户:攻击者创建具有各种服务的账户,用于定位、获取AI攻击所需的资源或冒充受害者。
- 发布中毒模型:攻击者将中毒模型发布到公共位置,例如模型注册表或代码存储库。中毒模型可能是新模型,也可能是现有开源模型的中毒变体。该模型可能通过入侵AI供应链引入受害者系统。
- 发布幻觉实体:攻击者创建一个由他们控制的实体,例如软件包、网站或电子邮件地址,并将其发送到 LLM 所制造的幻觉来源。这些幻觉可能以软件包名称、命令、URL、公司名称或电子邮件地址的形式出现,从而将受害者指向攻击者控制的实体。当受害者与攻击者控制的实体进行交互时,攻击便得以进行。
- LLM提示制作:攻击者利用他们获得的有关目标生成人工智能系统的知识来制作绕过其防御的提示并允许执行恶意指令。
- 检索内容制作:攻击者编写旨在供用户查询检索的内容,并以某种方式影响系统用户。精心设计的内容可以与即时注入相结合,也可以单独存在于文档或电子邮件中。攻击者必须将精心设计的内容导入受害者的数据库,例如检索增强生成 (RAG) 系统中使用的矢量数据库。这可以通过网络访问或滥用 RAG 系统中常见的提取机制来实现。
- 组织能力:攻击者上传、安装或以其他方式设置可在目标定位期间使用的功能。
**▎**初始访问(Initial Access)
目标系统可以是网络、移动设备或边缘设备(例如传感器平台)。系统使用的AI功能可以是本地的、板载的或云端的。初始访问包括使用各种进入向量在系统内获得初始立足点的技术。此策略使用到的技术有:
- AI供应链入侵:攻击者通过攻陷 AI 供应链中特定部分来获得系统的初始访问权限。这可能包括硬件、数据及其注释、 AI 软件堆栈的某些部分,或模型本身。在某些情况下,攻击者需要二次访问权限才能利用已攻陷的供应链组件全面发动攻击。
- 获取账户:攻击者获取并滥用现有账户的凭证,以此作为获取初始访问权限的手段。凭证的形式可以是个人用户账户的用户名和密码,也可以是用于访问各种 AI 资源和服务的 API 密钥。
- 逃避AI模型:攻击者精心设计对抗性数据,阻止AI模型正确识别数据内容。这种技术可以用来规避使用AI的下游任务。攻击者可以规避基于AI的病毒/恶意软件检测,或规避网络扫描,从而实现传统的网络攻击目标。
- 利用公开的应用程序:攻击者利用软件、数据或命令,利用面向互联网的计算机或程序中的弱点,从而引发非预期或未预料到的行为。系统中的弱点可能是错误、故障或设计漏洞。这些应用程序通常是网站,但也可能包括数据库(例如 SQL)、标准服务(例如 SMB 或 SSH)、网络设备管理协议(例如 SNMP 和 Smart Install),以及任何其他具有可通过互联网访问的开放套接字的应用程序,例如 Web 服务器和相关服务
- 网络钓鱼:攻击者发送钓鱼邮件来获取受害者系统的访问权限。所有形式的钓鱼都是通过电子方式传递的社会工程学。钓鱼可以有针对性地进行,这被称为鱼叉式网络钓鱼。在鱼叉式网络钓鱼中,攻击者会将特定的个人、公司或行业作为目标。更普遍的是,攻击者可以进行非针对性的网络钓鱼,例如在大规模恶意软件垃圾邮件活动中。生成式人工智能(包括生成合成文本、人脸视觉深度伪造和语音音频深度伪造的 LLM)正在帮助攻击者扩大针对性网络钓鱼活动的规模。LLM 可以通过文本对话与用户互动,并可以通过元提示进行编程以窃取敏感信息。深度伪造可用于模拟身份,从而辅助网络钓鱼。
- 驱动式入侵:攻击者通过用户在正常浏览过程中访问网站,或通过 AI 代理代表用户从网络检索信息来访问 AI 系统。网站可能包含LLM 提示注入,一旦执行,即可改变 AI 模型的行为。
**▎**AI模型访问(AI Model Access)
AI 模型访问技术能够利用各种类型的 AI 模型访问权限,攻击者可利用这些访问权限获取信息、发起攻击,并向模型输入数据。访问权限级别范围广泛,从完全了解模型内部结构,到访问收集数据用于 AI 模型的物理环境。攻击者在攻击过程中可能会使用不同级别的模型访问权限,从发起攻击到影响目标系统,不一而足。访问 AI 模型可能需要访问承载该模型的系统,该模型可以通过 API 公开访问,或者可以通过与利用 AI 作为其流程一部分的产品或服务的交互间接访问。此策略使用到的技术有:
- AI模型推理API访问:攻击者通过合法访问推理 API 来获取模型。推理 API 访问权限可以作为攻击者的信息来源(发现 AI 模型本体、发现 AI 模型家族)、发起攻击的手段(验证攻击、制作对抗数据),或将数据引入目标系统造成影响(规避 AI 模型、侵蚀 AI 模型完整性)。许多系统依赖于通过推理 API 提供的相同模型,这意味着它们共享相同的漏洞。对于训练资源极其密集的基础模型尤其如此。攻击者可能会利用其对模型 API 的访问权限来识别诸如越狱或幻觉之类的漏洞,然后攻击使用相同模型的应用程序。
- 底层AI模型访问:攻击者利用底层采用人工智能的产品或服务来访问底层 AI 模型。这种间接模型访问可能会在日志或元数据中泄露 AI 模型或其推理的细节。
- 物理环境访问:除了纯粹在数字领域发生的攻击外,攻击者还可能利用物理环境进行攻击。如果模型以某种方式与从现实世界收集的数据进行交互,攻击者就可以通过访问数据收集的任何地方来影响模型。通过在收集过程中修改数据,攻击者可以执行针对数字访问而设计的修改版攻击。
- 完全AI模型访问:攻击者获得对 AI 模型的完全“白盒”访问权限。这意味着攻击者完全了解模型架构、参数和类本体。他们可能会窃取模型,以便在难以检测到其行为的离线状态下制作对抗数据并验证攻击。
**▎**执行(Execution)
执行是指攻击者利用一些技术,在本地或远程系统上运行受攻击者控制的代码。运行恶意代码的技术通常与其他所有攻击手段相结合,以实现更广泛的目标,例如探测网络或窃取数据。例如,攻击者可能会使用远程访问工具运行执行远程系统发现 ( RDS) 的 PowerShell 脚本。此策略使用到的技术有:
- 用户执行:攻击者可能依赖用户的特定操作来执行攻击。用户可能会无意中执行通过人工智能供应链入侵引入的不安全代码。用户可能会遭受社会工程学攻击,例如打开恶意文档文件或链接,从而执行恶意代码。
- 命令和脚本解释器:攻击者滥用命令和脚本解释器来执行命令、脚本或二进制文件。这些接口和语言提供了与计算机系统交互的方式,并且是许多不同平台的通用功能。大多数系统都自带一些内置的命令行界面和脚本功能,例如,macOS 和 Linux 发行版包含某种版本的 Unix Shell,而 Windows 系统则包含 Windows Command Shell 和 PowerShell。还有跨平台解释器,例如 Python,以及通常与客户端应用程序相关的解释器,例如 JavaScript 和 Visual Basic。攻击者可能会以各种方式滥用这些技术来执行任意命令。
- LLM提示注入:攻击者精心设计恶意提示作为 LLM 的输入,导致 LLM 以非预期的方式运行。这些“提示注入”通常旨在使模型忽略其原始指令的某些部分,转而遵循攻击者的指令。即时注入可以作为 LLM 的初始访问向量,为攻击者提供立足点,从而执行其操作中的其他步骤。它们可能旨在绕过 LLM 中的防御措施,或允许攻击者发出特权命令。即时注入的效果可以持续存在于与 LLM 的整个交互会话中。攻击者可以直接注入恶意提示(直接注入),以利用 LLM 生成有害内容或在系统中站稳脚跟并造成进一步影响。当 LLM 在正常运行过程中从其他数据源获取恶意提示时,也可以间接注入提示(间接注入)。攻击者可以利用这种注入方式在系统中站稳脚跟,或瞄准 LLM 的用户。
- LLM插件泄露:攻击者利用其对大型系统内 LLM 的访问权限来入侵连接的插件。LLM 通常通过插件连接到其他服务或资源,以增强其功能。插件可能包括与其他应用程序的集成、对公共或私有数据源的访问以及执行代码的能力。这可能允许攻击者对集成应用程序或插件执行 API 调用,从而提升系统权限。攻击者可能利用连接的数据源来检索敏感信息。他们还可能使用集成了命令或脚本解释器的 LLM 来执行任意指令。
**▎**持久性(Persistence)
持久性是指攻击者用来在系统重启、凭据更改以及其他可能导致访问权限中断的中断情况下保持系统访问权限的技术。用于持久性的技术通常涉及留下经过修改的机器学习构件,例如中毒的训练数据或被操纵的 AI 模型。此策略使用到的技术有:
- 训练数据投毒:该技术在资源开发阶段就有使用,并且具有一定的持久性。
- 操纵AI模型:攻击者直接操纵 AI 模型来改变其行为或引入恶意代码。操纵模型会使攻击者对系统产生持久性的影响。这可能包括通过更改模型权重来毒害模型、修改模型架构以改变其行为,以及嵌入可在模型加载时执行的恶意软件。
- LLM提示自我复制:攻击者使用精心设计的LLM 提示注入,使 LLM 将提示复制为其输出的一部分。这使得提示能够传播到其他 LLM 并在系统中持久化。自我复制的提示通常与其他恶意指令(例如:LLM 越狱、LLM 数据泄露)搭配使用。
- RAG中毒:攻击者将恶意内容注入检索增强生成 (RAG) 系统索引的数据中,从而通过基于 RAG 的搜索结果污染未来的线索。攻击者可以通过将操纵的文档放置在 RAG 索引的位置来实现这一点。内容可能会被定向攻击,使其始终作为特定用户查询的搜索结果出现。攻击者的内容可能包含虚假或误导性信息,还可能包含恶意指令的快速注入或虚假的 RAG 条目。
**▎**权限提升(Privilege Escalation)
权限提升是指攻击者用来获取系统或网络更高级别权限的技术。攻击者通常可以以非特权访问权限进入并探索网络,但需要提升权限才能实现其目标。常见的方法是利用系统弱点、错误配置和漏洞这些技术通常与持久性技术重叠,因为允许攻击者持久存在的操作系统功能可以在提升的环境中执行。此策略使用到的技术有:
- LLM插件泄露:执行阶段会使用到该技术,这里强调的是攻击者可以利用该技术获取更高权限。
- LLM越狱:攻击者使用精心设计的LLM 即时注入,使 LLM 处于可以自由响应任何用户输入的状态,从而绕过 LLM 上的任何控制、限制或防护措施。一旦成功越狱,LLM 便可能被攻击者以意想不到的方式利用。
**▎**防御规避(Defense Evasion)
防御规避是指攻击者在攻击过程中用来规避检测的技术。用于规避防御的技术包括规避支持人工智能的安全软件,例如恶意软件检测器。此策略使用到的技术有:
- 逃避AI模型:该技术既可以在初始登录时使用,也可以用在攻击链条的任一个环节,用来躲避被动的检测。
- LLM越狱:越狱技术既可以帮助攻击者获取更高权限,也可以帮助攻击者规避风险检测。
- LLM可信输出组件操作:攻击者利用大型语言模型 (LLM) 的提示,操纵其响应的各个组成部分,使其对用户而言显得值得信赖。这有助于攻击者继续在受害者环境中活动,并逃避与其交互的用户的检测。LLM 可能会被指示调整其语言,使其在用户眼中显得更值得信赖,或试图操纵用户采取某些操作。其他可能被操纵的响应组件包括链接、推荐的后续操作、检索到的文档元数据以及引用。
- LLM提示混淆:攻击者向用户隐藏或混淆提示注入或检索内容以避免被发现。这可能包括修改注入的呈现方式,例如小文本、与背景颜色相同的文本或隐藏的 HTML 元素。
- 虚假RAG注入:攻击者将虚假条目引入受害者的检索增强生成 (RAG) 数据库。当检索到包含虚假文档的 RAG 条目时,LLM 会被诱骗,将部分检索到的内容视为虚假的 RAG 结果。通过在常规 RAG 条目中包含虚假的 RAG 文档,它可以绕过数据监控工具。它还可以防止文档被直接删除。攻击者可能会利用已发现的系统关键字,学习如何指示特定的 LLM 将内容视为 RAG 条目。他们或许能够操纵注入条目的元数据,包括文档标题、作者和创建日期。
- 冒充:攻击者冒充受信任的个人或组织,以说服和诱骗目标代表他们执行某些操作。例如,攻击者可能会冒充已知的发送者(例如高管、同事或第三方供应商)与受害者进行通信。然后,攻击者可以利用已建立的信任来实现其最终目标,甚至可能针对多个受害者。攻击者可能会瞄准 AI DevOps 生命周期中的资源,例如模型存储库、容器注册表和软件注册表。
- 伪装:攻击者试图操纵其制品的特性,使其在用户和/或安全工具面前显得合法或无害。伪装是指为了逃避防御和观察,操纵或滥用对象(无论合法或恶意)的名称或位置。这可能包括操纵文件元数据、诱骗用户错误识别文件类型以及提供合法的任务或服务名称。
- 损害AI模型:攻击者故意破坏恶意 AI 模型文件,使其无法成功反序列化,从而逃避模型扫描器的检测。在反序列化失败之前,损坏的模型仍可能成功执行恶意代码。
**▎**凭证访问(Credential Access)
凭据访问是指窃取账户名和密码等凭据的技术。用于获取凭据的技术包括键盘记录或凭据转储。使用合法凭据可以让攻击者访问系统,使其更难被检测到,并提供创建更多账户以实现其目标的机会。此策略使用到的技术有:
- 不安全的凭证:攻击者可能会搜索受感染的系统,以查找并获取不安全存储的凭证。这些凭证可能存储和/或错放在系统上的许多位置,包括明文文件(例如 bash 历史记录)、环境变量、操作系统或应用程序特定的存储库(例如注册表中的凭证),或其他专用文件/构件(例如私钥)。
**▎**探索(Discovery)
探索是指攻击者可能用来获取系统和内部网络信息的技术。这些技术可以帮助攻击者观察环境,并在决定如何行动之前进行调整。它们还能帮助攻击者探索他们可以控制的内容以及入口点周围的环境,从而发现这些环境如何有利于他们当前的目标。操作系统原生工具通常用于这种入侵后的信息收集目标。此策略使用到的技术有:
- 探索AI模型本体:攻击者可能会通过反复查询模型,迫使模型枚举其输出空间来发现本体。或者,他们也可能在配置文件或模型文档中发现本体。模型本体可以帮助攻击者了解受害者如何使用该模型,从而有助于攻击者发起有针对性的攻击。
- 探索AI模型系列:模型的一般信息可能会在文档中披露,或者攻击者可能会使用精心构建的示例并分析模型的响应来对其进行分类。了解模型家族可以帮助攻击者识别攻击模型的手段并帮助定制攻击。
- 探索AI组件:攻击者搜索私人来源,以识别系统中存在的 AI 学习组件并收集相关信息。这些组件可能包括用于训练和部署模型的软件堆栈、训练和测试数据管理系统、容器注册表、软件存储库以及模型库。这些信息可用于识别进一步收集、泄露或破坏的目标,并定制和改进攻击。
- 探索LLM幻觉:攻击者触发大型语言模型并识别幻觉实体。他们可能会请求软件包、命令、URL、组织名称或电子邮件地址,并识别与现实世界来源无关的幻觉。发现的幻觉为攻击者提供了发布幻觉实体的潜在目标。不同的 LLM 已被证明会产生相同的幻觉,因此攻击者利用的幻觉可能会影响其他 LLM 的用户。
- 探索AI模型输出:攻击者发现模型输出(例如课程分数),这些输出并非系统正常运行所必需的,也不旨在供最终用户使用。模型输出可能存在于日志中,也可能包含在 API 响应中。模型输出可能使攻击者能够识别模型中的弱点并发起攻击。
- 探索LLM系统信息:攻击者获取有关大型语言模型 (LLM) 系统信息的信息。这些信息可能存在于包含系统指令的配置文件中,也可能通过与 LLM 的交互提取。所需信息可能包括完整的系统提示符、对 LLM 有意义的特殊字符,或指示 LLM 可用功能的关键字。攻击者可以利用 LLM 指令信息来了解系统功能,并协助其编写恶意提示符。
- 探索云服务:攻击者在获得访问权限后尝试枚举系统上运行的云服务。这些方法可能因平台即服务 (PaaS)、基础设施即服务 (IaaS) 或软件即服务 (SaaS) 而异。各种云提供商提供多种服务,包括持续集成和持续交付 (CI/CD)、Lambda 函数、Entra ID 等。它们还可能包括安全服务(例如 AWS GuardDuty 和 Microsoft Defender for Cloud)以及日志记录服务(例如 AWS CloudTrail 和 Google Cloud Audit Logs)。攻击者可能会尝试发现有关整个环境中启用的服务的信息。Azure 工具和 API(例如 Microsoft Graph API 和 Azure 资源管理器 API)可以枚举可通过身份访问的资源和服务,包括应用程序、管理组、资源和策略定义及其关系。
**▎**收集(Collection)
收集是指攻击者可能使用的技术手段,以及与实现攻击者目标相关的信息来源。通常,收集数据后的下一个目标是窃取(泄露)AI 数据,或利用收集到的信息来实施未来的行动。常见的目标来源包括软件存储库、容器注册表、模型存储库和对象存储。此策略使用到的技术有:
- AI工具收集:攻击者收集 AI 工件用于渗透或AI 攻击准备。AI工件包括模型、数据集以及与模型交互时生成的其他遥测数据。
- 来自信息存储库的数据:攻击者利用信息存储库挖掘有价值的信息。信息存储库是一种用于存储信息的工具,通常用于促进用户之间的协作或信息共享,并且可以存储各种各样的数据,这些数据可能有助于攻击者实现进一步的目标,或直接访问目标信息。存储库中存储的信息可能因具体实例或环境而异。具体的常见信息存储库包括 SharePoint、Confluence 和企业数据库(例如 SQL Server)。
- 来自本地的数据:攻击者搜索本地系统源,例如文件系统和配置文件或本地数据库,以便在渗透之前找到感兴趣的文件和敏感数据。这可能包括基本指纹信息和敏感数据,例如 ssh 密钥。
**▎**AI攻击阶段(AI Attack Staging)
AI 攻击阶段由攻击者用来准备攻击目标 AI 模型的技术组成。这些技术包括训练代理模型、毒害目标模型以及精心设计对抗数据以输入目标模型。其中一些技术可以以离线方式执行,因此难以缓解。这些技术通常用于实现攻击者的最终目标。此策略使用到的技术有:
- 创建代理模型:攻击者获取模型,将其作为受害组织正在使用的目标模型的代理。代理模型用于以完全离线的方式模拟对目标模型的完整访问。攻击者可能会从代表性数据集训练模型,尝试从受害者推理 API 复制模型,或使用可用的预训练模型。
- 操纵AI模型:操纵AI模型不仅是持久性策略的一个技术手段,也是对AI进行攻击的一个具体动作。
- LLM提示自我复制:通过提示注入,诱导LLM输出内容含有预设提示,并在系统间复制传播,这是对AI系统的直接攻击,且具有持久性。
- RAG中毒:通过在AI使用的RAG中植入毒性数据,可实现对AI系统的直接攻击,并且具有持久性。
**▎**命令与控制(Command AND Control)
命令与控制 (C&C) 是指攻击者可能用来与受害网络内受其控制的系统进行通信的技术。攻击者通常会尝试模仿正常的预期流量以避免被发现。攻击者可以通过多种方式建立命令与控制,并根据受害者的网络结构和防御能力设置不同程度的隐秘性。此策略使用到的技术有:
- 反向Shell:攻击者利用反向 shell 来与受害者系统进行通信并控制它。通常情况下,用户使用客户端连接到正在监听连接的远程计算机。攻击者利用反向shell监听来自受害者系统的传入连接。
**▎**数据窃取(Exfiltration)
数据窃取是指攻击者可能使用的技术从您的网络中窃取数据。数据可能被窃取以获取其宝贵的知识产权,或用于策划未来的行动。从目标网络获取数据的技术通常包括通过其命令和控制通道或备用通道传输数据,还可能包括对传输的大小进行限制。私人训练数据相关信息的泄露引发隐私担忧。私人训练数据可能包含个人身份信息或其他受保护数据。此策略使用到的技术有:
- 通过AI推理API进行渗透:攻击者通过AI 模型推理 API 访问窃取私人信息。事实证明,AI 模型会泄露其训练数据的私人信息(例如, 推断训练数据成员资格、反转 AI 模型)。模型本身也可能被提取(提取 AI 模型),用于AI 知识产权盗窃。
- 通过网络手段进行渗透:攻击者通过传统的网络手段窃取人工智能产品或与其目标相关的其他信息。
- 提取LLM系统提示:攻击者尝试提取大型语言模型 (LLM) 的系统提示符。这可以通过提示符注入来实现,诱导模型显示其自身的系统提示符,也可以从配置文件中提取。系统提示可以成为人工智能提供商竞争优势的一部分,因此是可能成为攻击者攻击目标的宝贵知识产权。
- LLM数据泄露:攻击者精心设计提示,诱使 LLM 泄露敏感信息。这些信息可能包括用户私人数据或专有信息。泄露的信息可能来自专有训练数据、LLM 连接的数据源,或来自 LLM 其他用户的信息。
- LLM响应渲染:攻击者利用大型语言模型 (LLM) 来响应用户客户端渲染的隐藏隐私信息。这些信息随后会被窃取。这种窃取的形式可以是渲染图像,这些图像会自动向攻击者控制的服务器发出请求;也可以是需要用户交互的可点击链接。
**▎**影响(Impact)
影响是指攻击者通过操纵业务和运营流程来破坏可用性或损害完整性的技术。用于造成影响的技术可能包括销毁或篡改数据。在某些情况下,业务流程可能看起来正常,但可能已被篡改,以利于攻击者的目标。攻击者可能会利用这些技术来实现其最终目标,或为泄密行为提供掩护。此策略使用到的技术有:
- 逃避AI模型:通过技术手段躲避风险检测,既可以使用在攻击周期的中间阶段,本身也是对检测类模型任务的破坏。
- 拒绝AI服务:攻击者向支持 AI 的系统发送大量请求,目的是降低服务性能或关闭服务。由于许多 AI 系统需要大量专用计算,因此它们往往会成为成本高昂的瓶颈,并且容易超载。攻击者可能会故意设计输入,要求 AI 系统执行大量无用的计算。
- 灌水AI请求:攻击者向AI系统发送大量虚假数据,从而增加检测次数。这会导致受害组织的分析师浪费时间审查和纠正错误的推断。
- 算力攻击:攻击者利用对抗性数据输入降低目标模型的性能,从而逐渐削弱系统可信度。这可能导致受害组织浪费时间和金钱,既要尝试修复系统,又要执行原本需要手动自动化的任务。
- 成本攻击:攻击者针对不同的 AI 服务发送无用的查询或计算成本高昂的输入,从而增加受害组织服务运行成本。海绵样本是一种特殊类型的对抗数据,旨在最大化能源消耗,从而提高运营成本。
- 外部危害:攻击者滥用对受害系统的访问权限,并利用其资源或功能对系统外部造成损害,从而实现其目标。这些损害可能影响组织(例如财务损害、声誉损害)、用户(例如用户损害)或公众(例如社会损害)。
- 数据集灌水:攻击者毒害或操纵数据集的部分内容,以降低其实用性、降低信任度,并导致用户浪费资源来纠正错误。
*关于MITRE*
MITRE是一家专注于网络安全与航空科技的非盈利组织,作为美国政府的重要研发合作伙伴,MITRE在国防(如建立首个现代化防空系统)、医疗(如助力新冠研究)、生物科技及网络安全等关键领域持续贡献核心力量。尤为重要的是,其创立的CVE、CWE标准已成为全球漏洞识别的基石,其ATT&CK框架则引领着网络攻防对抗的前沿发展。
同专题推荐
查看专题壮丽人性:AI 时代如何守护人类尊严
2026 年 5 月,梵蒂冈发布了教皇利奥十四世的首份通谕《Magnifica Humanitas》,中文可以译作《壮丽人性》或《伟大的人性》。
五眼联盟对企业AI安全的劝告书
五眼联盟网络安全机构发布 Agentic AI 安全劝告书,核心不是反对企业使用 Agent,而是提醒组织必须在身份、权限、工具、上下文、审计和恢复等层面建立运行时安全基础设施。
AgentWard:高自主Agent全生命周期安全框架
AgentWard 提出面向自主 Agent 的五阶段生命周期安全架构,将初始化、输入、记忆、决策和执行分别纳入分层防护,并通过共享风险状态实现跨层联动。