可信AI七大特征与四大支柱
NIST的AI风险管理框架AI-RMF1.0解读
可信AI七大特征与四大支柱
美国国家标准与技术研究院(NIST)于2023年发布****AI风险管理框架1.0(AI RMF 1.0)*,作为指导组织识别和管理AI风险的自愿性框架。AI RMF提出了“地图-测评-管理-治理”四大职能支柱,用于构建可信AI。框架强调一系列信任特征,包括*有效性、可靠性、安全性、抗干扰性、可问责与透明性、可解释性、隐私增强、公平性**等,以帮助企业平衡创新与风险。**

本文简明扼要地提炼了框架中的核心内容,归纳为AI系统的生命周期、可信AI七大特征和四大支柱三部分内容,同时提供原文文档供大家下载研读。
01
—
AI系统的生命周期
AI系统的生命周期包括系统规划设计、数据采集与处理、模型训练与构建、模型验证与确认、系统部署与使用、系统运行与监控、系统使用与影响这七个阶段,在整个生命周期需要关注应用场景、数据&输入、AI模型、任务&输出、人类社群这五大关键维度。
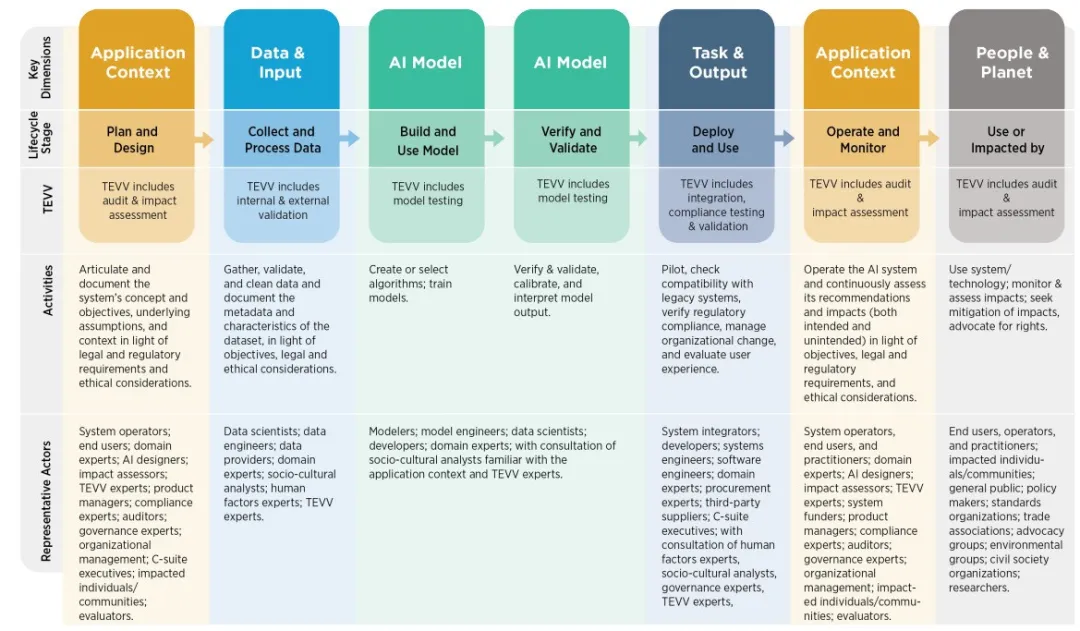
每个阶段的主要工作内容、相关参与方以及测试评估维度(TEVV)如下表所示:
| 阶段一:系统规划与设计(Plan and Design) TEVV:审计与影响评估 工作内容:明确并记录系统的概念与目标、基本假设和背景,并结合法律法规与伦理要求进行说明。 参与方:系统运营者、终端用户、领域专家、AI设计师、影响评估员、TEVV专家、产品经理、合规专家、审计员、治理专家、组织管理层、高管、受影响的个人或社区、评估人员。 |
|---|
| 阶段二:数据采集与处理(Collect and Process Data) TEVV:内部与外部验证 工作内容:收集、验证和清洗数据,记录数据集的元数据和特征,并结合目标、法律和伦理要求。 参与方:数据科学家、数据工程师、数据提供者、领域专家、社会文化分析师、人因专家、TEVV 专家。 |
| 阶段三:模型训练与构建 (Build and Use Models) TEVV:模型测试 工作内容:创建或选择算法,训练模型。 参与方:建模人员、模型工程师、数据科学家、开发人员、领域专家,并咨询熟悉应用背景的社会文化分析师和TEVV专家。 |
| 阶段四:验证与确认 (Validate and Verify) TEVV:模型测试 工作内容:验证与确认、校准并解释模型输出。 参与方:系统集成商、开发人员、系统工程师、软件工程师、领域专家、采购专家、第三方供应商、高管,并咨询人因专家、社会文化分析师、治理专家、TEVV专家。 |
| 阶段五:部署与使用 (Deploy and Use) TEVV:集成、合规测试与验证 工作内容:试点运行,检查与旧系统的兼容性,验证法规合规性,管理组织变更,并评估用户体验。 参与方:系统运营者、终端用户和从业者、领域专家、AI设计师、影响评估员、TEVV 专家、系统资助方、产品经理、合规专家、审计员、治理专家、组织管理层、受影响的个人或社区、评估人员。 |
| 阶段六:运行与监控 (Operate and Monitor) TEVV:审计与影响评估 工作内容:运行AI系统,并持续评估其建议和影响(包括预期和非预期影响),结合目标、法律法规和伦理要求。 参与方:终端用户、运营者和从业者、受影响的个人或社区、公众、政策制定者、标准组织、行业协会、倡导团体、环保组织、民间社会组织、研究人员。 |
| 阶段七:使用与影响 (Use or Be Affected) TEVV:审计与影响评估 工作内容:使用系统/技术;监控与评估影响;寻求影响缓解并倡导权利。 参与方:公众、受影响的个人或社区、政策制定者、标准制定组织、社会团体、环保组织、研究人员等。 |
tips:
- *TEVV***:Testing(测试)、Evaluation(评估)、Verification(验证)、Validation(确认)的缩写,代表AI生命周期各阶段的质量与安全保障环节。
02
—
可信AI七大特征
 ’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
**▎**有效性与可靠性(Valid and Reliable)
有效性是指通过提供客观证据,确认AI系统是否满足预期的使用需求。如果AI系统不准确、不可靠或在新的数据和环境下表现差,就会增加AI的风险,降低其可信度。 可靠性是指AI系统在一定时间和条件下,是否能够持续、无故障地按要求工作。可靠性意味着系统在预期使用条件下,以及在一段时间内,是否能稳定运行。 除此之外,准确性和鲁棒性对系统的可信度也非常重要:准确性指的是AI的预测或计算结果与真实值或公认正确值的接近程度;鲁棒性是指AI系统在各种不同条件下,是否能稳定运行并保持功能。 这四个特性相辅相成,共同决定了AI系统的性能和可信度:有效性确保系统能够实现其设计目标,可靠性确保系统能够在实际应用中持续有效地工作,准确性确保系统的输出是正确的,鲁棒性确保系统在变化的环境中依然能够稳定表现。
**▎**安全性(Safe)
AI系统的安全性要求它们在预定条件下不会对人类生命、健康、财产或环境造成威胁。安全的AI系统应该:
- 通过负责任的设计和开发保证安全;
- 为部署者提供清晰的使用指南;
- 部署者和用户做出负责任的决策;
- 提供基于证据的风险评估和说明。
AI系统的安全性管理要根据具体的风险类型和严重性,采取不同的管理方法。对于潜在的严重风险,如可能危及生命的安全问题,应该优先采取最严格的安全措施。
**▎**安全与韧性(Secure and Resilient) 安全指AI系统在面临攻击或不当使用时,能够保护机密性、完整性和可用性。AI系统的安全和韧性是密切相关的,但也有不同。韧性侧重于恢复功能,而安全则包括避免、应对或恢复攻击的策略。
韧性是指AI系统及其生态系统在遭遇意外事件或环境变化时,能否保持正常运作,或者在需要时能够安全地退化。
**▎**可问责与透明(Accountable and Transparent)
AI的可信度离不开可问责性,而可问责性又依赖于透明性。透明性意味着AI系统的工作过程和输出信息应对用户开放,帮助用户理解系统如何做出决策。透明性越高,用户对AI系统的信任度也会越高。透明性不仅包括系统设计和训练数据,还包括系统部署的过程和决策者的责任。
AI系统的透明性应当根据不同角色的需求进行定制,确保适当的信息可以被相关人员理解。在一些情况下,透明性有助于及时纠正系统的错误,减少负面影响。
**▎**可解释与可理解(Explainable and Interpretable)
可解释性指的是能够解释AI系统内部的工作机制,可理解性则是让用户理解系统输出的意义。两者结合,有助于提高系统的可信度,使得用户能够理解AI系统的决策过程。
- 可解释性可以帮助开发者和监管者调试、监控系统,并做好文档记录和治理。
- 可理解性可以帮助用户明白AI系统的决定为何会如此,及其对用户的意义。
透明性、可解释性和可理解性是相互支持的特性,它们共同帮助用户理解AI系统的决策过程。
**▎****隐私增强(**Privacy-Enhanced)
隐私增强指的是保护个人信息和身份的规范和措施,隐私增强技术(PETs)可以帮助设计更加保护隐私的AI系统。隐私保护和安全、偏见、透明性之间存在权衡,因此需要平衡这些特性。例如,隐私增强技术可能会影响系统的准确性,进而影响某些领域的公平性决策。
**▎****公平—有害偏见管理(**Fair – with Harmful Bias Managed)
公平性是AI中的一个重要议题,涉及到如何处理偏见和歧视等问题。公平性标准很复杂,因文化和应用的不同而有所差异。AI系统中的有害偏见可能会放大不平等和歧视,影响不同群体。偏见可以表现为系统性偏见、计算偏见和人类认知偏见等形式。 AI系统可能加速偏见的传播,但我们也可以通过改善透明性和公平性来减轻这些负面影响。
tips:
在AI可信度的讨论中,**“Safe”和“Security”**这两个词都涉及到系统的保护和避免风险,但它们的含义和关注点有所不同:
-
*Safe(安全性)**更侧重于AI系统在特定条件下是否会导致对人类生命、健康、财产或环境的威胁。它强调的是系统在使用过程中避免造成直接的伤害或危险。简单来说,“safe”关注的是系统运行是否会带来不可接受的风险,特别是对生命、健康等方面的威胁。*
-
- 例如,一个自动驾驶系统必须是“safe”的,因为它不能在行驶过程中对乘客或行人构成危险。
- 关注点*:如何设计、开发和使用AI系统,以确保其操作过程中不会对人类或环境造成危害。*
-
Security(安全)*则更多关注防止外部攻击、滥用或非法访问。它涵盖了保护系统的机密性、完整性和可用性,确保数据不会被未经授权的用户访问或篡改。安全性还涉及应对黑客攻击、数据泄露、系统入侵等风险。*
-
- 例如,AI系统的安全性确保它不会被黑客攻破,避免数据泄露或不当使用。
- 关注点*:防止恶意攻击或外部干扰,保护系统不受攻击、破坏或非法访问。*
03
—
可信AI四大支柱
*AI RMF Core* 是NIST提出的AI风险管理核心框架,由*治理(GOVERN)、地图(MAP)、测评(MEASURE)和管理(MANAGE)*四大功能构成,每个功能细分为类别、子类别,再落到具体的行动与成果,旨在为组织提供共同语言和实践指南,支持在 AI 全生命周期内持续、及时地识别、评估与应对风险。
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
下表是对框架四大功能的解读,方便大家理解四个功能的含义:
| 1. 治理(GOVERN):定规则、立规矩先定好“公司文化”和“风险态度”,告诉大家做事的原则,比如:AI 不能歧视、不能泄露隐私。设好流程和文档,让每个人都知道该怎么发现、报告、处理风险。把技术和公司价值观绑在一起,确保技术团队和业务团队方向一致。💡 示例: 你准备上线一个大模型客服系统,先要制定“客服不回应个人隐私问题”的原则,并且在开发、测试、上线环节都有人负责检查。 |
|---|
| 2. 地图(MAP):看全局、找风险弄清楚AI系统在哪用、谁会用、可能影响谁。找出上下游环节的依赖,比如训练数据从哪来、部署环境限制是什么。想明白用错的后果,比如模型被拿去做诈骗的风险。💡 示例**:** 你要做一个医疗诊断AI,要先弄清楚它面对的病人群体、医生使用的方式,以及可能带来的法律和伦理风险。 |
| 3. 测评(MEASURE):做检测、量指标用各种方法(定量、定性或混合)去检测 AI 是否安全、好用、可靠。不只是在上线前测,还要上线后定期测,避免它“跑偏”。测试要有标准、有记录,确保别人能复现结果。💡 示例: 你定期用一批“安全测试集”去问模型一些敏感问题,看它会不会回答违规内容,并记录拒答率、准确率等指标。 |
| 4. 管理(MANAGE):持续管、能修复根据测量出来的风险,分配人力和资源去解决问题。制定应急方案,比如 AI 出了事故怎么沟通、怎么恢复服务。持续改进,保证它一直处在可控范围内。💡 示例: 你发现模型拒答率突然飙升,就要立刻排查最近的版本更新、回滚模型、通知用户,并调整策略防止再次发生。 |
扫描下方二维码,获取AI安全框架原文文档。
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
同专题推荐
查看专题壮丽人性:AI 时代如何守护人类尊严
2026 年 5 月,梵蒂冈发布了教皇利奥十四世的首份通谕《Magnifica Humanitas》,中文可以译作《壮丽人性》或《伟大的人性》。
五眼联盟对企业AI安全的劝告书
五眼联盟网络安全机构发布 Agentic AI 安全劝告书,核心不是反对企业使用 Agent,而是提醒组织必须在身份、权限、工具、上下文、审计和恢复等层面建立运行时安全基础设施。
AgentWard:高自主Agent全生命周期安全框架
AgentWard 提出面向自主 Agent 的五阶段生命周期安全架构,将初始化、输入、记忆、决策和执行分别纳入分层防护,并通过共享风险状态实现跨层联动。