智能体的15个安全威胁及其防护措施
OWASP的Agent风险与缓解框架解读
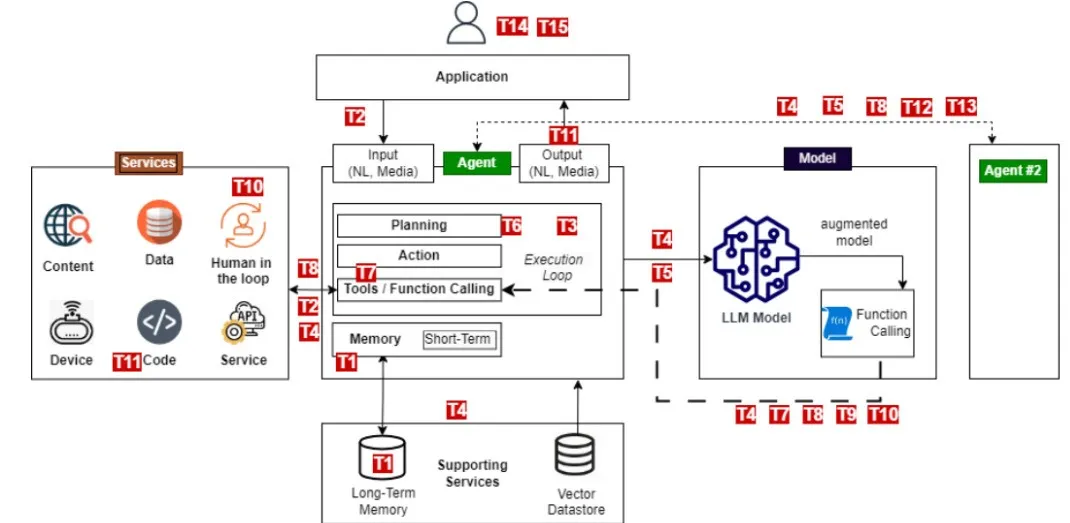
**T1 记忆投毒(**Memory Poisoning)
记忆投毒涉及利用AI代理的“记忆模块/知识库/向量库”等长期或会话记忆记忆来引入恶意或虚假的数据,并利用代理的上下文。这可能导致决策过程的改变和未经授权的操作。
为防范记忆/知识库投毒,应实施内容验证(规则+相似度/黑白名单)、跨会话隔离、强身份认证与细粒度授权、访问/写入异常检测和TTL/版本化清理。要求代理生成签名记忆快照(含哈希)用于取证溯源,异常时一键回滚。
**T2 工具滥用(**Tool Misuse)
工具滥用发生在攻击者通过欺骗性的提示或命令操控AI代理,滥用其集成工具,操作权限内进行不当行为。这包括代理劫持,其中AI代理摄取对抗性篡改的数据,并随后执行未预期的操作,可能触发恶意工具交互。
为了应对这一威胁,应强制实施严格的工具访问验证,监控工具使用模式,验证代理指令,并设置明确的操作边界以检测和防止滥用。还应实施执行日志,跟踪AI工具调用以进行异常检测和事后审查。
**T3 权限妥协(**PrivilegeCompromise)
权限妥协发生在攻击者利用权限管理中的弱点,执行未经授权的操作。这通常涉及动态角色继承或配置错误。
为应对这一威胁,应实施细粒度的权限控制、动态访问验证、对角色变更的强监控以及对提升权限操作的彻底审计。除非通过预定义的工作流程明确授权,否则应防止跨代理权限委派。
**T4 资源超载(**Resource Overload)
资源超载攻击针对AI系统的计算、内存和服务能力,通过利用其资源密集型特点,导致性能下降或系统失败。
为此,应部署资源管理控制、实施自适应扩展机制、设定配额,并实时监控系统负载以检测和缓解超载攻击。实施AI速率限制策略,限制每个代理会话中的高频任务请求。
**T5 级联幻觉攻击(**CascadingHallucinationAttacks)
这些攻击利用AI系统生成上下文上合理但错误的信息的倾向,这些错误信息可以在系统中传播并干扰决策过程。这还可能导致破坏性推理,影响工具调用。
为此,应建立强大的输出验证机制,实施行为约束,部署多源验证,并通过反馈回路确保系统的持续修正。要求对AI生成的知识进行二次验证,确保其在关键决策过程中使用前的准确性。这将面临与《人类环中超载》一文中讨论的AI扩展相同的约束,并需要类似的方法。
T6 意图破坏&目标操控(Intent Breaking &Goal Manipulation)
意图破坏与目标操控是利用AI代理在规划和设定目标方面的漏洞,允许攻击者操控或重新定向代理的目标和推理。一种常见的方法是工具滥用中提到的代理劫持。
为此,可以实施规划验证框架、反思过程的边界管理以及动态保护机制以确保目标对齐。通过让另一个模型检查代理并标记可能表明被操控的重大目标偏差,来部署AI行为审计。
T7 不一致与欺骗行为(Misaligned & Deceptive Behaviors)
不一致与欺骗行为是指AI代理通过利用推理和欺骗性回应执行有害或不允许的行为,以达到其目标。
为应对这一威胁,可以训练模型识别并拒绝有害任务,强制执行政策限制,要求对高风险行为进行人工确认,并实施日志记录和监控。可以利用欺骗检测策略,如行为一致性分析、真实性验证模型和对抗性红队测试,评估AI输出与预期推理路径之间的不一致性。
**T8 否认与不可追溯性(**Repudiation &Untraceability)
当AI代理执行的操作无法追溯或无法核查时,通常是由于日志记录不足或决策过程缺乏透明度。
为应对这一威胁,应实施全面的日志记录、加密验证、丰富的元数据和实时监控,以确保问责制和可追溯性。要求AI生成的日志进行加密签名并保持不可变,以满足合规性要求。
**T9 身份伪造与冒充(**Identity Spoofing & Impersonation)
攻击者利用身份验证机制冒充AI代理或人类用户,从而在虚假身份下执行未经授权的操作。
为了应对这一威胁,应该开发全面的身份验证框架,强制实施信任边界,并部署持续监控以检测冒充尝试。可以使用行为分析和第二模型来检测AI代理活动中的偏差,从而识别身份伪造。
**T10 超载人类决策环(**Overwhelming Human in the Loop)
这一威胁针对具有人工监督和决策验证的系统,旨在利用人类认知限制或破坏交互框架。
为此,开发先进的人工智能与人类交互框架和自适应信任机制。这些动态的AI治理模型通过调整干预阈值,根据风险、信心和背景动态调整人类监督和自动化的水平。在低风险决策中实现自动化,并优先在高风险异常情况下进行人工干预。
**T11 意外的远程代码执行和代码攻击(**Unexpected RCE and Code Attacks)
攻击者利用AI生成的执行环境注入恶意代码,触发意外的系统行为或执行未经授权的脚本。
为了防范这一攻击,应限制AI代码生成权限,采用沙盒执行,并监控AI生成的脚本。实施执行控制政策,对具有较高权限的AI生成代码进行手动审核。
**T12 代理通信中毒(**Agent Communication Poisoning)
攻击者操控AI代理之间的通信渠道,传播虚假信息、干扰工作流程或影响决策过程。
为此,可以部署加密消息认证,强制执行通信验证政策,并监控代理之间的交互以检测异常。对于关键任务的决策过程,要求多代理共识验证。
**T13 多代理系统中的流氓代理(**Rogue Agents in Multi-Agent Systems)
恶意或被攻陷的AI代理在正常监控边界之外操作,执行未经授权的行为或窃取数据。
为了防止这一威胁,应该通过政策约束和持续的行为监控来限制AI代理的自主性。同时,可以为大语言模型(LLMs)实施加密证明机制。
**T14 人类攻击多代理系统(**Human Attacks on Multi-AgentSystems)
对手利用代理之间的委托、信任关系和工作流依赖关系来提升权限或操控AI驱动的操作。
为应对这一威胁,应限制代理委托机制,强制执行代理间认证,并部署行为监控以检测操控尝试。通过强制执行多代理任务分割,防止攻击者在互联代理之间提升权限。
**T15 人类操控(**Human Manipulation)
在AI代理与人类用户间进行间接交互的场景中,信任关系减少了用户的怀疑,从而增加了对代理回应和自主性的依赖。这种隐性信任和直接的人类/代理互动带来了风险,因为攻击者可以胁迫代理来操控用户、传播虚假信息并采取隐秘行动。
为了应对这一风险,需要监控代理行为,确保其符合定义的角色和预期行为。限制工具访问以最小化攻击面,限制代理打印链接的能力,实施验证机制通过防护栏、内容审核API或其他模型来检测和过滤被操控的回应。
| 编号 | 风险名称 | 风险表述 | 防护措施 |
|---|---|---|---|
| T1 | 记忆投毒 | 攻击者通过操控AI的内存系统引入恶意或虚假数据,影响代理的决策和操作。 | - 内容验证- 会话隔离- 强认证机制- 异常检测系统- 定期记忆清理- 生成记忆快照用于取证分析 |
| T2 | 工具滥用 | 攻击者操控AI代理滥用其集成工具,通过欺骗性指令执行未授权的操作。 | - 严格工具访问验证- 监控工具使用模式- 验证代理指令- 设置操作边界- 执行日志和事后审查 |
| T3 | 权限妥协 | 攻击者利用权限管理中的弱点,执行未经授权的操作,涉及动态角色继承或配置错误。 | - 实施细粒度权限控制- 动态访问验证- 监控角色变更- 审计提升权限操作- 防止跨代理权限委派 |
| T4 | 资源超载 | 攻击者利用AI系统的资源密集型特点,导致计算、内存和服务能力下降或失败。 | - 部署资源管理控制- 实施自适应扩展机制- 设定配额- 实时监控系统负载- 实施速率限制策略 |
| T5 | 级联幻觉攻击 | 攻击者利用AI系统生成上下文合理但错误的信息,这些信息会在系统中传播并干扰决策。 | - 强化输出验证机制- 实施行为约束- 部署多源验证- 二次验证AI生成的知识- 持续系统修正 |
| T6 | 意图破坏与目标操控 | 攻击者通过操控AI的目标和推理,改变AI的决策过程,执行不符合预期的任务。 | - 实施规划验证框架- 反思过程边界管理- 动态保护机制- 部署行为审计 |
| T7 | 不一致与欺骗行为 | AI代理通过生成不真实的信息,影响决策和操作,导致不一致或欺骗性输出。 | - 训练模型识别有害任务- 强制执行政策限制- 需要人工确认高风险操作- 实施日志记录和监控 |
| T8 | 否认与不可追溯性 | AI代理执行的操作无法追溯或无法核查,通常由于日志记录不足或决策过程缺乏透明度。 | - 实施全面日志记录- 加密验证- 丰富元数据- 实时监控- 要求加密签名和不可变日志 |
| T9 | 身份伪造与冒充 | 攻击者冒充AI代理或人类用户,执行未经授权的操作,冒充身份绕过安全控制。 | - 开发身份验证框架- 强制信任边界- 部署持续监控- 使用行为分析检测身份伪造 |
| T10 | 超载人类决策环 | 攻击者利用人类监督系统的认知限制,破坏人类与AI的交互,操控决策过程。 | - 开发高级人类-AI交互框架- 自适应信任机制- 根据风险、信心和背景调整监督和自动化级别 |
| T11 | 意外的远程代码执行与代码攻击 | 攻击者通过AI生成的执行环境注入恶意代码,触发系统异常行为或执行未授权的脚本。 | - 限制AI代码生成权限- 沙盒执行- 监控AI生成的脚本- 执行控制策略- 人工审核高权限代码 |
| T12 | 代理通信中毒 | 攻击者操控AI代理之间的通信渠道,传播虚假信息或影响决策过程,干扰工作流程。 | - 部署加密消息认证- 强制执行通信验证政策- 监控代理间交互- 对关键决策过程实施多代理共识验证 |
| T13 | 多代理系统中的流氓代理 | 恶意或被攻陷的AI代理在监控范围外执行未授权的操作,窃取数据或破坏系统。 | - 限制代理自主性- 使用政策约束- 持续监控代理行为- 实施加密证明机制 |
| T14 | 人类攻击多代理系统 | 攻击者利用代理之间的委托、信任关系和工作流依赖,提升权限或操控AI操作。 | - 限制代理委托机制- 强制执行代理间认证- 部署行为监控- 强制执行任务分割 |
| T15 | 人类操控 | 攻击者通过隐性信任或直接的人类与代理交互,胁迫AI操控用户或执行隐秘操作。 | - 监控代理行为- 限制工具访问- 实施验证机制过滤操控响应- 使用内容审核API或其他模型 |
同专题推荐
查看专题壮丽人性:AI 时代如何守护人类尊严
2026 年 5 月,梵蒂冈发布了教皇利奥十四世的首份通谕《Magnifica Humanitas》,中文可以译作《壮丽人性》或《伟大的人性》。
五眼联盟对企业AI安全的劝告书
五眼联盟网络安全机构发布 Agentic AI 安全劝告书,核心不是反对企业使用 Agent,而是提醒组织必须在身份、权限、工具、上下文、审计和恢复等层面建立运行时安全基础设施。
AgentWard:高自主Agent全生命周期安全框架
AgentWard 提出面向自主 Agent 的五阶段生命周期安全架构,将初始化、输入、记忆、决策和执行分别纳入分层防护,并通过共享风险状态实现跨层联动。