当 Agent 开始处理秘密:机密计算正在成为 AI Agent 的底层安全边界
过去讨论 Agent 安全,我们更多关注提示注入、越狱、工具滥用、记忆投毒、权限越界。
过去讨论 Agent 安全,我们更多关注提示注入、越狱、工具滥用、记忆投毒、权限越界。
这些问题当然重要,但当 Agent 真的进入企业、政务、金融、医疗和研发环境后,安全问题会进一步下沉。
因为 Agent 不再只是回答问题。它会读取企业文档,保留长期记忆,持有 API Token,调用数据库,执行代码,访问 SaaS 系统,还可能把任务委派给另一个 Agent。也就是说,Agent 手里开始有了真正的秘密和真正的权限。
这篇论文《When Agents Handle Secrets: A Survey of Confidential Computing for Agentic AI》讨论的正是这个问题:当 Agent 开始处理秘密,现有的软件层护栏是否还足够?

https://arxiv.org/pdf/2605.03213
论文给出的判断很明确:只靠提示词规则、输出审核、函数调用限制和软件沙箱,无法覆盖 Agent 真实部署中的基础设施信任问题。机密计算 Confidential Computing,尤其是 TEE 和远程证明,正在成为 Agent 安全体系中必须补上的底层安全能力。
论文将 Agentic AI 定义为一种由 LLM 驱动、能够多步规划、调用外部工具、读写持久化记忆并与其他 Agent 协作的系统,而这类系统的威胁面已经明显不同于单次模型推理。
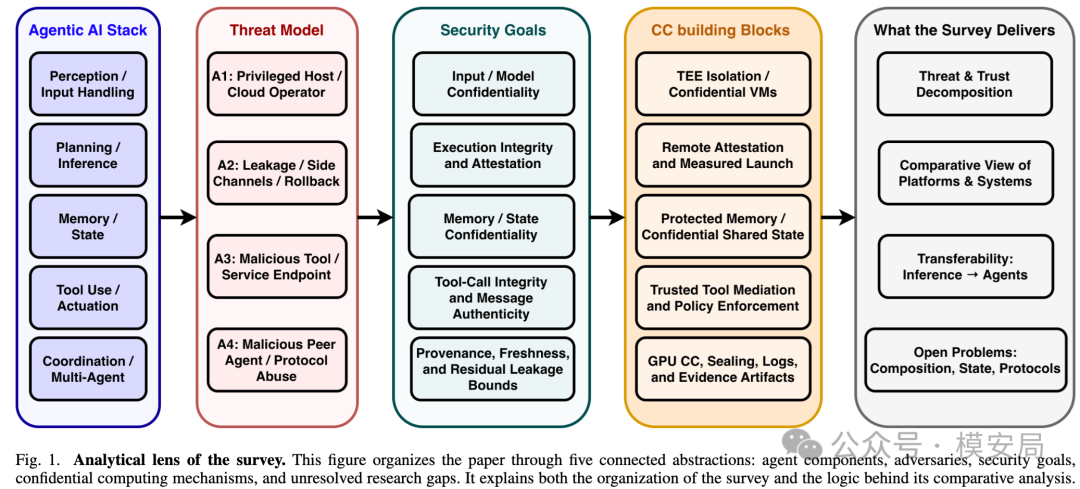
Agent 安全不能继续按普通云服务来理解
传统云服务当然也有凭证、容器、数据库、API 和权限控制。但 Agent 和普通微服务之间有一个关键差异:普通微服务的控制逻辑主要写在代码里,数据只是被处理的对象;Agent 的控制逻辑有很大一部分来自上下文。
在 Agent 系统里,用户输入、RAG 文档、工具返回结果、系统提示、历史对话、其他 Agent 的消息,都可能进入上下文窗口。模型会根据这些内容决定下一步调用什么工具、检索什么数据、委派什么任务、是否继续执行。
论文把这个问题说得很直接:在 Agent 中,LLM 本身就是控制平面,而这个控制平面会被数据语义操纵。恶意文档即使没有突破任何认证边界,只要被 Agent 检索进上下文,就可能改变 Agent 的工具调用和任务委派行为。
这也是提示注入在 Agent 场景中变得危险的原因。攻击者不一定需要偷 Token,也不一定需要攻破服务器。只要让 Agent 相信某段恶意指令属于当前任务的一部分,就可能让 Agent 合法地调用工具、读取数据、发起请求,甚至把敏感信息传到外部。
论文还指出,Agent 的授权边界往往是隐式的。传统微服务通过 API schema、鉴权、作用域化凭证来约束操作;Agent 的有效授权却常常隐藏在自然语言里,比如系统提示、用户指令和上下文历史。问题在于,模型并不能天然地区分“合法任务说明”和“攻击者注入的自然语言指令”。这使得 Agent 安全从传统的访问控制问题,变成了语义完整性问题。
同时,Agent 的状态也比普通服务更难管理。它会积累 KV cache、向量库、会话历史、长期记忆、微调适配器和工具调用记录。这些状态跨会话存在,边界并不总是清楚,泄露和投毒都会产生长期影响。论文把用户提示、检索文档、工具输入、模型权重、系统提示、运行时状态、服务凭证、工具调用参数、跨 Agent 消息、委派声明和远程证明证据,都视为 Agent 系统中的关键保护资产。
这意味着,Agent 安全不能只盯着“输入内容是否违规”和“输出结果是否安全”。更核心的问题会变成:
这个 Agent 到底运行在哪里?
它的代码和模型有没有被篡改?
它拿到的凭证是否只在可信环境中使用?
它调用工具的策略是否真的执行了?
它与其他 Agent 通信时,对方身份是否可证明?
它的长期记忆和检索结果是否被保护、可追溯、未过期?
这些问题,已经超出了传统内容安全护栏的覆盖范围。
机密计算要解决的是“运行时可信边界”
机密计算的核心目标,是保护 data in use,也就是数据在使用过程中的安全。
传统加密主要保护静态数据和传输中的数据。比如数据存储在磁盘上可以加密,网络传输可以用 TLS。但模型推理、工具调用、上下文拼接、向量检索、凭证使用,最终都要在内存和计算过程中发生。只要运行环境不可信,数据一旦进入 CPU、GPU、内存或容器,就可能被高权限攻击者看到。
TEE,也就是可信执行环境,试图提供硬件级隔离。它把代码和数据放在受保护的执行边界内,即使操作系统、Hypervisor 或云平台管理员拥有高权限,也不能直接读取或篡改其中内容。远程证明则负责回答另一个关键问题:远端用户或系统如何知道某个 Agent 真的运行在可信硬件里,并且运行的是预期代码、预期配置、预期补丁状态?论文认为,远程证明把本地隔离变成了分布式信任机制,验证方可以据此决定是否释放秘密、授权工具访问或接受委派结果。
这对 Agent 很关键。
因为 Agent 的安全不只是“模型本身有没有问题”,还包括整个运行链路是否可信。用户请求进入 Agent,Agent 调用模型,模型读取上下文,访问长期记忆,调用工具,写入外部系统,向其他 Agent 委派任务。任何一个环节如果暴露在不可信基础设施中,秘密和权限都可能被窃取或篡改。
所以这篇论文真正想推动的,不是简单把大模型放进 TEE,而是构建一套 Agent 的可信运行时边界。
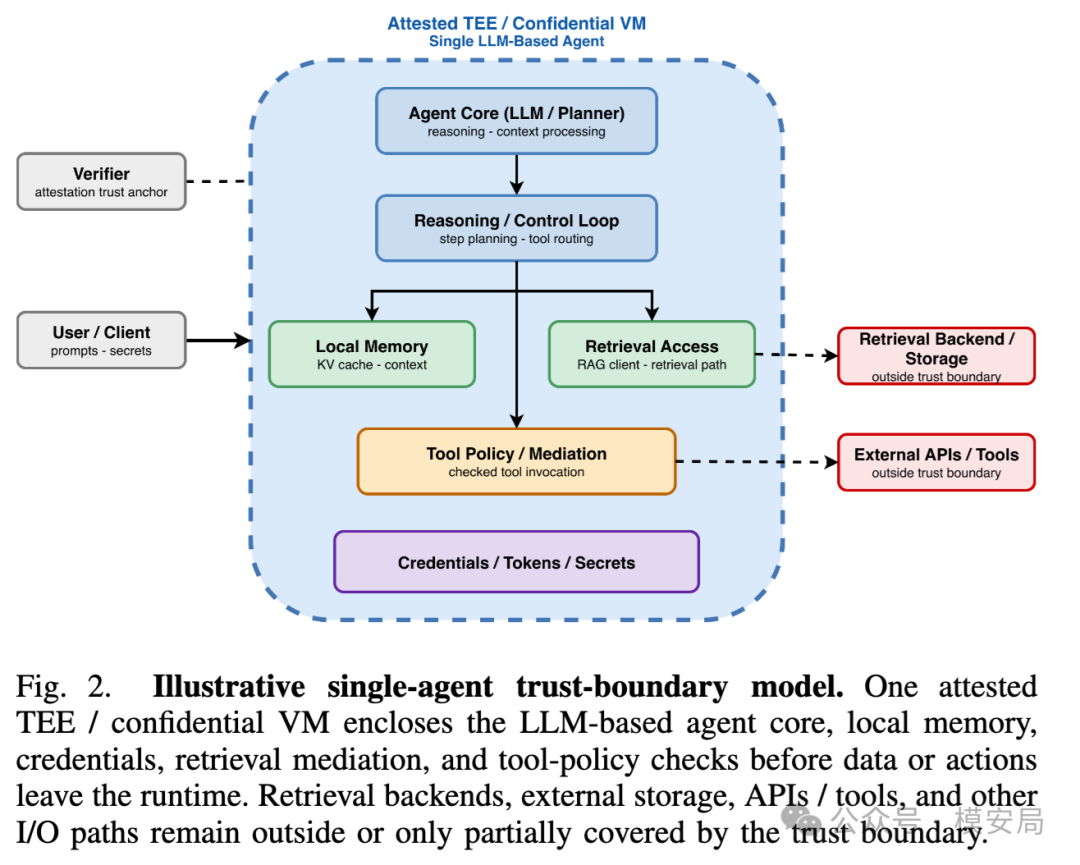
单次机密推理不等于 Agent 安全
目前很多机密计算方案主要关注 LLM 推理本身。比如保护用户输入不被云平台看到,保护模型权重不被窃取,保护推理过程不被篡改。这当然有价值,但它只是 Agent 安全的一小段。
Agent 真正复杂的地方在于,它不是一次输入、一次输出。它会多轮执行,会保存状态,会调工具,会连接外部系统,会让另一个 Agent 继续执行任务。
论文把 Agent 拆成五层:
感知层接收用户消息、检索文档、工具返回和跨 Agent 消息;
规划推理层由 LLM 生成计划和工具调用序列;
记忆层保存上下文、向量库、会话历史和模型参数;
行动工具层负责调用搜索、代码执行、数据库、文件系统和外部 API;
协作层则通过 MCP、A2A 等协议连接工具和其他 Agent。
这五层对应的安全目标也不一样。
感知层关心输入机密性,规划层关心模型机密性和执行完整性,记忆层关心 KV cache、长期记忆和向量库保护,行动层关心工具调用完整性,协作层关心消息真实性、来源可追溯性和证明时效性。
论文还专门强调了侧信道抵抗能力,因为即使数据在 TEE 中运行,时序、缓存、页错误、总线和 GPU 残留状态仍然可能泄露信息。
这套分层很重要。它提醒我们,保护 LLM 推理不等于保护 Agent 系统。一个系统即使能保证“模型推理时输入不泄露”,也可能在长期记忆、工具调用、MCP Server、跨 Agent 消息和外部 API 环节出现缺口。
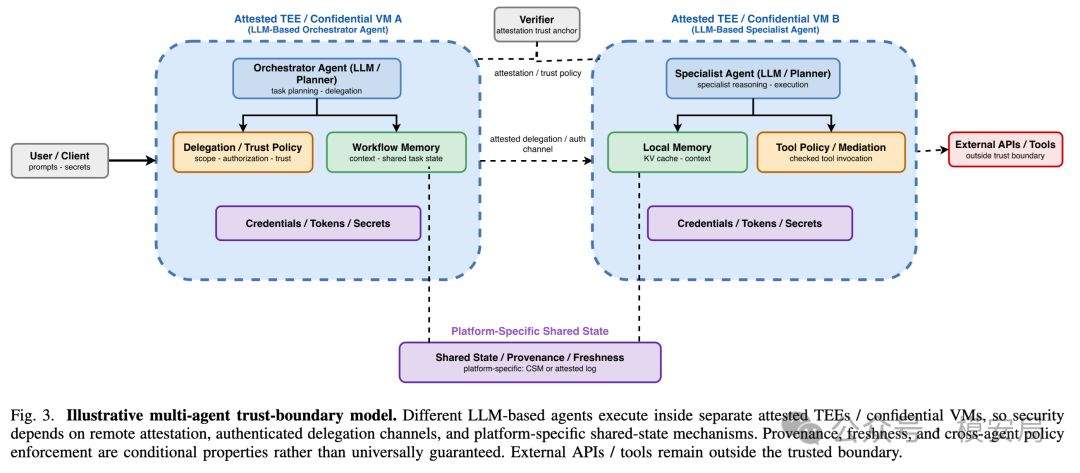
机密计算最擅长防谁,也最不擅长防什么
这篇论文把攻击者分成几类,其中最值得关注的是“高权限基础设施攻击者”。
普通应用层安全更多防外部攻击者,比如提示注入、恶意输入、恶意文档、恶意工具返回。但机密计算关注的是另一类更底层的威胁:云平台管理员、宿主机、Hypervisor、容器编排系统、同租户工作负载、被攻陷的工具服务和恶意协作 Agent。
如果攻击者控制了宿主机或云基础设施,传统软件护栏会非常脆弱。因为应用层策略再完善,底层高权限攻击者也可能直接读取内存、截获上下文、修改工具返回、窃取模型权重或替换运行代码。论文指出,现有的 prompt guard、输出分类器、函数调用沙箱和 Agent 隔离策略都运行在软件栈内;一旦攻击者处在更低层,这些机制可能被静默绕过。
TEE 对这类问题很有价值。它可以让用户或企业在释放敏感数据前,确认 Agent 运行在可信硬件环境中,运行的是预期代码和配置;也可以让工具服务确认调用方的身份和策略边界;还可以让多 Agent 协作中的每个节点提供可验证的执行证明。
但论文也非常清醒地指出,机密计算不是 Agent 安全的万能药。
TEE 可以证明“什么代码、什么模型、什么运行时正在可信硬件中执行”,却不能证明“这个 Agent 的目标是正确的”。如果 Agent 的任务定义本身有问题,或者被提示注入带偏,TEE 会忠实执行错误行为。远程证明也无法证明一个工具返回的内容是真的,无法证明一段检索文档没有恶意语义,无法证明模型不会幻觉,更无法解决对齐和语义鲁棒性问题。论文明确说,机密计算不是一般意义上的 Agent safety、模型鲁棒性或端到端可信系统的完整解决方案。
所以更准确的说法是:机密计算解决的是 Agent 的基础设施可信问题,不能替代提示注入防御、内容安全护栏、工具策略审计和模型行为评估。
它保护执行环境,不保证语义正确。
现有方案覆盖了哪里,缺口又在哪里
论文梳理了 TEESlice、CMIF、TEECHAT、Omega、AttestMCP、CAEC 和 BlockA2A 等代表性系统,并用覆盖矩阵分析它们分别保护 Agent 的哪些层。
从结果看,目前证据最充分的还是机密推理,也就是输入机密性、模型机密性和部分执行完整性。TEESlice、CMIF、TEECHAT 这类方案主要从单次推理或聊天服务出发,可以保护模型权重、用户输入和部分运行路径,但对工具调用、长期记忆和多 Agent 协调支持较弱。
真正接近 Agent 场景的是 Omega、AttestMCP、CAEC 和 BlockA2A。
Omega 更关注工具策略和执行检查,把 Agent 工具调用相关策略放到可信运行时中;AttestMCP 尝试把远程证明、消息真实性和来源追踪扩展到 MCP 风格的工具访问中;CAEC 关注多 Agent 之间的机密共享内存;BlockA2A 则用 TEE 加区块链审计平面来做跨组织协作中的可追责。
论文的 Table II 显示,工具调用完整性、消息真实性、来源追踪和新鲜性这些能力,在现有方案中仍然覆盖不均,长期记忆和侧信道问题也远未解决。

MCP 和 A2A 会把“可信协议”推到前台
这篇论文和 MCP/A2A 安全讨论高度相关。
Agent 接入工具后,安全问题不再只是“工具有没有权限”。还要看工具服务是否真实可信、能力声明是否可证明、消息来源是否可追溯、工具返回是否被篡改、多 Server 输出是否在上下文中混淆。
论文引用的 MCP 协议安全分析指出,MCP 存在几个底层问题:
缺少能力证明,导致 MCP Server 可以声称任意权限;
双向采样缺少来源认证,导致 Server 可以把消息注入 LLM 上下文;
多 Server 场景存在隐式信任传播,不同 Server 的输出混入同一个上下文窗口后,来源边界变得模糊。
相关实验在 847 个攻击场景中发现,MCP 架构选择会让提示注入成功率相对非 MCP 集成方式提升 23% 到 41%。
这说明,未来 MCP 安全不能停留在工具白名单和权限配置上。更合理的方向,是让工具服务能够提供可验证身份,让能力声明绑定硬件证明,让消息签名绑定被证明的发送方,让来源信息在多跳委派中持续保留。
AttestMCP 的意义就在这里。它把证明机制引入 MCP 风格的工具访问中,让客户端不仅知道“这个工具声称自己能做什么”,还要能验证“这个工具服务是否运行在可信环境中,是否具备对应能力,消息是否来自被证明的组件”。
论文认为,当前 MCP 和 A2A 规格本身还没有把远程证明、消息真实性、来源追踪和机密性作为协议级一等能力,而这恰恰是未来 CC-native Agent 通信协议需要补上的地方。
这对 Agent 安全产品有很强启发。
过去我们会说工具调用要做权限控制、参数校验、调用审计。以后还要进一步问:
MCP Server 的身份能否被证明?
工具能力声明能否被证明?
工具返回的内容能否带来源签名?
跨 Agent 委派链路能否保留完整 provenance?
远程证明是否新鲜,是否可能被重放?
当一个 Agent 信任另一个 Agent 时,这个信任能否继续传递?
这些问题会把 Agent 安全从“运行时策略”推向“可信协议”。
不同 TEE 平台不是谁取代谁,而是各自守住不同边界
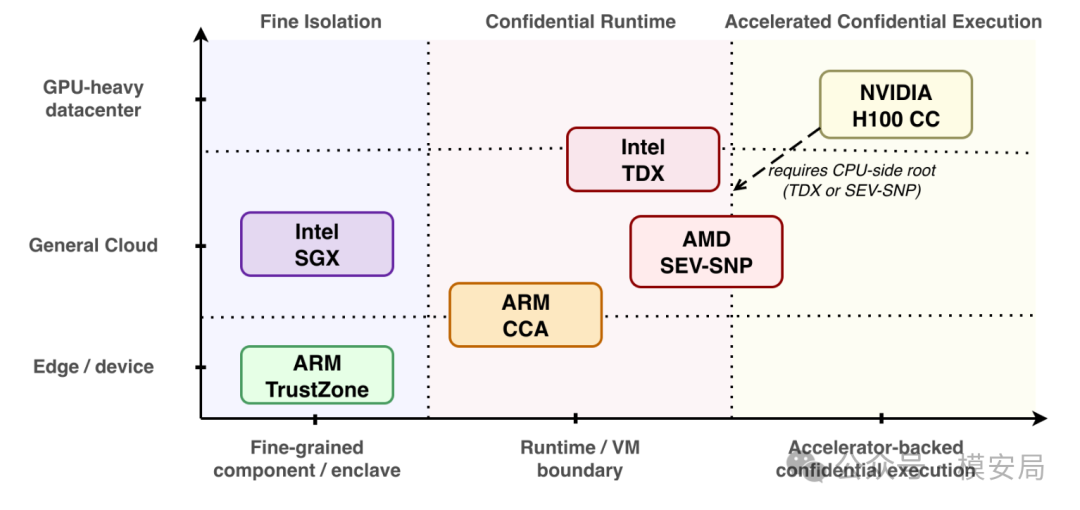
论文比较了 Intel SGX、Intel TDX、AMD SEV-SNP、ARM TrustZone、ARM CCA 和 NVIDIA H100 Confidential Computing。
这里容易出现一个误解:以为这些平台是简单的优劣关系。论文的观点更接近“部署分工”。
Intel SGX 更适合保护小而关键的组件,比如凭证处理、敏感推理片段、局部策略检查;Intel TDX 和 AMD SEV-SNP 更适合把整个 Agent 服务部署在机密虚拟机中,适合云端场景;ARM TrustZone 更常见于移动端、嵌入式和边缘设备;ARM CCA 引入 realm/CVM 模型,面向新的 Arm 机密虚拟化;NVIDIA H100 CC 则把机密计算边界扩展到 GPU 内存和执行过程,对大模型推理特别重要。
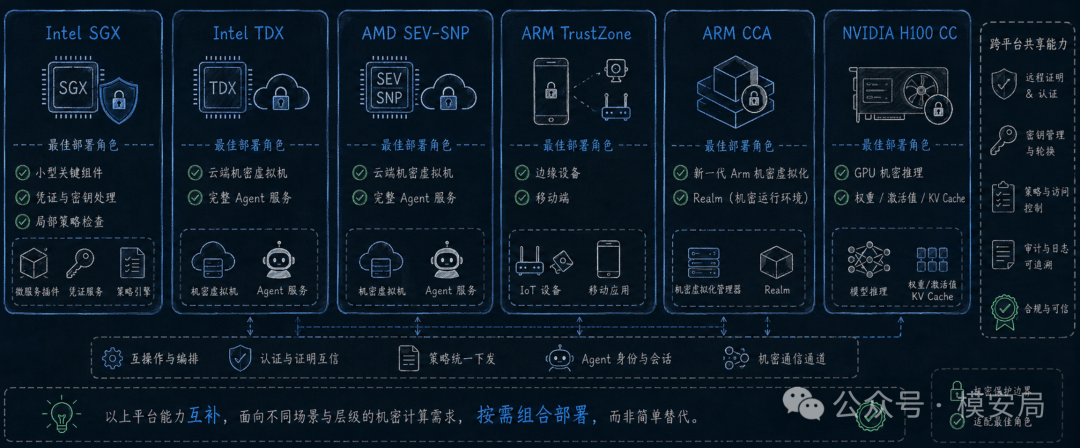
这很符合 Agent 的真实部署形态。云上 Agent 可能需要 TDX 或 SEV-SNP 来保护完整服务;大模型推理需要 H100 CC 保护权重、激活值和 KV cache;边缘 Agent 可能依赖 TrustZone 或 CCA;某些高价值组件则适合用 SGX 做细粒度保护。
论文还提醒,GPU 机密计算并不能单独构成端到端信任锚。比如 H100 CC 通常仍然需要 CPU 侧的 TDX 或 SEV-SNP 提供系统级可信根。换句话说,Agent 的可信边界需要 CPU、VM、GPU、I/O、工具协议和审计证据一起组合,不能只依赖某一个硬件能力。
六个开放问题
论文最后总结了六个开放问题。这部分非常重要,因为它说明 Agent 可信运行时还远没有成熟。

第一个问题是多跳 Agent 链路的复合证明。当前远程证明通常是一对一的,一个验证方验证一个 enclave。但真实 Agent 工作流可能是用户到编排 Agent,再到专家 Agent,再到工具服务器,每一跳都可能运行在不同 TEE 和不同硬件上。A 验证了 B,B 验证了 C,并不自动意味着用户可以信任 C。这里需要一种新的证明组合机制,同时处理执行完整性、来源、时效性、撤销、委派范围和链路验证。论文认为,当前 TEE 架构还没有原生支持这种多跳证明传递。
第二个问题是 TEE 支持的 RAG 和向量库隔离。长期向量库是 Agent 最敏感的资产之一,它保存用户历史、企业知识、检索上下文和大量隐私信息。但论文指出,目前部署中的机密计算框架还没有真正保护长期向量库。未来需要可以被远程证明的 TEE-backed vector store,让每次检索都受到证明、访问控制、来源和时效性约束,同时还要兼容 Faiss、pgvector 等现有向量数据库。
第三个问题是面向机密计算的 Agent 通信协议。MCP 和 A2A 现在还没有把远程证明、消息真实性、来源追踪、证明新鲜性作为协议级基础能力。未来的 Agent 协议需要让工具能力声明绑定硬件证明,让消息真实性绑定被证明的发送方,让来源信息在多跳委派中持续存在,并让通信机密性延伸到 TEE 边界。
第四个问题是自回归推理的侧信道泄露。LLM 是 token-by-token 生成,访问模式天然具有序列性。Transformer 注意力、KV cache 访问、speculative decoding 等过程,可能通过时序、缓存、页错误、总线或 GPU 残留状态泄露信息。论文指出,面向 LLM 推理模式的 TEE 侧信道研究还不系统。
第五个问题是 GPU TEE 在大模型规模下的性能。论文提到,现有报告中 H100 CC 的 GPU TEE 开销大约为 4% 到 8%,CCA 端侧推理开销大约为 22%,但这些数字依赖具体负载条件。更大模型、多 Agent 并发、共享 GPU、CPU-GPU 数据路径和高吞吐 Agent 流水线中的性能表现,还缺少完整画像。
第六个问题是合规证据化。监管真正需要的不是一句“我用了 TEE”,而是能证明哪个模型、哪个运行时、哪个工具策略、哪个硬件配置处理了受监管数据,哪些流程留在可信边界内,委派调用是否保留来源和策略一致性,是否存在过期证明或回滚状态。论文认为,现在还缺少标准化的证据包,把远程证明、执行完整性、来源追踪和时效性转化为可审计的部署保证材料。
启发
这篇论文对产品化的启发很明显。
过去大模型安全产品主要围绕输入输出做检测。用户问了什么,模型答了什么,是否涉政、涉黄、涉暴、违法违规、隐私泄露、歧视偏见,这是内容安全的基本盘。
到了 Agent 阶段,安全产品开始进入运行时。我们要看 Agent 调用了什么工具,参数是否异常,是否越权访问,是否被提示注入影响,是否写入长期记忆,是否把敏感数据发给外部 API。
而这篇论文进一步往下推进了一层:运行时本身是否可信。
如果 Agent 运行在不可信基础设施中,工具策略可能被绕过,凭证可能被宿主机读取,模型权重可能被窃取,长期记忆可能被快照,工具返回可能被中间层篡改。软件层安全策略再完整,也无法对抗更底层的高权限攻击者。
所以,未来 Agent 安全可能会形成三个层次。
第一层是内容安全,解决输入输出风险。
第二层是执行安全,解决工具调用、流程控制、权限边界和运行时审计。
第三层是可信基础设施,解决 Agent 运行环境、凭证使用、长期记忆、跨 Agent 通信和合规证据的可证明问题。
这三层不会互相替代。内容安全解决“说什么”,执行安全解决“做什么”,机密计算和远程证明解决“在哪里可信地做、由谁可信地做、做的过程能否被证明”。
从这个角度看,TEE 不只是云计算里的底层技术,它可能成为企业级 Agent 安全的关键组件。尤其是在金融、政务、医疗、研发、代码生成、AIOps、企业知识库和多 Agent 协同场景中,Agent 一旦接触敏感数据和真实权限,可信运行时就会从“高级选项”变成“准入条件”。
局限性
这篇论文是一篇综述,不是完整系统方案。它没有提出一个可以直接落地的端到端 Agent 安全平台,也没有证明机密计算能够解决所有 Agent 安全问题。
它真正有价值的地方,是把 Agent 安全中的“硬件信任边界”系统性拉了出来。
过去我们讲 Agent 安全,很容易陷入提示注入、越狱、工具调用这几个应用层问题。这篇论文提醒我们,一旦 Agent 开始处理秘密,真正的问题会变成一条完整链路:模型、上下文、记忆、凭证、工具、协议、协作节点、GPU、云平台、审计证据,都需要被纳入可信边界设计。
但它也反复强调,TEE 不能解决语义攻击。恶意文档依然可能影响模型判断,错误目标依然会被忠实执行,工具返回依然可能具有误导性,模型供应链投毒也不会因为放进 TEE 就自动消失。TEE 能证明运行环境,不能证明任务意图。
所以,这篇论文最适合得出的结论不是“机密计算会取代 Agent 护栏”,而是:
Agent 安全正在从内容护栏,走向运行时控制,再走向可证明的可信执行边界。
当 Agent 只负责聊天时,护栏已经足够重要。
当 Agent 开始调用工具时,运行时安全变得重要。
当 Agent 开始处理秘密和权限时,机密计算会变得重要。
未来企业不会只问:“这个 Agent 会不会乱说?”
还会问:“这个 Agent 运行在哪里?谁能看到它的上下文?谁能篡改它的工具调用?它的凭证是否只在可信环境中使用?它的协作链路能不能被证明?”
这就是这篇论文最值得关注的地方。
Agent 安全的下一步,可能不是再加一道输出审核,而是建立一套真正能被验证、能被审计、能跨工具和跨 Agent 传递的可信运行时。
同专题推荐
查看专题Anthropic 亲自下场做企业服务:当模型安全必须延伸到部署层
2025年5月,Anthropic宣布了一个令人意外的决定:联合黑石集团(Blackstone)、Hellman & Friedman和高盛(Goldman Sachs),成立一家独立的企业AI服务公司。
为什么对齐后的大模型仍会被越狱?拒答逃逸方向揭开模型安全的结构性缝隙
过去几年,大模型越狱研究大多在回答一个问题:什么样的 prompt 能绕过模型安全机制?