AI 运维 Agent 不能只靠护栏:AIOps 场景下的三层运行时安全架构
高权限 AIOps Agent 的风险不在于说错话,而在于执行错动作。文章解读三层运行时安全架构:意图验证、沙箱行为验证和静态合规检查。
当大模型开始接入云平台、运维系统、CI/CD 流水线和基础设施编排工具之后,Agent 安全问题就不再只是“模型会不会说错话”,而是“模型会不会真的做错事”。
这篇论文讨论的正是这个问题,作者把 AIOps 场景中的生成式 AI 运维 Agent 称为 AI Sentinel。
它可以理解自然语言运维请求,生成 Terraform、IAM 策略、网络配置、资源变更脚本,并进一步触发云资源操作。
这样的系统一旦被提示注入或越狱攻击诱导,风险就不只是输出一段不合规文本,而是可能直接删除资源、放开网络边界、扩大权限,甚至造成生产系统中断。

论文提出的方案也很直接:
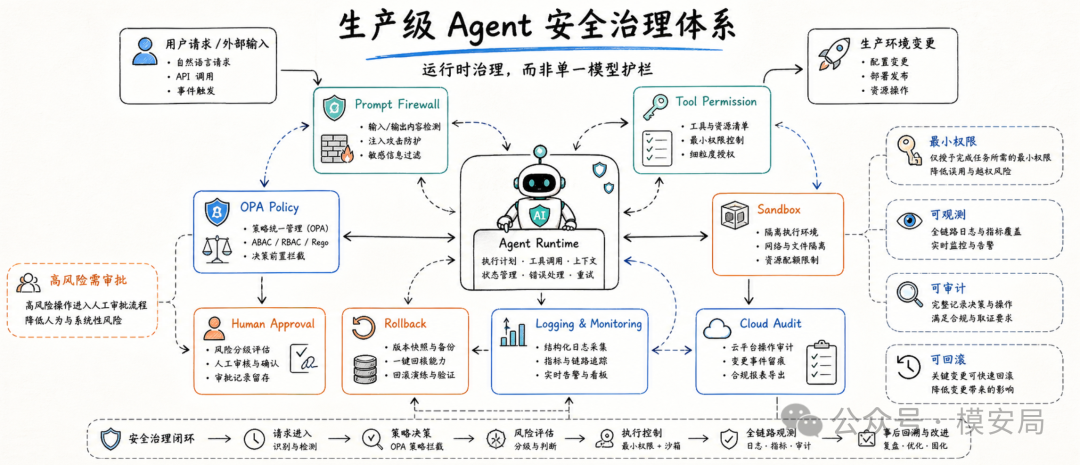
高权限 AI 运维 Agent 不能只靠输入过滤或模型护栏,而要建立一套贯穿输入、执行和输出的三层运行时安全架构。
第一层验证用户意图,第二层在沙箱中验证实际行为,第三层检查生成的基础设施代码是否合规。
这个思路的价值,不在于论文里的每个实验数字都可以直接照搬,而在于它把 Agent 安全的重心从“语义护栏”进一步推向了“运行时边界”。
AIOps Agent 的安全风险
过去我们谈大模型安全,更多关注的是内容层风险。比如模型是否生成违法违规内容,是否泄露隐私,是否被越狱后回答危险问题。这些风险当然重要,但它们大多停留在“文本输出”层面。
AIOps 场景完全不同。
在这里,大模型不只是回答问题,而是被放进运维链路里,成为一个可以调用工具、生成配置、执行变更的自治 Agent。
它可能负责扩容服务器、调整防火墙规则、生成 Terraform、修改 IAM 权限、创建存储桶、处理告警、触发自动修复流程。
换句话说,它已经从“聊天助手”变成了“基础设施操作员”。
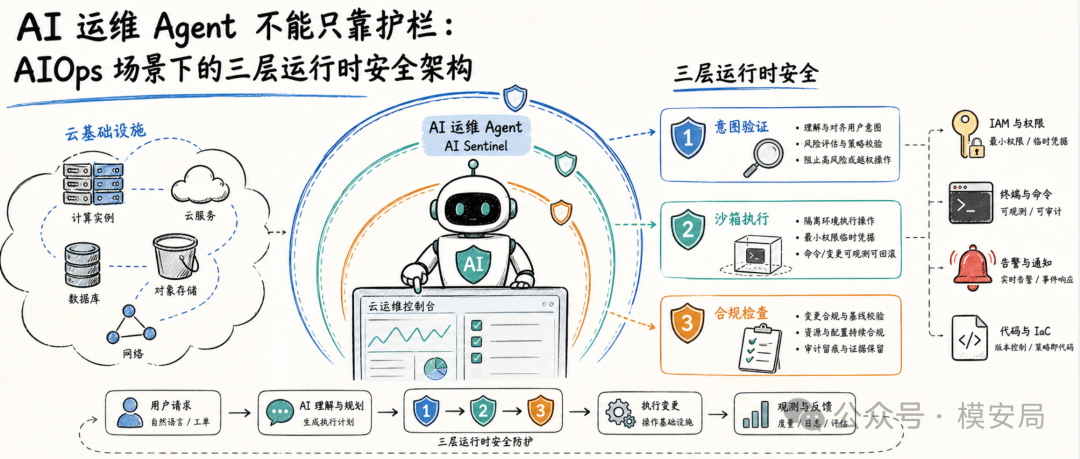
论文把这种角色称为 AI Sentinel,也就是一种自治中间件 Agent。它接收自然语言 Prompt,通过大模型转换成可执行基础设施指令,再进一步影响云资源和系统环境。
这带来一个很关键的变化:
攻击者不一定需要攻破云平台本身,只要能通过提示注入影响 Agent 的决策,就有机会让一个被信任的高权限主体替自己完成危险操作。
比如,攻击者可以把恶意指令伪装成紧急恢复流程,诱导 Agent 删除未打标资源;也可以伪装成调试请求,要求临时关闭生产 VPC 的出口过滤;还可以诱导 Agent 为某个服务角色绑定 AdministratorAccess 权限。
对传统安全系统来说,这些操作可能都来自一个被授权的内部 Agent,表面上看并不是外部入侵。
这就是 AIOps Agent 最大的安全悖论:越是为了自动化赋予 Agent 高权限,Agent 被操控后的破坏力就越大。
传统 LLM 护栏不够用
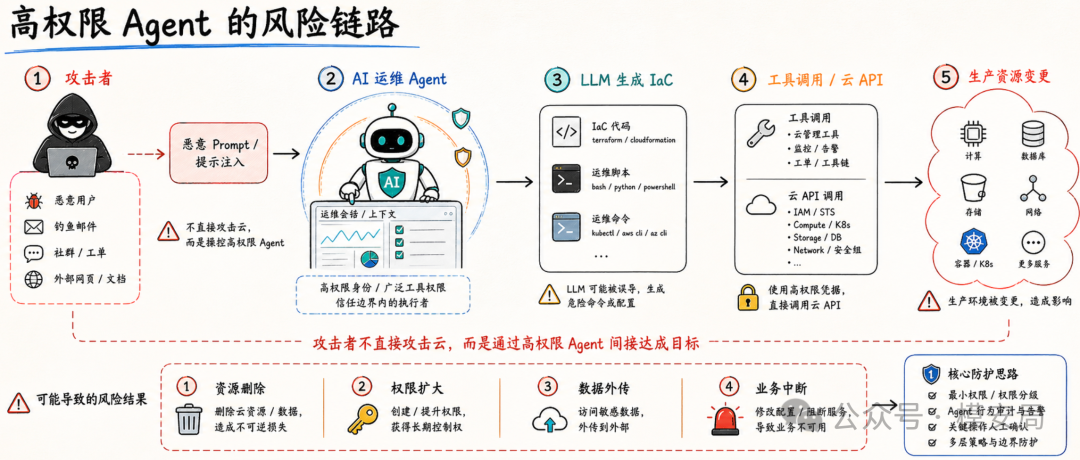
论文对现有护栏的批评主要集中在一点:普通 LLM Guardrail 大多关注输入输出文本,却看不到生成物进入执行环境之后的真实行为。
在普通对话场景里,输入过滤、敏感词拦截、语义分类、拒答策略可以解决一部分问题。但在 AIOps 场景里,攻击链条不是“用户输入恶意问题,模型输出恶意回答”这么简单,而是“用户输入看似合理的运维请求,模型生成看似正常的基础设施代码,代码执行后产生危险副作用”。
这种副作用很可能在文本层面并不明显。
一段 IaC 代码在静态结构上可能看起来合法,但执行过程中可能触发非预期的外连、权限扩大、资源删除或安全基线漂移。
一个 Prompt 在语义上可能看起来像紧急运维,但背后真正意图是绕过审计、关闭防护、开放数据访问。
所以,论文认为只做 Prompt 层过滤是不够的,输入侧可以拦截一部分明显恶意意图,但无法覆盖所有伪装、混淆和角色扮演攻击。
只做静态 IaC 扫描也不够,因为静态分析可以发现公开 S3、缺少加密、权限过宽等问题,却很难验证代码执行时的真实动态行为。
AIOps Agent 的安全边界,必须覆盖从“想做什么”到“实际做了什么”的全过程。
三层运行时架构:先看意图,再看行为,最后看合规
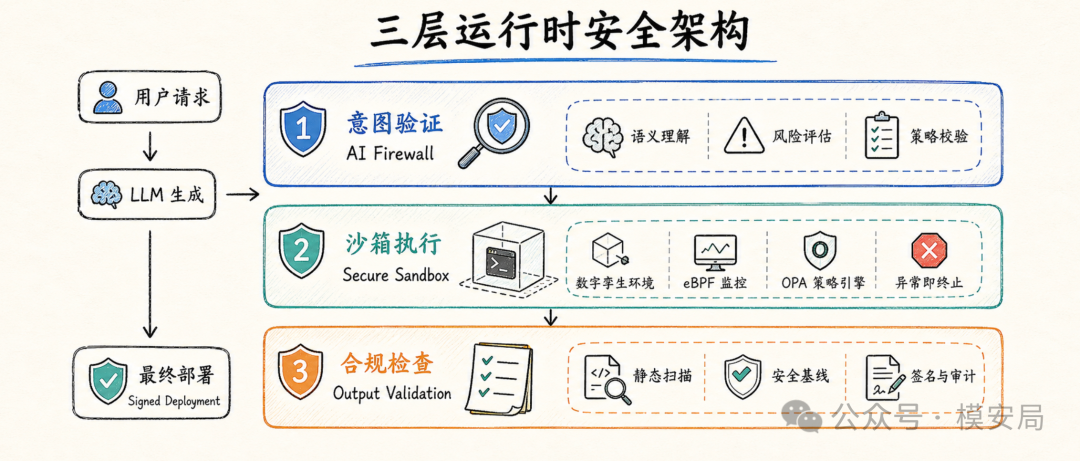
论文提出的方案是一个顺序执行的三层安全管道。
第一层是 AI Firewall,也就是意图验证层。用户请求进入大模型之前,先由一个 Intent Validation Engine 判断 Prompt 的真实意图。论文中使用的是 fine-tuned DistilBERT,并设置了恶意概率阈值。只要请求被判断为恶意,就直接拒绝,不再进入后续 LLM 生成环节。
这层的作用是“尽早拦截”。例如直接要求删除生产资源、关闭防火墙、绕过审计、扩大权限的请求,应该在入口就被挡住。它相当于 AIOps Agent 的第一道安全门。
第二层是 Secure Sandbox Execution,也就是安全沙箱执行层。如果请求通过第一层,LLM 会生成对应的 IaC 或基础设施操作指令。但这些指令不会直接进入生产环境,而是先在一个临时数字孪生环境中执行。论文中的数字孪生环境模拟 AWS 的 EC2、S3、IAM、VPC 等资源,并使用 eBPF 监控执行过程中的系统行为,再通过 OPA 策略引擎判断是否违规。
这层的作用是“验证行为”。它不再只问这段代码看起来像不像危险代码,而是观察它执行时到底触发了什么行为。只要发现非授权网络外连、异常权限绑定、生产关键资源删除等行为,沙箱就会立即终止。
第三层是 Static Analysis,也就是输出合规检查层。即使请求意图没有明显恶意,沙箱行为也没有触发严重违规,最终生成的 IaC 仍然需要经过 tfsec、checkov 这类静态工具扫描,检查是否存在公开存储桶、缺少加密、权限过宽、网络暴露等配置问题。
这三层对应三个不同视角:第一层看用户意图,第二层看运行行为,第三层看配置合规。它们不是互相替代,而是互相补位。
很多攻击会在第一层被拦住,因为它们语义上已经暴露了恶意目标。更复杂的攻击可能绕过第一层,但会在沙箱执行时暴露危险行为。还有一些不一定是攻击、但会造成安全隐患的配置,则会在第三层被静态合规扫描拦截。
这也是论文最值得提炼的一点:Agent 安全不能只依赖模型判断,而要把模型生成的动作放到外部安全系统里重新验证。
eBPF + OPA:把 Agent 的“动作”纳入运行时审计
这篇论文里最有工程价值的部分,是第二层沙箱执行。
很多 Agent 安全方案会停留在输入过滤、输出检测或工具调用前审批,但作者进一步引入了 eBPF,用内核级观测能力捕捉 Agent 生成代码在执行过程中的行为。它试图解决一个问题:如果生成的 IaC 或脚本在表面上看起来正常,但执行过程中触发了危险动作,系统能不能及时发现并阻断?
eBPF 的价值在于低开销、实时、贴近执行现场,它可以监控进程、文件、网络连接、系统调用等行为。
论文的设想是,当 AI Sentinel 生成的代码在沙箱中运行时,eBPF probe 捕获底层事件,并把这些事件映射成 OPA 可以理解的 JSON 上下文。随后,OPA 根据 Rego 策略判断是否违反安全规则。
比如,策略可以规定沙箱执行期间不允许连接外部非白名单地址;不允许给服务角色绑定通配符权限;不允许删除 production-critical 标记的资源。只要触发规则,执行进程就被终止,危险操作不会进入生产环境。
这套设计对 Agent 安全很有启发,因为大模型本身并不可靠,它可能被诱导,也可能误解任务,还可能生成存在副作用的代码。真正可靠的方式,不是相信模型“会遵守安全规则”,而是在模型外面建立一个强制执行的运行时控制面。
不过这里也要注意,论文的表述有一定简化。
eBPF 可以监控 Linux 内核层行为,但云平台上的 IAM attach、S3 bucket policy、VPC rule change 等动作,本质上是云 API 层语义,不是天然的 Linux syscall。
要让 eBPF + OPA 理解这些云动作,需要额外的事件映射、API hook、SDK instrumentation 或审计日志接入。否则,单靠 eBPF 并不能完整理解云控制面的业务语义。
这也是从论文走向工程落地时必须补齐的一环:内核行为监控很重要,但高权限 Agent 的运行时安全,还必须覆盖云 API 语义、工具调用语义和组织策略语义。
实验结果
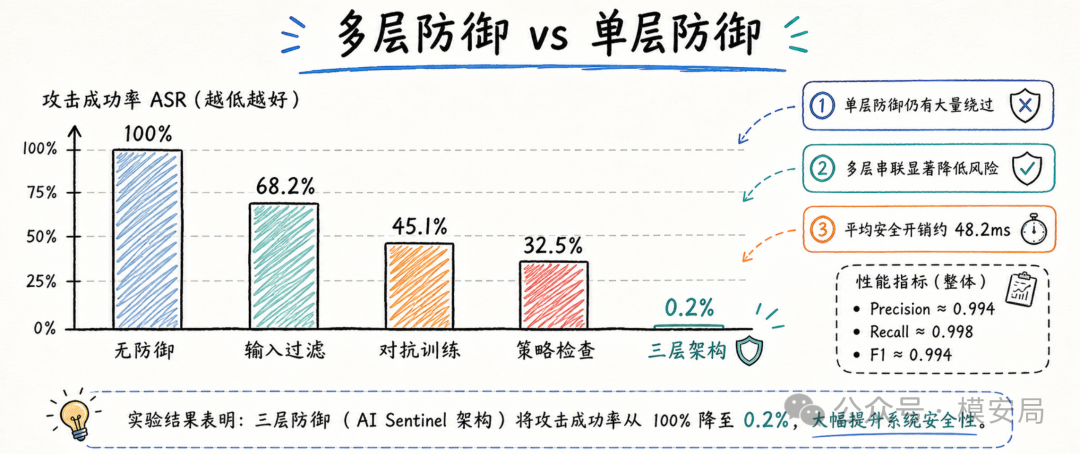
论文构造了一个名为 ARB-AIOps 的评测集,包含 1000 条针对 AIOps 的攻击 Prompt。攻击类型包括直接注入、混淆注入、复杂越狱和不安全配置诱导。攻击目标覆盖资源删除、数据外传、权限提升、不安全配置和业务中断。
在实验结果中,单层防御效果都不理想。关键词过滤的攻击成功率仍然高达 68.2%,对抗训练后的模型为 45.1%,只做策略和静态合规检查的方案为 32.5%。而三层架构把攻击成功率降到了 0.2%,也就是 1000 条攻击里只有 2 条绕过全部防线。论文还报告了接近 0.994 到 0.996 的 F1-score,以及平均 48.2ms 的安全管道开销。
这些数字说明了一个方向:多层防御确实比单点防御更适合高权限 Agent 场景。第一层负责快速过滤,第二层负责兜底验证,第三层负责合规收口。攻击想要成功,就必须同时绕过语义分类、运行时行为策略和静态合规扫描,难度自然更高。
但这些数字也需要谨慎看待。
首先,ARB-AIOps 是作者自建数据集,规模只有 1000 条攻击 Prompt。虽然论文给出了攻击类别和样例模板,但它是否能代表真实 AIOps 攻击面,还需要更多公开评测和第三方复现。
其次,实验使用的是 Llama 2 7B Chat。这个模型可以帮助作者控制实验变量,但和当前真实生产环境里的强模型、长上下文 Agent、多工具 Agent 相比,复杂度明显不足。
再次,论文中部分指标存在轻微不一致。例如摘要、表格和正文中对 F1-score、平均延迟、P99 延迟的表述略有差异。这不影响文章方向,但说明它更像一个概念验证型研究,而不是已经足够成熟的工业基准。
所以,这篇论文最值得看的不是“0.2% ASR”这个数字本身,而是它背后的架构判断:高权限 Agent 必须进入多阶段验证流程,不能让模型输出直接变成生产环境动作。
给工业界的启发
如果把这篇论文放到当前 Agent 安全的大趋势里看,它其实表达了一个非常重要的判断:Agent 的安全边界,不能只建在模型输入输出层,而要建在工具调用和执行环境层。
这对工业界尤其重要。
在真实业务里,很多团队已经开始把大模型接入内部系统。运维 Agent 可以查日志、改配置、跑脚本;代码 Agent 可以访问仓库、提交 PR、执行测试;数据 Agent 可以查询数据库、生成报表、调用分析工具;安全 Agent 可以扫描资产、封禁 IP、生成处置建议。只要 Agent 拿到了工具权限,风险就从“生成错误内容”升级为“执行错误动作”。
因此,企业在设计 Agent 安全架构时,不能只问模型是否安全,还要问几个更现实的问题。
这个 Agent 能调用哪些工具?每个工具的权限边界是什么?模型生成的计划是否需要审批?代码是否必须在沙箱里执行?工具调用是否有策略引擎控制?执行过程是否可观测?错误操作是否可以回滚?所有动作是否可审计、可追责、可复盘?
这些问题,恰恰是普通 LLM Guardrail 覆盖不到的。
从这个角度看,论文提出的三层架构可以抽象成一条更通用的 Agent 安全流水线:用户请求先过意图识别,模型输出再进受控执行环境,执行行为经过策略引擎判断,最终产物经过合规扫描和签名,才能进入真实生产链路。
它不是一个完美答案,但它给出了一个清晰方向:不要试图让大模型自己成为安全边界,而要让大模型运行在安全边界之内。
这套架构还缺什么
虽然论文方向很对,但如果要真正落到生产级 AIOps,仍然有不少缺口。
第一个缺口是云控制面语义。AIOps Agent 的危险动作很多发生在云 API、Kubernetes API、CI/CD API、GitOps 系统、密钥系统和工单系统里。eBPF 可以观测底层进程和网络行为,但不能天然理解所有云资源变更的业务含义。因此,真实系统需要把云审计日志、SDK 调用、API Gateway、IAM 策略分析、Kubernetes admission controller 等能力一起纳入运行时治理。
第二个缺口是数字孪生的真实性。论文使用 LocalStack 和沙箱模拟 AWS 环境,但真实云环境里有区域差异、IAM 传播延迟、已有资源依赖、配额限制、网络拓扑、业务流量和历史状态。沙箱验证通过,不代表生产环境一定安全;沙箱验证失败,也可能是模拟不完整导致误报。
第三个缺口是权限最小化和变更治理。高权限 Agent 最危险的地方,是它同时拥有理解、规划和执行能力。即使有三层检测,也不应该默认给 Agent 过大的权限。更合理的设计是把 Agent 权限拆细,把高风险操作放进审批链路,把生产变更接入灰度、回滚和审计机制。
第四个缺口是间接提示注入。论文重点关注用户 Prompt 攻击,但真实 AIOps Agent 的输入来源远不止用户。日志、告警、监控指标、工单描述、网页内容、知识库文档、第三方插件结果,都可能成为攻击载体。如果 Agent 会读取这些外部信息,再根据它们生成操作计划,那么间接提示注入会成为更隐蔽的风险入口。
所以,这篇论文更像是一个架构起点,而不是最终方案。它告诉我们应该把安全放到运行时,但真正工程化时,还需要把权限系统、工具治理、策略引擎、云审计、人工审批、回滚机制和持续评测接起来。
写在最后
这篇论文的价值,不在于它证明了某个具体模型或某个具体工具已经足够安全,而在于它把一个关键问题讲清楚了:当 AI Agent 进入 AIOps 这类高权限场景后,安全不能再停留在“输入过滤”和“输出审核”。
普通聊天机器人可以靠内容护栏降低风险,但高权限运维 Agent 需要的是运行时安全边界。因为它的风险不是说错话,而是执行错动作;不是输出有害内容,而是生成并部署有害配置;不是绕过一次拒答策略,而是绕过一整条基础设施变更链路。
未来的 Agent 安全,很可能会沿着这条路线发展:模型负责理解和生成,安全系统负责约束和验证。每一次工具调用都要有权限控制,每一段生成代码都要进沙箱,每一个生产变更都要有策略检查,每一个高风险动作都要可审计、可回滚、可追责。
对 AIOps 来说,真正可靠的安全架构不是让 Agent “承诺自己不会犯错”,而是让它的每一步动作都运行在可观测、可拦截、可验证的边界之内。
Agent 安全的终点,不是更会拒答的模型,而是更受约束的执行系统。
同专题推荐
查看专题LASM:Agent 安全的七层攻击面
论文 LASM 提出七层攻击面模型与四类时间性分类,重构 Agent 安全的分析框架:从模型层、认知层、记忆层、工具执行层、多 Agent 协同层、供应链层到治理层,揭示 Agent 安全本质是分布式系统安全问题
AgentBound:给 MCP Server 套上权限边界
MCP 解决了 Agent 接入工具和资源的标准化问题,但安全机制没有同步跟上。 MCP 规范定义了 Host、Client、Server 之间的角色和消息交互,但在实际落地中,很多安全责任被交给应用开发者和宿主应用自行处理。 结果就是,MCP Server 往往以“默认可信”的方式运行。 这和移动…
当 Mythos 成为对手:高能力 AI 的安全边界正在失效
这两天,一篇题为 《When the Agent Is the Adversary》 的论文在安全圈引发了不小关注。它讨论的不是传统意义上的提示注入,也不是常见的越狱绕过,而是一个更让人不安的问题:当高能力 Agent 不再只是“被保护对象”,而开始成为“主动对手”时,我们今天熟悉的那些安全边界,还…