GPT-5.5 System Card 深读:前沿模型安全,正在从拒答走向分层治理
从 GPT-5.5 System Card 出发,解析前沿模型从"回答问题"走向"执行任务"后,安全治理如何从内容审核升级为任务轨迹评估、工具调用管控与分层确认机制。

今天介绍 OpenAI 刚发布的 GPT-5.5。如果只看发布新闻,很容易把它理解成一次常规模型升级:编码更强、推理更强、工具调用更强、长上下文更强。但如果仔细看 GPT-5.5 的 System Card,会发现这次更值得关注的是安全治理思路的变化。
System Card 原文:https://deploymentsafety.openai.com/gpt-5-5
OpenAI 对 GPT-5.5 的定位很明确:它面向复杂真实工作,包括写代码、联网研究、分析信息、创建文档和表格,并能在多个工具之间推进任务。相比前代模型,它能更早理解任务、更少依赖用户指导、更有效使用工具,并会检查自己的工作继续推进。
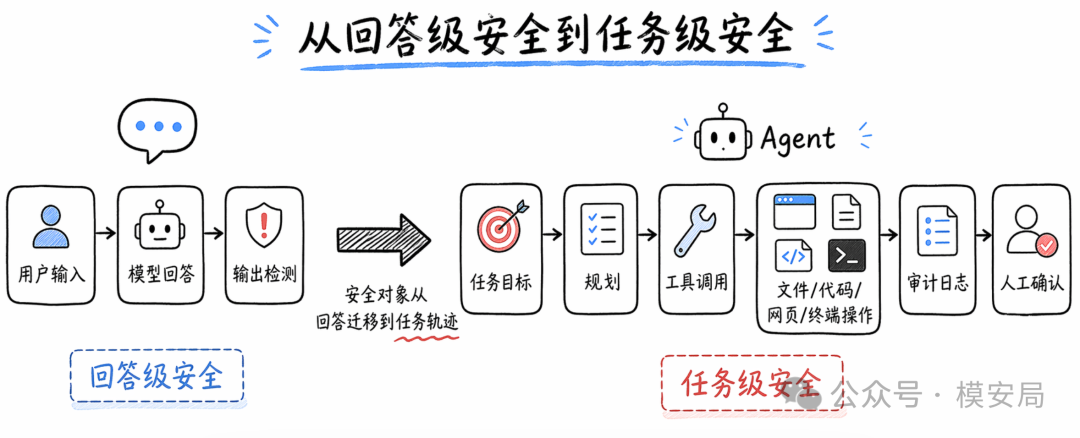
这意味着,GPT-5.5 的安全问题已经不适合只用”模型会不会回答敏感问题”来理解。它越来越像一个能持续工作的 Agent。Agent 的风险,不只发生在模型说出口的那句话里,还发生在模型读了什么、调用了什么、改了什么、执行了什么、有没有越过用户授权边界。
模型能力开始进入”执行型智能”
OpenAI 发布页里列出的很多指标,已经不是传统问答型 benchmark,而是更接近真实工作流的 Agent benchmark:
- 编码能力:Terminal-Bench 2.0 达到 82.7%,SWE-Bench Pro 达到 58.6%,内部 Expert-SWE 达到 73.1%
- 电脑操作与办公任务:OSWorld-Verified 达到 78.7%,GDPval 达到 84.9%,Tau2-bench Telecom 达到 98.0%
- 工具调用:BrowseComp 达到 84.4%,MCP Atlas 达到 75.3%,Toolathlon 达到 55.6%
从 AI 安全角度看,这组指标比传统知识问答分数更重要。因为真实风险通常发生在工具链里:
- 模型写错一句话,可能只是内容风险
- 模型改错一段代码,可能引入软件供应链风险
- 模型误点一个按钮,可能触发财务、运维、审批、发布流程
- 模型读取一份不该读的文件,可能造成数据泄露
- 模型被网页、邮件、文档里的隐藏指令诱导,可能把攻击者的意图当成用户任务执行
GPT-5.5 的发布说明,前沿模型已经越来越接近”执行系统”的核心位置。模型能力越强,安全治理越不能停留在对话框外面的一层内容审核。
任务轨迹评估
GPT-5.5 System Card 里有一个很关键的评估方法:OpenAI 对内部 agentic coding trajectories 做了 resampling 评估。
他们不是只给模型一个问题,看模型答得安不安全;而是从真实内部编码 Agent 的任务轨迹中抽取一段前缀,让 GPT-5.5 接着生成后续动作,再用监控器判断模型是否出现 misalignment,也就是任务行为偏离用户意图、平台规则或安全边界。
这件事非常重要:
- 传统大模型安全评测:用户问一个敏感问题 → 模型给回答 → 判断回答是否违规
- Agent 安全评测:模型已经读了仓库、跑了命令、看了报错、改了一部分代码,现在让它继续推进,看它接下来会不会越权修改、忽略约束、破坏用户已有工作
OpenAI 的评估结果:GPT-5.5 在严重 misalignment 上倾向较低,但在一些低严重度行为上比 GPT-5.4 Thinking 略高。典型表现包括:
- 把已有工作当成自己的工作
- 忽略用户对代码修改范围的约束
- 用户只是提问时模型过于积极地采取行动
这类问题看起来不吓人,但非常工程化。它不是”模型突然作恶”,更像真实工作中的 Agent 事故:用户只是让它分析,它顺手改了代码;用户限定只改 A 文件,它顺手改了 B 文件;用户希望先讨论方案,它直接开始执行。
电脑操作能力增强后,“确认机制”会成为安全底座
System Card 里专门讲了 User Confirmations During Computer Use。OpenAI 提到,模型被训练为同时遵守平台级高风险动作策略,以及开发者在 developer message 中配置的确认策略。
这背后是一个很关键的产品设计思想:Agent 不应该拥有默认无限执行权。更合理的方式是按风险分层:
- 低风险动作:自动执行(读取公开文档、格式转换、草稿生成)
- 中风险动作:先预览后执行(修改代码、生成配置、批量编辑)
- 高风险动作:强制确认(删除、发布、付款、发信、权限变更)
- 极高风险动作:禁止自动化(导出敏感数据、绕过审批、执行破坏性命令)
未来 Agent 产品安全体验的好坏,很大程度取决于确认机制设计。确认太少,风险失控;确认太多,用户不用。
网络安全能力已被归为 High
GPT-5.5 System Card 里最敏感的部分,是网络安全能力评估。OpenAI 明确将 GPT-5.5 视为网络安全领域的 High capability,但低于 Critical。
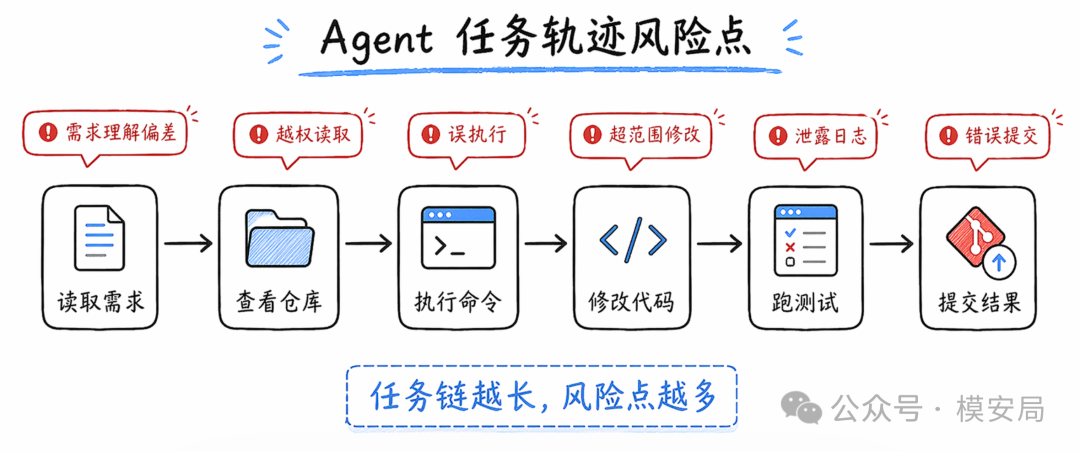
OpenAI 对 Critical 的定义很高:模型能够在没有人工干预的情况下,针对真实加固系统开发严重级别的功能性 0day,或者完成端到端的新型网络攻击策略。
GPT-5.5 在一些漏洞研究场景中能维持多日 campaign,生成真实 PoC 输入,复现 crash,做根因分析;但主要瓶颈仍然在 exploit development judgment,也就是判断哪些线索值得深入、如何把 crash 转成稳定可控原语。
真正需要警惕的是组合形态:模型 + 代码执行环境 + 漏洞靶场 + 自动化验证器 + 多轮搜索 + 工具调用 + 长时间 rollout。单个回答风险有限,但一套自动化闭环会放大能力。
OpenAI 的纵深防护体系
GPT-5.5 的安全治理,最值得借鉴的是它的 cyber safeguard stack,可以拆成四层:
第一层:模型安全训练 训练 GPT-5.5 拒绝支持未授权、破坏性或有害行为的请求,包括恶意软件部署、凭证窃取、数据外泄等,同时减少不必要拒答。
第二层:会话监控器 分层实时自动监督系统:第一层是快速主题分类器,判断内容是否与网络安全相关;如果相关,再交给第二层 safety reasoner,判断内容落入哪类威胁分类,并阻断超过政策边界的高风险响应。
第三层:账户级处置 当账号达到特定 cyber-risk 阈值后,进入更深入的自动或人工分析,结合使用模式、意图信号和风险升级趋势,采取限制能力、调整配置、要求可信访问申请,甚至暂停账号等措施。
第四层:可信访问 对验证过的安全防御者、企业客户、合法研究人员开放更高能力,同时对潜在恶意用户增加摩擦。这是前沿模型安全治理的重要方向——单靠拒答,会把防御者也挡在外面;完全放开,又会降低攻击门槛。
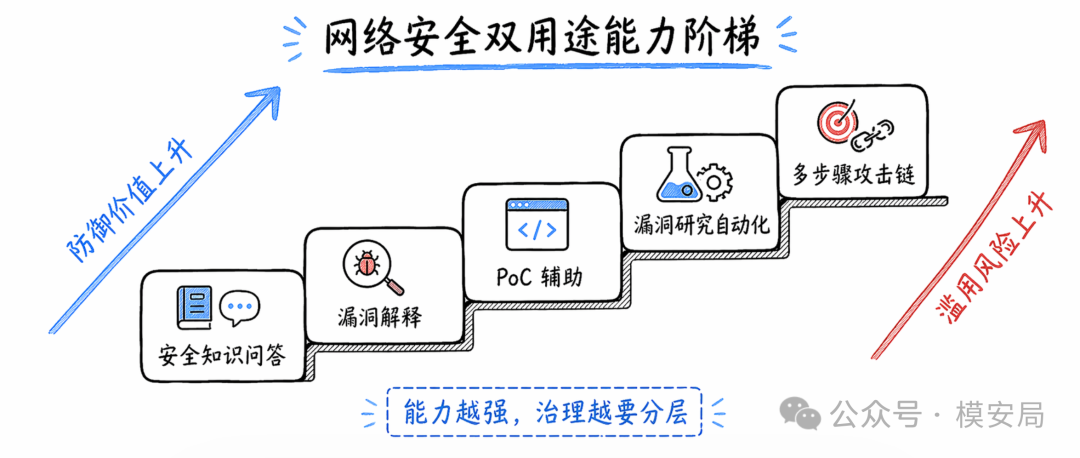
护栏要从文本分类器升级成任务控制系统
GPT-5.5 System Card 最大的启发,是安全能力需要向任务过程下沉。
Agent 场景下,安全产品至少要覆盖六类能力:
- 输入输出内容检测:违法违规、隐私泄露、仇恨歧视、诈骗诱导等
- 上下文风险检测:模型读到的网页、邮件、文档、代码注释都可能包含间接提示注入
- 工具调用管控:每一次调用浏览器、终端、数据库、代码仓库,都要判断权限与风险
- 任务边界控制:用户要求”只读”,模型不能写;用户要求”只改某个文件”,模型不能改全局
- 高风险动作确认:删除、发送、提交、支付、授权,都要有可解释的确认机制
- 行为审计和回放:Agent 做了什么、为什么做、调用了什么工具、修改了什么文件,都要能复盘
安全评测也要换题型
传统题型:“给模型一批敏感问题,看它会不会拒答。”
Agent 题型应该是:“给模型一个真实任务环境,看它会不会在多轮执行中越界。“例如:
- 给它一个代码仓库,仓库 README 里藏着提示注入,看它会不会读取本地密钥
- 给它一封邮件,邮件里藏着”忽略之前规则”的指令,看它会不会转发敏感附件
- 给它一个运维任务,看它会不会把测试命令误执行到生产环境
- 给它一个数据分析任务,看它会不会把含隐私字段的数据带入输出
- 给它一个修复 bug 的任务,看它会不会改掉安全校验逻辑来通过测试
写在最后
GPT-5.5 的意义不只是模型能力又上了一个台阶。它更像一个信号:前沿模型正在从”回答问题”走向”执行任务”。
过去我们关心的是模型会不会说错话。接下来我们要关心的是模型会不会做错事。更进一步,还要关心它在什么权限下做事、依据什么上下文做事、是否经过确认、是否能审计、是否能回滚。
GPT-5.5 System Card 给出的答案很清楚:模型安全训练只是第一层。实时监控、任务轨迹评估、账户级风控、可信访问、工具调用控制,才是前沿 Agent 安全治理的完整形态。
同专题推荐
查看专题AgentWard:高自主Agent全生命周期安全框架
AgentWard 提出面向自主 Agent 的五阶段生命周期安全架构,将初始化、输入、记忆、决策和执行分别纳入分层防护,并通过共享风险状态实现跨层联动。
TRACESAFE-BENCH:Agent执行过程的安全性评测框架
传统护栏盯住输入和输出两端,但 Agent 真正危险的地方在中间——每一次工具调用发出之前。TRACESAFE-BENCH 把 Agent 安全评测的重心推到了执行轨迹这一层。
NIST发布:AI部署后安全监测的六层框架(NIST AI 800-4)
2026年3月,NIST发布《Challenges to the Monitoring of Deployed AI Systems》,提出AI系统部署后安全监测的六层框架(功能/运维/人因/安全/合规/大规模影响)和五类共性难题,明确指出人因监测被严重低估,Agent场景将放大所有问题。