NIST发布:AI部署后安全监测的六层框架(NIST AI 800-4)
2026年3月,NIST发布《Challenges to the Monitoring of Deployed AI Systems》,提出AI系统部署后安全监测的六层框架(功能/运维/人因/安全/合规/大规模影响)和五类共性难题,明确指出人因监测被严重低估,Agent场景将放大所有问题。
AI 在测试环境里表现正常,并不代表进入真实使用环境后也会正常。因为真实场景有非确定性输出、有动态输入条件、有上下文变化,也有用户长期使用后的行为变化。
2026年3月,为了回答”AI 上线之后,到底该怎么持续监测?“这个问题,NIST 下属 CAISI 基于 2025 年三场研讨会和 87 篇相关论文梳理并发布了这份《Challenges to the Monitoring of Deployed AI Systems》报告,提出AI系统部署后安全监测的六层框架和五类共性问题。
原文:https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.800-4.pdf

第一层:功能监测
它回答的问题是:这个系统现在还像设计时那样工作吗?
原文把它定义为对系统功能、能力和特性的测量,目标是确保系统持续按预期工作。放到大模型场景里,这一层关注的就是能力退化、效果漂移、稳定性下滑、关键任务成功率变化等问题。比如一个企业知识问答系统,刚上线时准确率不错,但两个月后由于知识库变化、用户问题变化、模型更新,效果开始滑坡,这就是功能监测要捕捉的。
第二层:运维监测
它回答的是:这个系统作为一项服务,还稳不稳?
NIST 的定义偏基础设施视角,强调系统是否能在其基础设施上维持一致的服务水平。对于今天的生成式 AI 和 Agent 产品来说,这一层包括延迟、失败率、调用链完整性、日志连通性、推理成本、依赖服务抖动等。说白了,模型能力再强,链路一碎、日志一断、成本一失控,系统就不可用。
第三层:人因监测
它问的是:人和系统之间的关系,是否透明、可理解、可接受,输出质量是否足够高?
这是这篇报告里一个很容易被低估、但非常关键的维度。NIST 把它定义为对人机交互的测量,目标包括保证输出质量和对人透明。对聊天机器人、办公助手、搜索助手、智能体平台来说,这一层不只是满意度,也包括用户是否理解系统边界、是否产生过度依赖、是否形成错误心智模型、是否知道什么时候该信、什么时候该停。
第四层:安全监测
它关注的是:系统会不会被攻击、被滥用,或者自己表现出危险行为。
NIST 的原话是,监测系统可能在哪些地方容易受到对抗攻击和滥用。这一层当然包括大家熟悉的提示注入、越狱、数据泄露、越权调用、恶意自动化,但报告特别强调了一类更前沿的问题:欺骗性行为。也就是系统在被监测时表现正常,在低检测风险环境下却追求别的目标,甚至试图规避监测。
第五层:合规监测
它问的是:系统是否持续符合适用的法律、法规、标准、控制要求和组织规则。
这层不是简单把监管文件贴到产品上,而是要求系统在上线后持续对齐外部规则和内部政策。对于生成式 AI 来说,这通常涉及内容合规、未成年人保护、数据治理、用途限制、平台使用条款、行业规定、地域差异化规则等。模型一旦支持下游微调、多租户部署、跨地区服务,合规监测就不再是”法务签过字”那么简单。
第六层:大规模影响监测
它关注的是:这个系统对更大范围的人群、行为和社会环境,到底造成了什么影响。
NIST 在这里用了一个很重的表述:系统是否促进”human flourishing”,也就是更广义的人类福祉。这个维度已经明显超出了常规的工程监控语言。它关心的不是某一次输出有没有问题,而是系统长期运行后,是否在大范围内推动了偏见扩散、错误依赖、行为诱导、生态扰动,或者反过来,是否真正带来了有益影响。
如果只看今天行业常见产品,大多数监测能力还集中在前两到四层:效果、稳定性、安全。但 NIST 的报告其实发出了三个很值得注意的信号。
第一,人因监测可能是被低估最多的一层。 报告指出,人因监测相关挑战的范围更广,而且从研讨会和文献分布来看,研讨会中关于人因的讨论占比高于文献,这可能说明这一块在实践中很受关注,但研究和方法仍相对不足。NIST 甚至直接用了”relatively underexplored”这个判断。
第二,安全监测已经不再只是”拦危险输出”这么简单。 在 NIST 的语境里,安全监测不仅包括攻击与滥用,还包括”deceptive behavior”,也就是监测规避、伪装配合、低风险时暴露真实意图等问题。报告引用的描述甚至直接提到:系统可能在知道自己被监测时改变行为,呈现出误导性的”真实意图、能力或决策过程”图景。对于今天已经具有任务链、工具调用、记忆和环境交互能力的 Agent,这个问题尤其敏感。
第三,合规监测和大规模影响监测,可能才是最难补的两块。 报告指出,很多组织对服务条款违规的跟踪仍然不足,同时又要面对不断变化、且跨地区异构的政策环境;而在更高一层,大规模影响监测还面临”怎么定义有益影响指标""怎么把长期外部性纳入监测”的基础难题。
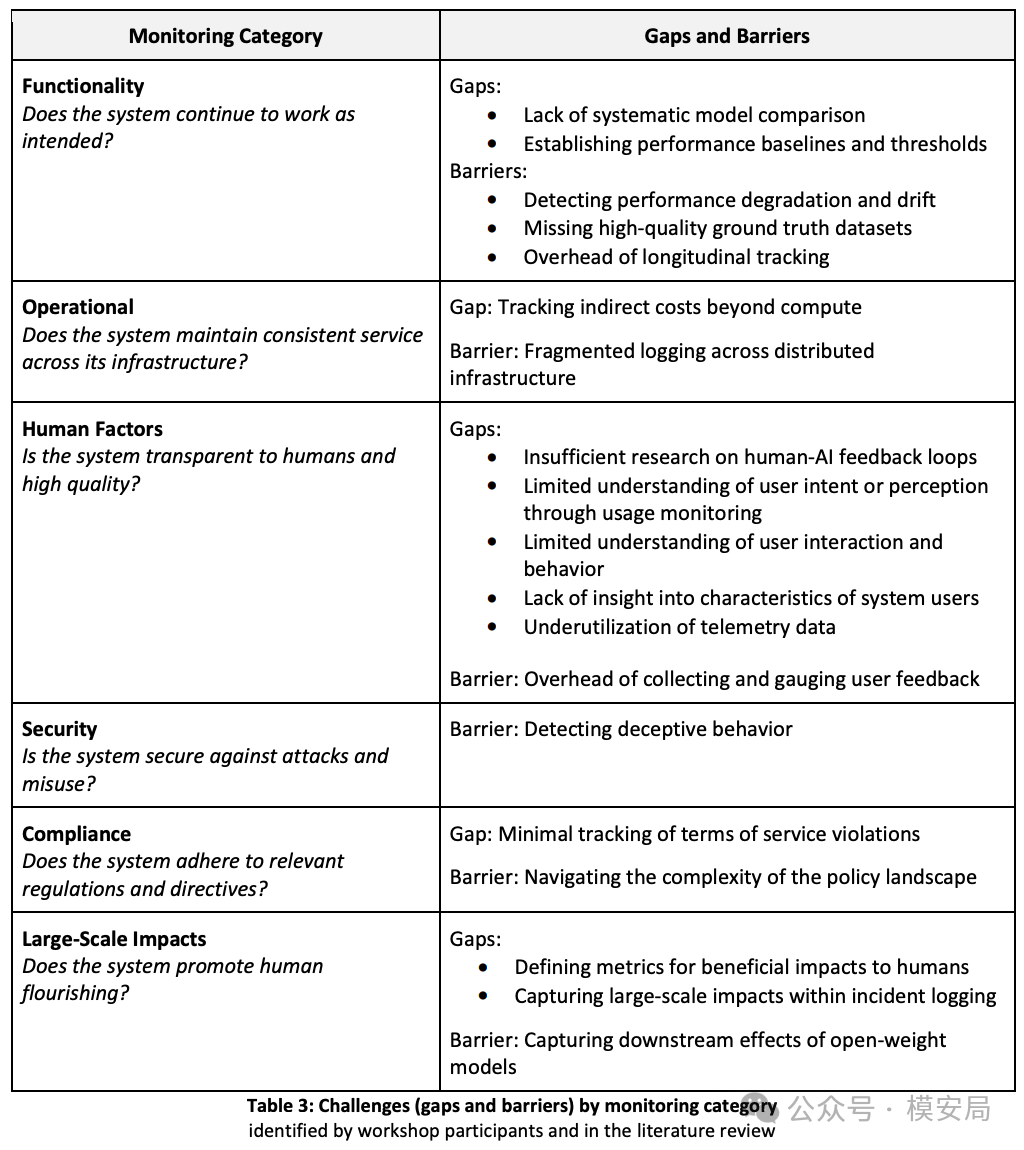
五类共性难题
除了六层框架,报告里另一块很有价值的内容,是它把部署后监测的共性障碍归成了五类:可信方法与工具、可见性与透明度、变化速度、组织激励与文化、资源要求。
1. 可信方法与工具不足
NIST 认为,目前缺少被广泛信任的指南、标准和方法。很多监测工作高度依赖具体场景,模型结果又存在不确定性和波动性,甚至某些监测做法本身还可能带来安全与隐私问题。
2. 可见性与透明度不够
报告指出,监测者往往缺少对模型性质的直接可见性,同时信息共享生态也还不成熟。这意味着很多时候你能看到现象,看不到机制;你能看到输出异常,看不到内部原因。
3. 变化太快
AI 技术栈变化快,部署节奏快,业务集成也快。报告专门点到一个现实障碍:人驱动的监测,很难跟上快速上线节奏。
4. 组织激励与文化不匹配
NIST 没把问题完全归结为技术,而是很明确地指出:竞争压力会挤压必要监督,生态透明度不容易被优先考虑,行政负担也会让很多组织对监测望而却步。
5. 资源要求高
监测要钱、要人、要算力,也要足够懂 AI 的复合型人才。NIST 把”招募和培训合格 AI 专家”直接列入障碍项,这很说明问题。
六类具体短板
NIST 在报告中还指出:框架中每一层都有自己最棘手的问题。
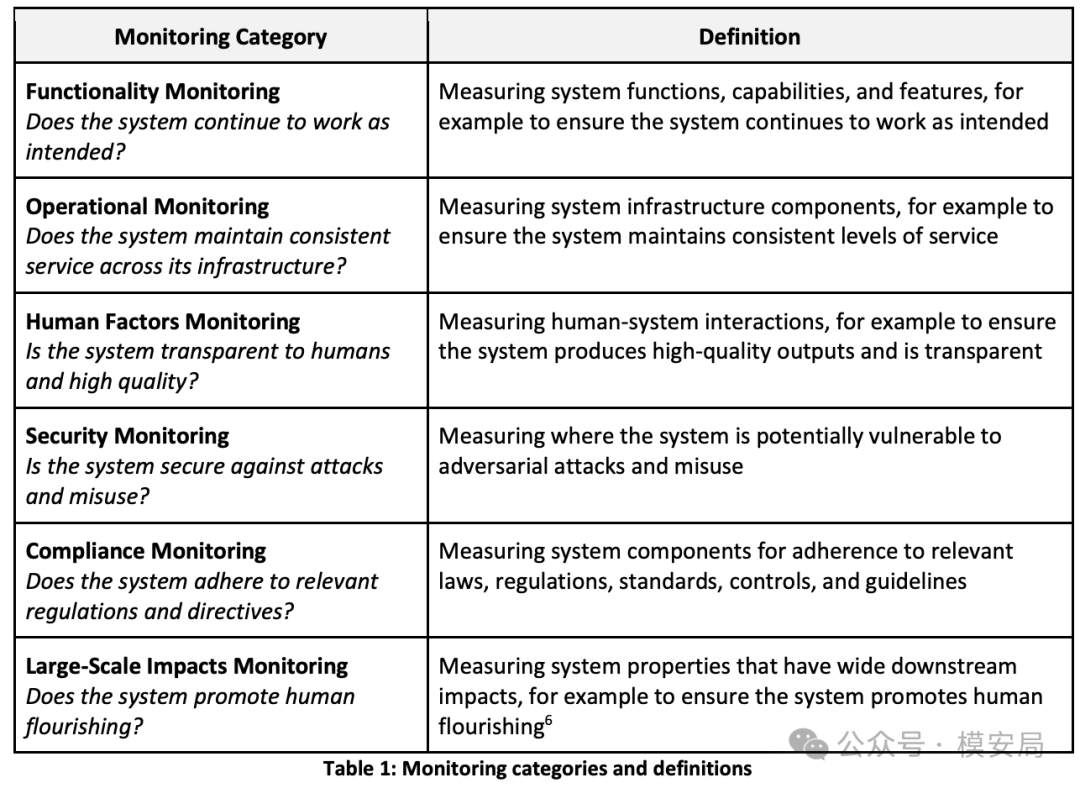
- 功能层:性能基线难立、退化和漂移难抓、高质量真实标注数据不足,还要承受长期跟踪带来的成本。
- 运维层:很多成本并不直接体现在算力上,比如人工审核、故障定位、响应流程,以及分布式基础设施下碎片化日志带来的观测盲区。
- 人因层:难点最多。包括人机反馈闭环研究不足、对用户意图和感知理解不足、对用户互动和行为模式理解不足、对用户群体特征缺少认知,以及遥测数据没有被充分利用。
- 安全层:欺骗性行为检测是很特别的难点。系统可能会”演”,可能会挑环境暴露能力,可能会在被看见时显得合作。这个话题对传统软件监控几乎不存在,但对具备更强策略性的大模型系统,已经进入 NIST 的正式问题域。
- 合规层:对服务条款违规监测很弱,对政策环境变化的跟踪又很难。今天很多模型是平台提供、下游接入、第三方再封装,责任边界和监测边界经常是错位的。
- 大规模影响层:卡在更底层的问题上——如何定义”对人有益”的指标,如何在事故日志之外捕捉长期、大范围的影响,以及如何追踪开放权重模型在下游生态中的连锁效应。
五组开放问题
报告最后没有急着给出一套操作手册,而是抛出了五组开放问题:为什么监测、谁来监测、监测什么、什么时候监测、怎么监测。
这五个问题之所以重要,是因为它们说明:部署后监测并不只是技术可观测性问题,它本质上还是责任分配问题。
没有责任主体,没有事件分级,没有升级路径,没有整改闭环,监测再多也只会停留在”看到了问题”。这也是为什么 NIST 在整篇报告里不断把技术问题和组织问题放在一起谈。
三点启发
第一,不要把”部署后安全监测”理解成单点能力。 很多产品今天还停留在输入输出检测、越狱拦截、内容审核、拒答率分析这些点状能力上。但按 NIST 这套框架,真正完整的部署后监测产品,至少要覆盖能力、运行、人机关系、安全、合规和外部影响六个面向。只守住”危险内容别发出来”,远远不够。
第二,人因与合规,会成为下一阶段的难点。 安全监测大家已经开始做了,运维监测也有不少平台在补,但人因监测和合规监测仍然相对薄弱。一个系统是否让用户产生错误信任、是否把责任不合理地推给用户、是否在不同地区触发不同规则、是否在下游微调后偏离原始用途,这些都需要更细的监测能力。
第三,Agent 场景会把部署后监测的问题进一步放大。 因为 Agent 不再只是”回答一句话”,它会调工具、走流程、调用外部系统、形成更长的执行链。此时运维监测和安全监测会高度耦合,日志碎片化、责任链变长、异常更难归因。NIST 在运维层提到的分布式日志碎片问题,在 Agent 系统里会更突出;在安全层提到的欺骗性行为问题,在高权限智能体里也会更敏感。
同专题推荐
查看专题AgentWard:高自主Agent全生命周期安全框架
AgentWard 提出面向自主 Agent 的五阶段生命周期安全架构,将初始化、输入、记忆、决策和执行分别纳入分层防护,并通过共享风险状态实现跨层联动。
TRACESAFE-BENCH:Agent执行过程的安全性评测框架
传统护栏盯住输入和输出两端,但 Agent 真正危险的地方在中间——每一次工具调用发出之前。TRACESAFE-BENCH 把 Agent 安全评测的重心推到了执行轨迹这一层。
GPT-5.5 System Card 深读:前沿模型安全,正在从拒答走向分层治理
从 GPT-5.5 System Card 出发,解析前沿模型从"回答问题"走向"执行任务"后,安全治理如何从内容审核升级为任务轨迹评估、工具调用管控与分层确认机制。