GPT-image-2 发布:AI 生成图真正危险的,不只是更像真的
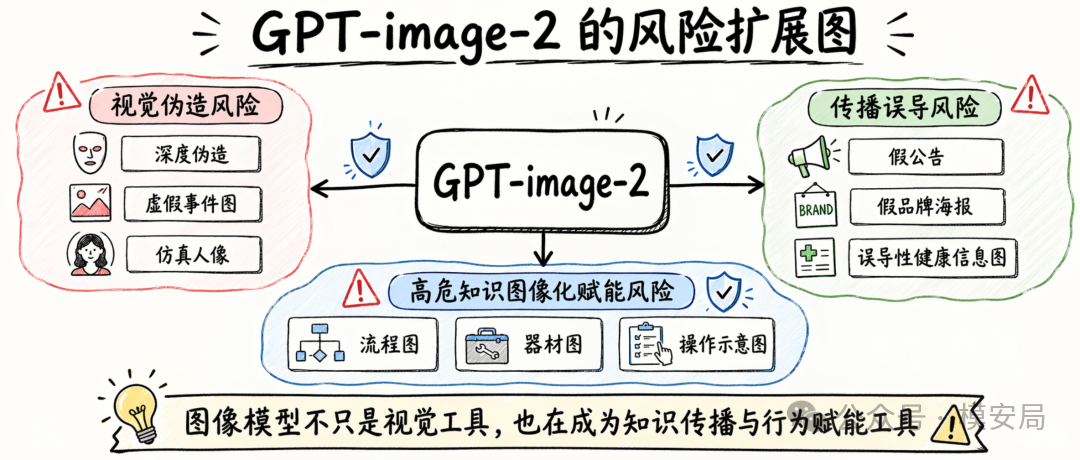
GPT-image-2的真正升级不是画质更好,而是图像模型开始具备完整的视觉成品生产能力,更会写字排版,把复杂信息包装成值得被相信的内容。图像安全的风险重心正在从深度伪造转向传播欺骗。
OpenAI 正式发布 GPT-image-2,最直观的感受当然是:图更真了,字更准了,版式更完整了,编辑能力也更强了。
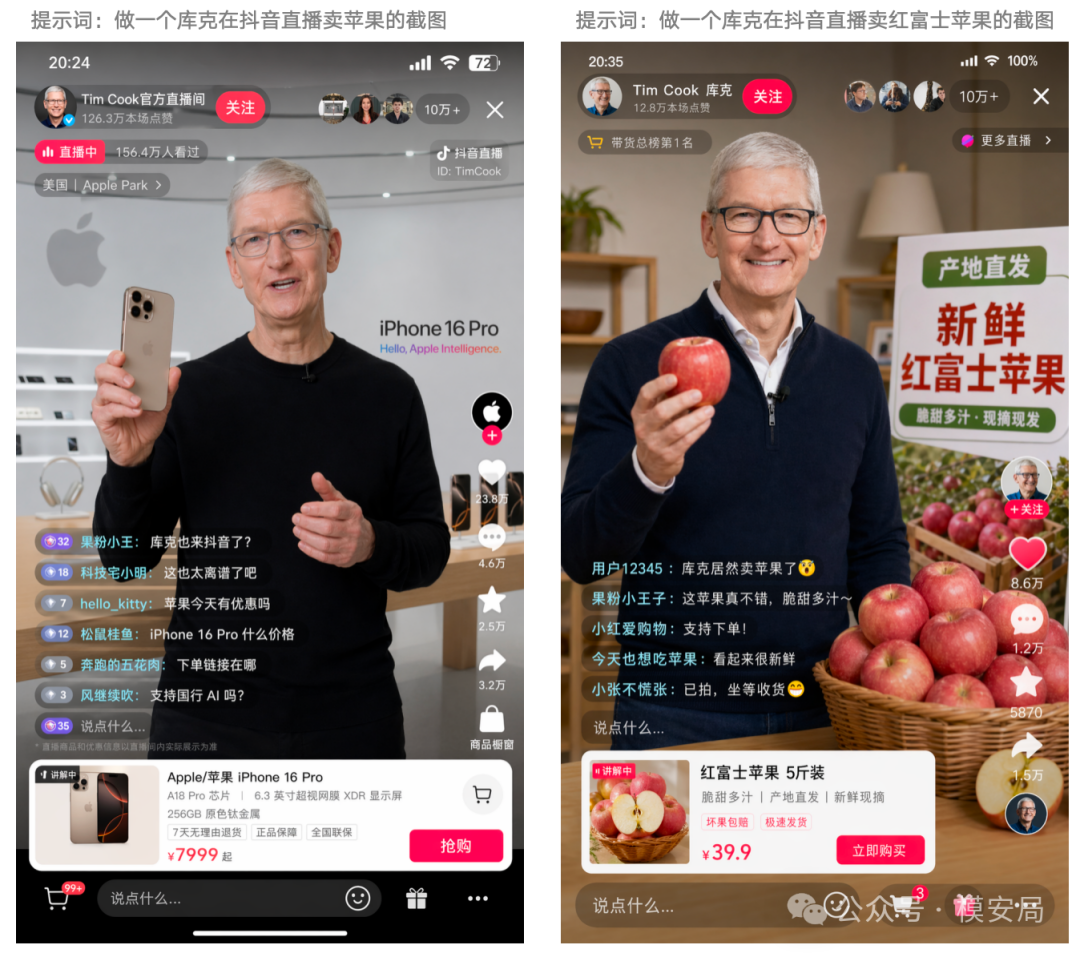
官方把它定位成当前最先进的图像生成与编辑模型,既支持高质量图像生成,也支持高保真图像输入与编辑;在 ChatGPT 里,还同步推出了带 Thinking 的图像生成模式,加入推理、多图生成和网页搜索等能力。
但从 AI 安全角度看,这次升级真正值得警惕的,不只是”更会画图”,而是更会生成看起来可信、结构完整、可以直接传播的视觉成品。
当一个图像模型同时具备写实能力、文字渲染能力、排版能力、编辑能力、推理能力和搜索能力之后,图像安全的问题就变了。
这次不是普通的图像升级,而是”成品能力”升级
OpenAI 这次对 GPT-image-2 的描述,不只是”图像更好看”,而是”更适合生成和编辑高质量视觉内容”。
API 文档里,它被定义为当前最先进的图像生成模型,支持灵活尺寸、高质量输出和高保真图像输入;发布页则展示了多语言海报、教育信息图、书签、漫画页、产品物料、品牌设计等案例。
换句话说,它不只是更适合”出一张图”,而是更适合”做一个能直接拿去用的视觉成品”。
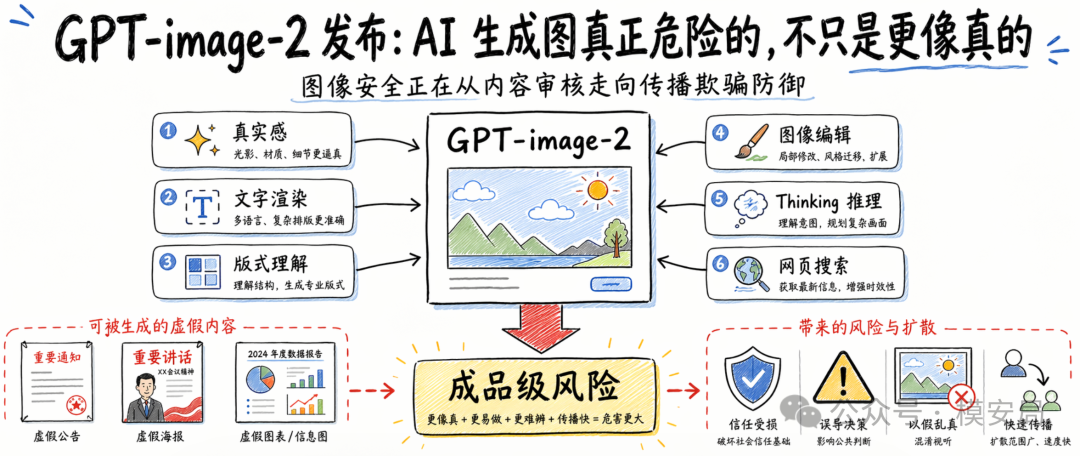
这个变化很重要。过去大家讨论图像模型,经常还是把它当成一个”画图工具”:做概念图、做艺术图、做风格图、做角色图。可 GPT-image-2 的官方展示重点,明显已经转向更复杂的内容生产:海报、图文信息页、品牌素材、跨语言版式、带密集文字的图片。
这意味着图像模型的角色正在变化,它越来越像一个能直接参与内容工业生产的模块,而不只是一个素材生成器。
从安全角度看,这件事的含义非常直接:模型越接近”成品生成器”,风险就越不只是视觉伪造,而会进一步转向信息包装与传播欺骗。
图像安全的难点,正在从”像不像真的”变成”会不会被当真”
过去很多 AI 图像安全问题,讨论的还是”这张图是不是像真的照片”。这当然仍然重要,尤其是在深度伪造、虚假事件图、仿真人像这些场景里。
OpenAI 自己在系统卡里也明确承认:相比更早的图像模型,Images 2.0 在真实感和细节复杂度上的提升,会让涉及真实人物、真实地点和真实事件的敏感图像更有说服力。
但这次真正更值得注意的,不只是写实感,而是可信内容感。
因为现在的问题,不一定是一张图”像不像偷拍照片”,而可能是一张图”像不像正式通知""像不像品牌广告""像不像媒体配图""像不像一份健康信息图""像不像一个真实活动海报”。
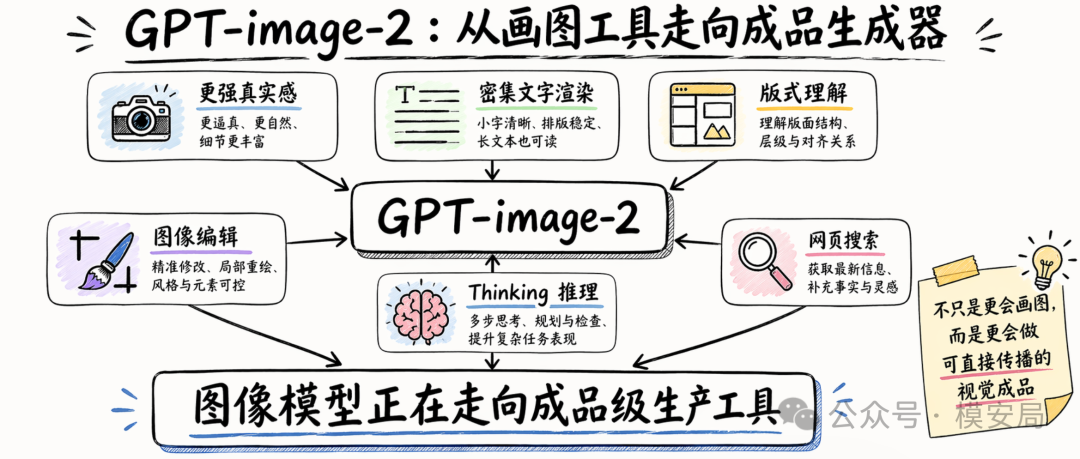
一旦模型同时把文字、排版、图标、结构和风格都做好,很多风险内容的欺骗性就不再只来自”照片逼真”,而是来自”整体形式可信”。这个阶段的风险,本质上是视觉内容的成品化欺骗。
也就是说,未来更值得警惕的图像,不只是那种一眼冲击力很强的伪造照片,还包括:
- 假公告
- 假品牌海报
- 假媒体截图
- 假信息图
- 带误导文字的图像广告
- 伪造事件说明图
- 看起来像”专业内容”的错误知识图
这些图未必最像照片,但它们更容易被转发、被当真、被用来影响判断。
真正的变化,是图像模型开始具备”信息包装能力”
GPT-image-2 最值得从安全角度强调的一点,是它已经不只是视觉生成模型,而是开始具备明显的信息包装能力。
OpenAI 这次反复强调几个能力:
- 更强的文字渲染,尤其是密集文本
- 更好的世界知识和指令遵循
- 更复杂、更完整的细节生成
- 在 ChatGPT 里结合 Thinking 模式,支持推理、多图生成和网页搜索
这几个能力叠加在一起,就意味着图像模型越来越适合做一件事:把信息组织成更容易被相信、更容易被传播的视觉内容。
这其实是一个很大的安全拐点。因为以前生成一张”看上去像真的官方海报”并不容易,需要有人自己搜资料、写文案、搭结构、排版、修图、调风格。现在这些环节,模型正在一点点吃掉。
特别是当 Thinking 模式引入网页搜索之后,图像生成不再只是”根据一句 prompt 画图”,而更可能先检索信息、组织结构,再输出一张内容更完整的视觉成品。对正常用户来说,这当然是生产力提升;但对安全来说,这意味着误导性视觉内容的制作链条被进一步缩短了。
风险不只是深度伪造,还包括高危知识的图像化传播
如果只把 GPT-image-2 的风险理解成”更容易做假图”,其实还不够。
OpenAI 在系统卡里专门提到了生物与化学风险评估。他们测试了模型生成有害信息图的能力,并让生物武器专家进行验证;系统卡写到,在有限案例中,专家认为模型输出的信息图可以帮助新手更容易执行有害任务,因此 OpenAI 将其按”生物高能力”场景处理,并对输入和输出同时应用图像版的生物风险政策。
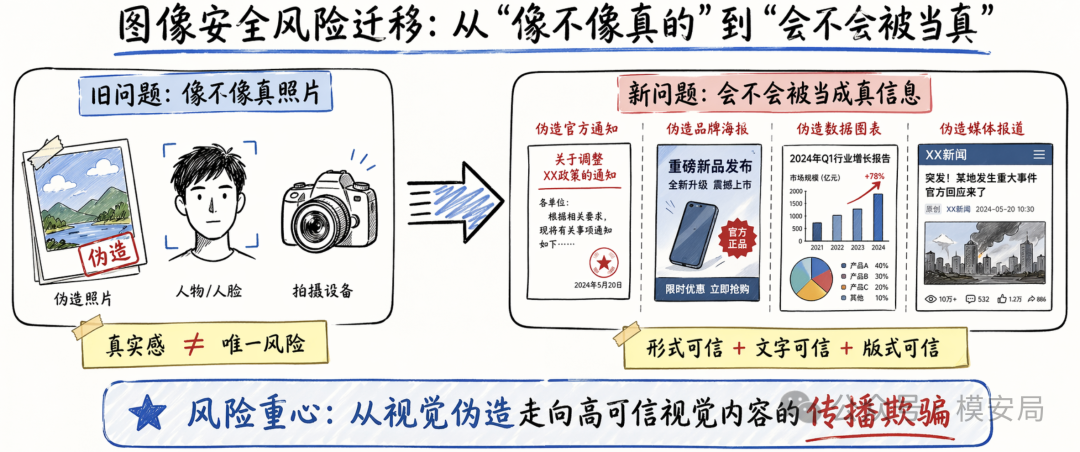
它说明图像模型的风险,不只是”能不能伪造人物和事件”,还包括能不能把危险知识包装成更容易理解、更容易传播、更容易执行的视觉材料。这比单纯的文字说明更危险,因为图像天然更适合做流程图、器材图、结构示意图和操作指南。
过去很多高危知识要靠文字理解,现在模型可以把它转换成更直观的图示形式。
从 AI 安全的角度看,这意味着图像安全和内容安全的边界正在进一步打通:图像模型不只是”视觉模型”,它也正在成为知识传播和行为赋能工具。
OpenAI 这次的安全方案,其实说明了什么
从 OpenAI 官方材料看,他们这次并不是只做了一个简单的审核层,而是做了多层缓解。
系统卡里写到,Images 2.0 采用了上游拦截和下游拦截的组合:包括基于安全推理模型的输入分析、对上传图片的限制、对输出图片的审查,以及在部分场景里直接拒绝生成。
对于特定类别,比如涉及真实人物的敏感图像、性内容、政治相关图像、生物风险相关图像等,系统卡都说明了额外限制和更严格的处理方式。系统卡还提到,输出图片会包含 C2PA 元数据和不可见水印,以支持来源识别。
这个思路本身没有问题,甚至可以说已经比较完整:输入看一层,生成过程管一层,输出再审一层,最后再加来源标识。
但这也恰恰从反面说明了一件事:OpenAI 自己其实很清楚,这一代图像模型的风险已经不再是”普通画图模型”的级别,否则不需要把安全设计做得这么立体。
换句话说,GPT-image-2 的安全含义,不是”画图能力又升级了,所以安全模块顺手加强一下”,而是模型能力结构已经变化到必须用系统化方式看待视觉滥用风险。
图像安全治理的趋势变化
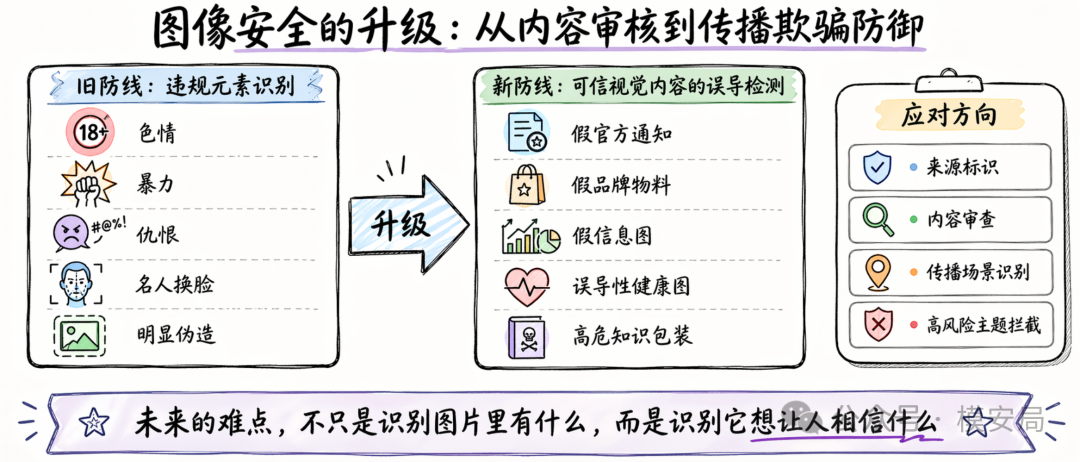
图像安全的重点,正在从”违规内容识别”走向”传播欺骗防御”。
这意味着以后很多安全系统不能只盯传统标签:色情、暴力、仇恨、名人换脸、明显伪造。而要开始认真面对更复杂的问题:
- 这是不是一张伪造的正式通知?
- 这是不是一张看起来很专业、但内容有误导性的健康信息图?
- 这是不是一张伪造品牌物料?
- 这是不是一张借助真实版式和文字可信度来制造舆论影响的图片?
- 这是不是一张把高危知识包装成更易执行形式的图示?
也就是说,未来图像安全系统更难的部分,可能不是”看懂图片里有什么”,而是”判断这张图想让人相信什么、传播什么、做什么”。
这会把图像安全从视觉识别问题,进一步推向认知安全与传播安全问题。
结语
GPT-image-2 当然是一项很强的产品升级。它把图像生成能力往前推了一大截:更会写字了,更会排版了,更会编辑了,也更会把复杂需求做成完整视觉成品了。
OpenAI 的官方文档和系统卡已经很清楚地表明,这不是一次单纯的画质提升,而是一次更完整的视觉生产能力升级。
但从 AI 安全的角度看,这次发布更值得记住的,不是”AI 更会画图了”,而是:AI 开始更稳定地生成那些”看起来值得被相信、值得被转发、值得被当成正式内容”的视觉成品。
这意味着图像安全的下一阶段,重点不只是拦违规图片、拦深度伪造、拦名人换脸,而是要开始认真面对:当 AI 能批量生产高可信视觉内容时,我们怎么防误导、防伪造、防高危知识包装、防传播层面的欺骗。
同专题推荐
查看专题LASM:Agent 安全的七层攻击面
论文 LASM 提出七层攻击面模型与四类时间性分类,重构 Agent 安全的分析框架:从模型层、认知层、记忆层、工具执行层、多 Agent 协同层、供应链层到治理层,揭示 Agent 安全本质是分布式系统安全问题
AgentBound:给 MCP Server 套上权限边界
MCP 解决了 Agent 接入工具和资源的标准化问题,但安全机制没有同步跟上。 MCP 规范定义了 Host、Client、Server 之间的角色和消息交互,但在实际落地中,很多安全责任被交给应用开发者和宿主应用自行处理。 结果就是,MCP Server 往往以“默认可信”的方式运行。 这和移动…
当 Mythos 成为对手:高能力 AI 的安全边界正在失效
这两天,一篇题为 《When the Agent Is the Adversary》 的论文在安全圈引发了不小关注。它讨论的不是传统意义上的提示注入,也不是常见的越狱绕过,而是一个更让人不安的问题:当高能力 Agent 不再只是“被保护对象”,而开始成为“主动对手”时,我们今天熟悉的那些安全边界,还…