大模型“开源”到底开了什么?不同协议有什么区别?
文章拆解大模型“开源”的不同层次,区分开放代码、开放权重、训练数据、训练配方和使用政策,并比较 MIT、Apache-2.0、BSD、自定义模型协议等对企业商用、微调、再分发和合规风险的影响。
大模型发布时,“开源”已经成了一个高频词。
一个模型刚发布,大家最先关心的往往是参数规模、跑分、推理成本、上下文长度,以及能不能本地部署。
但如果企业真要把模型放进产品、服务客户、做私有化交付,另一个问题会变得非常关键:
这个模型到底能不能用,能用到什么程度,用完之后有没有法律和商业风险。
这时候,“开源”两个字就不够用了。
因为大模型时代的开源,和传统软件时代的开源已经不完全一样。
传统软件开源,核心是代码开放;大模型开放,可能开放的是代码,也可能只是开放权重,可能附带训练方法,也可能只给一份技术报告。
有些模型允许商用,有些只允许研究,有些可以微调,有些禁止用模型输出训练竞争模型。有些模型看起来很开放,但协议里还有用户规模、用途边界、行业限制和安全使用政策。
所以,理解大模型开源协议,本质上不是学习法律条文,而是理解一个模型能不能真正进入商业链路。
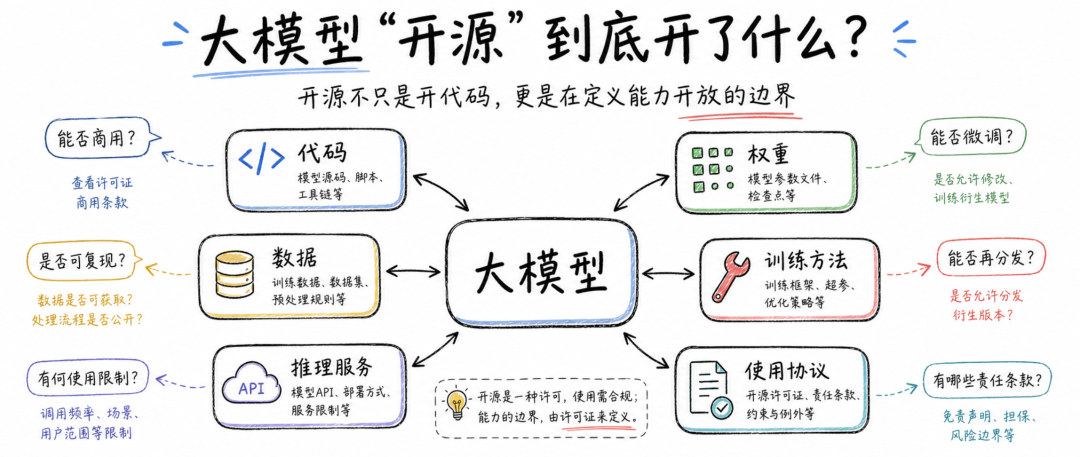
▎大模型“开源”,到底开了什么?
在传统软件里,开源通常比较直观。代码仓库公开,许可证允许使用、修改、分发,用户就可以基于代码做二次开发。
但大模型复杂得多。一个大模型项目至少包含几类东西。
首先是模型代码,包括模型结构定义、推理代码、训练脚本、评估代码、数据处理代码等。代码开放之后,开发者能看懂模型怎么运行,也能基于代码做工程改造。
其次是模型权重。权重是大模型训练之后形成的参数文件,也是大家常说的“开放权重”的核心。如果只有权重开放,用户通常可以下载模型、本地部署、继续微调,但不一定能复现训练过程。
再次是训练数据和数据说明。这部分最敏感,也最容易缺失。很多模型不会公开完整训练数据,原因包括版权、隐私、安全、商业机密等。但缺少数据来源和处理方法,外部开发者就很难判断模型能力、偏见、合规风险和复现路径。
还有一类是训练配方。它包括训练阶段怎么划分、数据比例怎么配、RLHF 或 RLAIF 怎么做、安全对齐怎么做、评测集怎么设计、后训练如何优化等。很多技术报告会披露一部分训练思路,但距离完整复现仍然很远。
最后是许可证和使用政策。这部分决定了用户能不能商用、能不能修改、能不能再分发、能不能做 SaaS、能不能把输出用于训练别的模型,以及哪些用途被禁止。
| 对象 | 常见协议/条款 |
|---|---|
| 推理/训练代码 | MIT、Apache-2.0、BSD、GPL、MPL 等 |
| 模型权重 | MIT、Apache-2.0、自定义模型协议、Llama Community License、OpenRAIL 等 |
| 数据集 | CC-BY、CC-BY-SA、CC-BY-NC、CDLA、ODC 等 |
| 使用限制 | Acceptable Use Policy、安全使用政策、禁止特定用途条款 |
所以,大模型所谓“开源”,至少要追问五个问题:
开了代码没有?开了权重没有?开了数据说明没有?开了训练方法没有?协议允许怎么用?
如果这几个问题没有问清楚,“开源”很容易变成一个宣传词。
▎开放权重,和真正开源还有距离
现在很多模型更准确的说法其实是“开放权重模型”。
开放权重当然很有价值。它让企业可以本地部署,让研究者可以微调,让开发者可以在不调用闭源 API 的情况下搭建应用。对于产业来说,开放权重已经大幅降低了大模型应用的门槛。
但开放权重不等于完整开源。
Open Source Initiative 在 Open Source AI Definition 1.0 里,把 AI 模型拆成模型架构、模型参数和推理代码,并强调如果要称为开放源代码模型或开放源代码权重,应包含用于产生这些参数的数据说明和代码。换句话说,只给最终权重,通常还不足以支撑严格意义上的“开源 AI”。
这也是大模型时代最大的语义差异。
很多模型项目在 GitHub 上有代码,在 Hugging Face 上有权重,在论文里有技术报告,于是大家习惯性称之为“开源模型”。但从可复现、可修改、可审计的角度看,它们开放的深度可能差别很大。
有的模型开放了推理代码和权重,但没有训练代码;有的模型开放了训练代码,但没有数据;有的模型开放了数据说明,但没有完整数据;有的模型虽然允许下载权重,但协议里限制了商业使用、竞争用途和下游发布方式。
所以,对于企业来说,更稳妥的表达是区分三类:开放权重、开放代码、开放训练过程。开放权重解决的是部署问题,开放代码解决的是工程改造问题,开放训练过程解决的是复现和深度审计问题。
这三个层次不能混在一起。
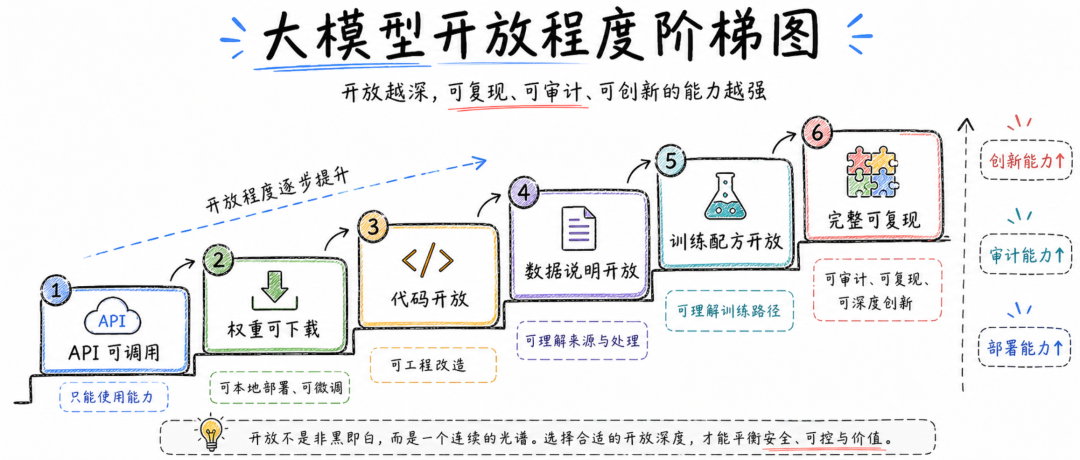
▎最友好的协议:MIT、Apache-2.0、BSD
如果企业要把一个模型或代码库放进商业产品,最喜欢看到的通常是 MIT、Apache-2.0、BSD 这类宽松型协议。
MIT 是最简单的一类。它允许商业使用、修改、分发,也允许把相关代码放进闭源产品里,主要要求是保留版权和许可证声明。Choose a License 对 MIT 的说明也很直接:它是一个简短、宽松的许可证,核心条件就是保留版权和许可证通知。
Apache-2.0 也很宽松,但比 MIT 更适合企业严肃使用。它除了版权授权,还包含明确的专利授权条款。Apache 官方许可证文本中写明,贡献者向用户授予永久、全球、非独占、免费的版权许可,同时也提供专利许可。
BSD 协议也属于宽松型。BSD 3-Clause 允许以源代码或二进制形式再分发和使用,无论是否修改,但要保留版权声明和免责声明;另外它还有一个常见要求,不能未经许可使用原作者或贡献者的名字为衍生产品背书。
从企业视角看,这三类协议的优势很清楚:可以商用,可以修改,可以集成进闭源系统,合规成本相对可控。
如果一个模型的代码和权重都采用 Apache-2.0 或 MIT,同时没有额外的非商业、用途限制、用户规模限制,那么它对商业落地非常友好。企业可以基于它做私有化部署、行业微调、Agent 应用、模型网关、企业知识库,以及各种上层 AI 产品。
当然,宽松不代表完全不用看协议。比如 Apache-2.0 要注意 NOTICE 文件和专利终止条款,MIT 和 BSD 要保留版权声明,模型权重如果另有单独协议,也要以权重协议为准。
这里最容易出错的地方在于,很多项目的代码是 Apache-2.0,但权重不是 Apache-2.0。企业不能只看 GitHub 仓库里的代码许可证,还要看模型权重页面、模型卡和下载页面上的协议。
▎最容易踩坑的协议:GPL、AGPL、CC-BY-NC
如果说 MIT、Apache-2.0、BSD 是企业相对安心的协议,那么 GPL、AGPL、CC-BY-NC 则需要更谨慎。
GPL 是典型的 copyleft 协议。它允许使用、修改和分发,但如果你分发基于 GPL 代码形成的衍生作品,通常也需要按照 GPL 开放对应代码。GNU 对 GPLv3 的说明中明确说,GPL 是自由的 copyleft 许可证,目的是保证用户分享和修改程序的自由。
这意味着 GPL 并不禁止商业使用。很多人误以为 GPL 等于不能商用,这是误解。真正的问题在于,如果企业想把 GPL 代码深度集成到闭源产品并对外分发,就可能触发代码开放义务。
AGPL 更敏感。它关注网络服务场景。GNU 对 AGPL 的说明中写得很清楚:如果修改后的程序运行在网络服务器上,服务器运营者需要向该服务器用户提供修改版本的源代码。
这对大模型产品尤其重要。因为今天很多 AI 产品不是传统软件分发,而是 SaaS、API、Agent 平台、模型网关、在线服务。如果核心组件采用 AGPL,企业即使没有把软件包发给客户,只是在线提供服务,也可能触发源代码提供义务。
CC 协议则更多出现在数据集、文档、图片、语料和内容资源里。Creative Commons 官方对 NC 的解释是,只允许非商业使用;对 SA 的解释是,改编作品必须以相同条款共享;对 ND 的解释是,只允许分发未改编版本。
其中最需要注意的是 CC-BY-NC。很多数据集会采用这个协议,研究人员下载来做实验没问题,但企业拿它训练商业模型、做收费服务、进入客户项目,就可能出现商业使用风险。
大模型时代,数据协议的风险有时比代码协议还隐蔽。因为模型训练链路很长,数据可能经过清洗、混合、蒸馏、合成、再训练,最终很难从模型输出里看出原始数据来源。但合规风险不会因为数据进了训练流程就自动消失。
因此,只要看到 GPL、AGPL、CC-BY-NC、Research Only、Non-commercial、Academic Use Only 这类字样,企业就要停下来仔细看。它们未必不能用,但不能按 Apache-2.0 或 MIT 的方式随意集成。
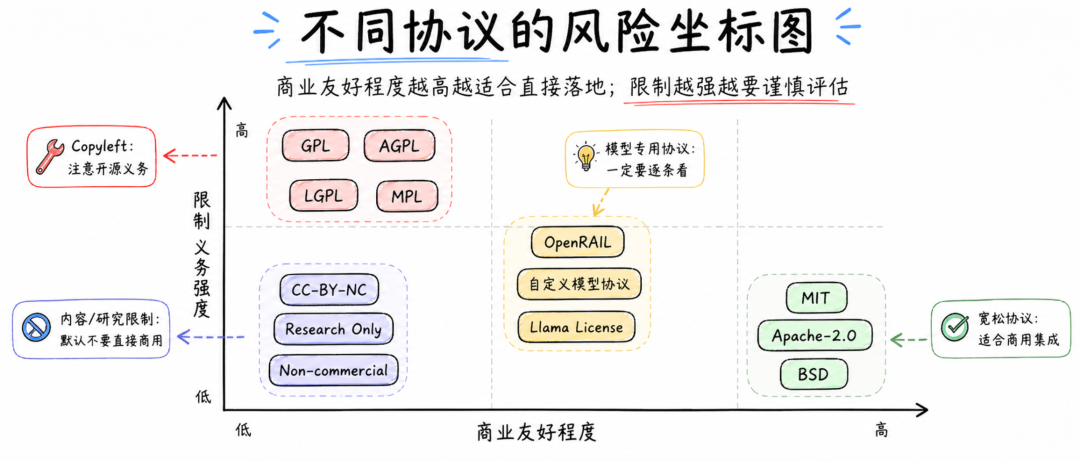
▎模型时代的新协议:OpenRAIL、Llama License 和自定义协议
传统开源协议主要是为软件代码设计的,到了大模型时代,很多模型发布方开始使用模型专用协议或自定义协议。
OpenRAIL 是其中比较典型的一类。Hugging Face 对 OpenRAIL 的介绍是:这类协议面向 AI,允许开放访问、使用和分发 AI 制品,同时要求负责任地使用。也就是说,它想在开放和安全之间建立一个新的许可框架。
OpenRAIL 的特点是,它通常允许下游使用、修改、再分发,但会加入行为限制。比如禁止生成恶意软件、违法内容、歧视性内容、欺诈内容,或者其他高风险用途。
这类协议在 AI 安全上有现实意义。模型越强,开放后的滥用风险越高。发布方希望让研究者和开发者受益,同时保留对明显有害用途的限制。
但从传统开源定义看,这也带来了争议。因为经典开源理念通常要求许可证不能限制使用领域。一旦协议写明某些用途不能用,它就更像“开放模型协议”或“负责任 AI 使用协议”,而不一定是严格意义上的开源软件协议。
Llama 系列这类自定义协议也是类似逻辑。它们通常允许研究和商业使用,但会附加条件。比如要求遵守 Acceptable Use Policy,限制某些高风险用途,可能对超大规模用户设置额外授权要求,也可能限制用模型输出来训练或改进其他模型。
这类协议的关键不在于它是否写了“commercial use”,而在于商业使用后面跟了哪些条件。
企业最容易误判的地方是只看到“允许商用”,却没继续看三件事。第一,是否有用户规模限制;第二,是否限制用模型输出训练其他模型;第三,是否有安全政策、行业用途和再分发限制。
如果企业只是内部评测,问题可能不大。如果要做成产品,卖给客户,进入 ToB 或 ToG 项目,再用这些模型做行业微调和二次分发,协议边界就必须提前确认。
▎企业选模型,不能只看能力
对企业来说,模型选型通常会看几个指标:能力、成本、速度、上下文长度、多语言表现、工具调用能力、私有化部署难度。
但如果进入真实商业链路,还要加上一条:协议边界。
一个模型能力再强,如果协议只允许研究使用,就不能直接放进商业产品。一个模型跑分再高,如果禁止某些行业场景,就不能随便接入客户系统。一个模型开放了权重,如果禁止再分发,就不能简单包装成自己的模型产品交付。一个模型允许微调,如果禁止用输出训练其他模型,那么蒸馏、数据合成、模型迭代都要重新设计。
这也是为什么模型协议正在变成 AI 产品经理、技术负责人和安全负责人都需要理解的内容。
从产品角度看,协议决定功能边界。能不能私有化,能不能给客户部署,能不能做 API 服务,能不能把模型能力封装进 Agent,能不能在行业数据上继续训练,都和协议有关。
从安全角度看,协议决定责任边界。很多模型的使用政策会明确禁止违法、有害、高风险用途,企业如果把模型接入开放场景,就需要做输入输出风控、日志审计、权限控制和滥用监测。
从商业角度看,协议决定增长边界。有些模型在小规模阶段可以免费商用,但达到一定用户规模后需要单独授权。企业早期 PoC 时可能没感觉,等产品做大之后,协议成本会突然变成商业成本。
所以,模型选型不能只问“能不能跑”,还要问“能不能合法、稳定、长期地跑”。
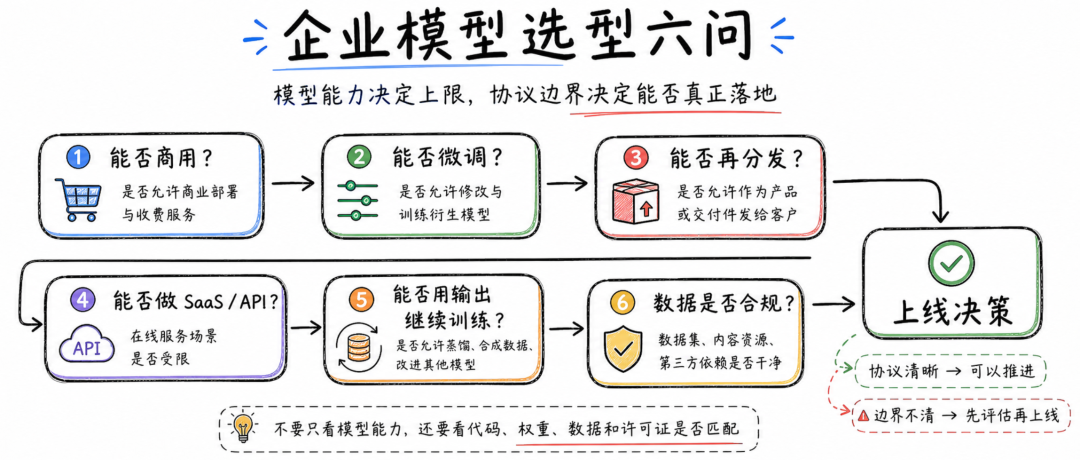
▎协议差异可以这样记
如果只做一个简单判断,可以把常见协议分成几类。
MIT、Apache-2.0、BSD 属于宽松型,最适合商业集成。它们通常允许商用、修改和闭源集成,其中 Apache-2.0 因为有更明确的专利授权,在企业场景下尤其常见。
GPL、LGPL、AGPL 属于 copyleft 阵营。GPL 强调衍生作品的开放义务,LGPL 对库更友好一些,AGPL 对网络服务更敏感。它们并非不能商用,但需要认真评估集成方式和触发条件。
MPL 处在中间位置。Mozilla 官方 FAQ 把 MPL 称为一种简单的 copyleft 许可证,它的文件级 copyleft 鼓励贡献者分享对原文件的修改,同时允许和其他开源或专有代码组合。
CC 系列更多用于数据和内容。CC-BY 比较宽松,CC-BY-SA 要注意相同方式共享,CC-BY-NC 要注意非商业限制,CC-BY-ND 要注意禁止改编。对大模型训练来说,NC 类数据尤其需要谨慎。
OpenRAIL、Llama License、自定义模型协议则属于大模型时代的新型协议。它们通常围绕模型权重、下游使用、安全责任和商业授权来设计。它们的复杂性比传统软件协议更高,也更需要逐条看原文。
| 协议 | 类型 | 可商用 | 可闭源集成 | 是否要求衍生开源 | 主要风险 |
|---|---|---|---|---|---|
| MIT | 宽松型 | 可以 | 可以 | 不要求 | 专利授权不如 Apache 明确 |
| Apache-2.0 | 宽松型 | 可以 | 可以 | 不要求 | 需保留 NOTICE/版权声明,注意专利终止 |
| BSD-2/3 | 宽松型 | 可以 | 可以 | 不要求 | BSD-3 不能用原作者名义背书 |
| GPL | 强 copyleft | 可以 | 通常不适合闭源分发 | 要求 | 闭源商业集成风险高 |
| LGPL | 弱 copyleft | 可以 | 可以,但要注意链接方式 | 修改库本身通常要开放 | 静态/动态链接合规复杂 |
| AGPL | 网络 copyleft | 可以 | 商业 SaaS 要谨慎 | 网络服务也可能触发 | 云服务集成风险高 |
| MPL-2.0 | 文件级 copyleft | 可以 | 可以 | 修改 MPL 文件需开放 | 文件边界要管理清楚 |
| CC-BY | 内容/数据协议 | 可以 | 不涉及代码闭源 | 需署名 | 数据训练用途需单独判断 |
| CC-BY-SA | 内容/数据协议 | 可以 | 不涉及代码闭源 | 衍生内容同协议 | 可能影响衍生数据/内容发布 |
| CC-BY-NC | 内容/数据协议 | 不适合商业 | 不涉及代码闭源 | 视协议而定 | 商业训练/产品使用风险高 |
| OpenRAIL/RAIL | AI 模型协议 | 视条款 | 视条款 | 视条款 | 有行为使用限制,不一定是 OSI 开源 |
| Llama Community License 等 | 自定义模型协议 | 通常有限制地允许 | 视条款 | 视条款 | 用户规模、竞争用途、AUP 等限制 |
▎真正的问题是:谁来承担开放之后的责任?
大模型开源协议之所以变复杂,本质上是因为模型本身变复杂了。
传统软件的风险更多来自代码运行逻辑。大模型的风险还来自训练数据、生成内容、下游调用、工具执行、自动化决策和恶意滥用。一个模型一旦开放权重,就可能被微调、蒸馏、改名、嵌入 Agent、接入工具链,最后进入各种不可控场景。
因此,模型发布方既想开放生态,又想控制风险。开发者希望自由使用,企业希望降低授权成本,监管方希望明确责任边界,安全团队希望防止模型被用于违法和攻击活动。
这几股力量交织在一起,就形成了今天的大模型协议格局。
宽松协议鼓励生态扩散,但很难约束滥用。限制性协议有利于责任控制,但会降低开放程度。自定义协议能贴合模型特点,但也增加了合规复杂度。
所以,大模型开源协议不只是许可证问题,也是一种产业治理机制。
它决定了模型能力如何流动,谁可以使用,谁可以改造,谁可以商业化,谁要为滥用负责。
▎结语
大模型开源不能只看有没有 GitHub 仓库,也不能只看 Hugging Face 上有没有权重。
真正要看的,是它到底开放了什么,以及协议允许你把它用到什么程度。
代码开放,解决的是工程透明度;权重开放,解决的是部署和微调;数据与训练方法开放,解决的是复现和审计;许可证开放,决定的是商业边界;使用政策存在,说明模型能力已经进入责任治理阶段。
对个人开发者来说,开源模型意味着更低的实验门槛。对企业来说,开源模型意味着更复杂的选型判断。模型能力决定产品上限,协议边界决定产品能不能真正落地。
以后再看到一个模型宣布“开源”,可以先别急着看跑分。
先问一句:它到底开了什么?
同专题推荐
查看专题智能体正式进入监管周期:中国开始为 Agent 时代建立治理底座
2026年5月8日三部委联合印发《智能体规范应用与创新发展实施意见》,监管对象从大模型转向智能体,提出七层安全框架、权限边界、行为围栏、AIP协议与智能互联网等核心议题,标志着 Agent 时代治理底座正式铺底
从"技术滥用"到"应用乱象":中央网信办2026 AI 专项行动释放了什么新信号
去年打的是 AI 黑灰产,今年管的是 AI 产业链——监管正在从治理"AI 技术被滥用",进入治理"AI 应用全链条"的阶段。
中国大模型输出内容的法律法规体系
从基础法律到生成式AI专项规章,系统梳理中国大模型内容安全的五层法律框架:网络安全法、数据安全法、算法监管规定、生成式AI暂行办法及技术标准,厘清平台主体责任与合规路径。