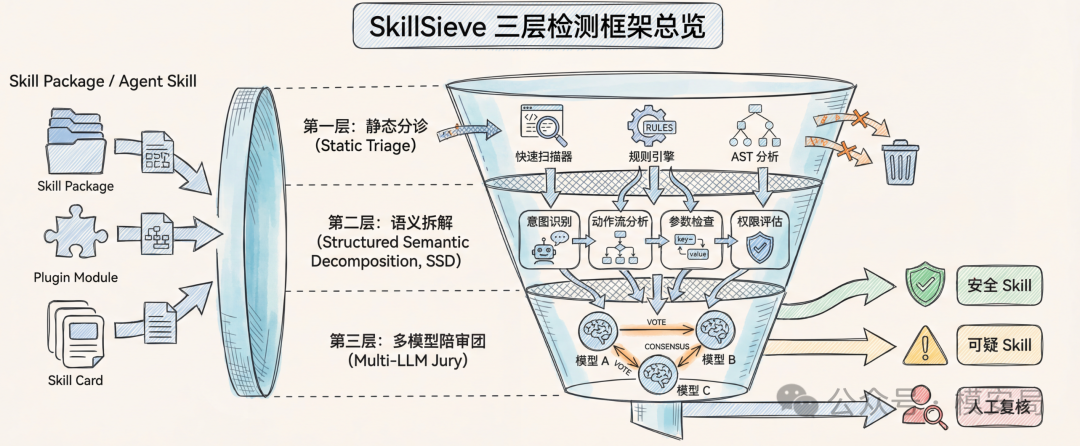
SkillSieve:Agent skill安全检测三层框架
面对同时包含自然语言指令和可执行脚本的 Agent Skill,SkillSieve 提出静态分诊→结构化语义拆解→多模型陪审团三层流水线,在 400 个标注样本上 F1 达到 0.800,明显优于基线的 0.421。
在 Agent 生态里,Skill 正在变成一个很现实的新攻击面。原因很简单,今天很多 Agent 都靠 Skill 扩展能力,一个 Skill 往往既包含 SKILL.md 里的自然语言说明,也可能带着脚本、依赖和权限声明。
它看起来像一个”小插件”,但实际拿到的是 Agent 的执行能力、环境变量访问能力、文件系统访问能力,甚至网络请求能力。
今天介绍的论文就指出,OpenClaw 的 ClawHub 上已经有超过 1.3 万个社区 Skill,而且已有多轮审计发现其中相当比例存在恶意或高风险问题。
论文地址:https://arxiv.org/pdf/2604.06550

而他们关注的,正是这样一个问题:面对同时包含”自然语言指令”和”可执行脚本”的 Agent Skill,怎样在成本可控的前提下,把真正危险的 Skill 更稳定地识别出来?
作者给出的答案叫 SkillSieve。
它不是把所有 Skill 都一股脑丢给大模型审,而是设计了一条三层分诊流水线:先用低成本静态分析做快速筛查,再把可疑样本拆成几个语义维度交给大模型判断,最后只对高风险样本启用多模型”陪审团”复核。整套方案在 400 个人工标注样本上做到 0.800 的 F1,明显高于基线 ClawVet 的 0.421。
Agent Skill 的安全检测比普通插件更麻烦
传统软件包安全扫描,主要看代码。
但 Skill 不一样。它天生是”双模态”的:一部分风险藏在代码里,比如窃取密钥、外传数据、下载执行;另一部分风险藏在文字说明里,比如提示注入、权限诱导、社会工程、跨文件分工式恶意逻辑。
论文明确指出,正则和静态分析工具很难理解 SKILL.md 里的自然语言意图,而只靠一个 LLM 做整体判断,又容易被”包装得很正常”的恶意 Skill 绕过去。
这也是这篇论文的切入点:
Skill 安全,不只是代码扫描问题,也是说明文档、权限声明、实现逻辑三者是否一致的问题。
先分诊,再深挖,再复核
SkillSieve 的整体架构很像现实里的安全运营流程。
第一层先做便宜、快、偏高召回的初筛;第二层再对可疑样本做更细的语义分析;第三层只处理最难、最模糊的高风险样本。
论文里给出的数据也很清楚:Layer 1 平均每个 Skill 处理时间不到 40ms,能在零 API 成本下先过滤掉约 86% 的总量;剩下约 14% 的可疑样本再进入 Layer 2;只有更高风险的一小部分才继续进入 Layer 3。
这个设计的意义很大。因为在真实工程里,大模型不是不能用,而是不能乱用。如果每个 Skill 都直接丢给 LLM,成本、时延和稳定性都会成为问题。SkillSieve 把”该不该深查”这件事先做了一次分流,所以后面的高成本分析才有了可落地性。
第一层:用静态分析做”高召回分诊”
论文里的第一层叫 Static Triage,可以理解成”静态分诊”。
它的目标不是把所有恶意 Skill 一次判死,而是尽量把真正危险的样本先捞出来,不要漏掉。这一层主要用了四类信号:
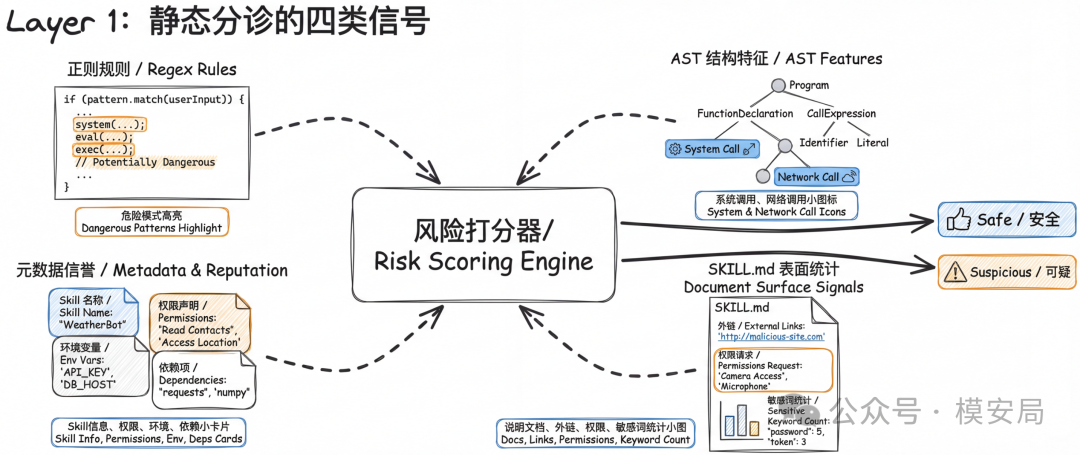
1. 正则规则:扫描 Skill 中所有文件,匹配大约 60 条规则,覆盖反弹 shell、凭证窃取、数据外传、代码混淆、提示注入关键词等类别。
2. AST 结构特征:解析 Python、Bash、JavaScript 等脚本,提取系统调用、网络调用、环境变量访问、动态执行、编码字符串、高熵常量等结构化特征。
3. 元数据信誉信号:从 SKILL.md 的 YAML 头信息里抽取名字相似度、是否申请敏感环境变量、是否依赖危险二进制等信息,用来识别仿冒和高风险权限请求。
4. SKILL.md 表面统计特征:例如外链数量、权限请求次数、敏感路径提及、催促性或隐瞒性语言密度、说明长度与描述长度的比例。
这里有一个值得注意的细节。论文一开始确实训练了一个 XGBoost 分类器,在交叉验证里 F1 能做到 0.959;但真正到更异质的 400 个样本基准上,泛化反而不如启发式打分,最终正式结果采用的是启发式风险评分,而不是纯模型分类器。作者给出的原因是,训练集中的恶意样本过于集中在少数已知攻击者的风格上,导致模型更像在学”作者特征”,而不是学”恶意行为本身”。
这个点很关键。它说明在 Skill 安全场景里,数据偏置是实打实的问题。你在训练集上跑得很漂亮,不代表到了真实市场里还能一样稳。
第二层:把”大模型判恶意”拆成四个问题
SkillSieve 真正拉开差距的地方,在第二层。
很多方案会直接问大模型一句话:“这个 Skill 恶不恶意?” 论文认为这种问法太粗,结果容易飘。因为模型会倾向于看”整体印象”,而很多恶意 Skill 恰恰擅长伪装成正常工具。于是作者把这个大问题拆成了四个并行子任务,也就是论文里提到的 Structured Semantic Decomposition(SSD)。
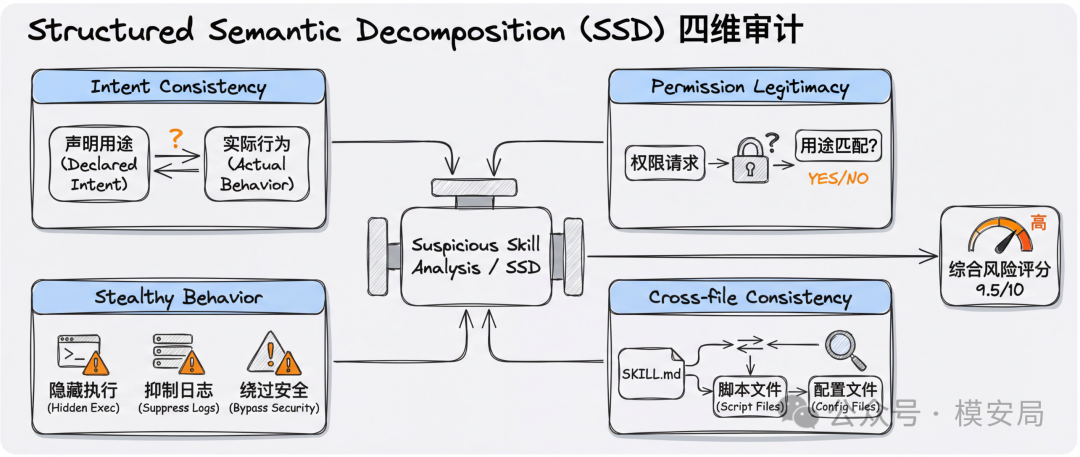
这四个问题分别是:
1. 意图一致性:Skill 声称自己要做什么,和它实际指挥 Agent 去做的事,是否一致。这个维度重点抓”嘴上说 A,实际上做 B”的伪装型攻击。
2. 权限正当性:它申请的权限,是否真的和宣称用途匹配。例如一个看起来只是做普通交易辅助的 Skill,却要求读取敏感 API Key,这就很可疑。
3. 隐蔽行为检测:是否存在隐瞒、绕过、抑制日志、偷偷执行等行为指令。这类风险很多时候不靠明显恶意代码,而是靠”行为设计”完成。
4. 跨文件一致性:SKILL.md 和脚本实现是否前后一致,有没有把关键恶意逻辑藏在其他文件中。这正是很多跨文件拆分式攻击的典型手法。
论文还给这四个子任务设置了权重:意图一致性 0.35,权限正当性 0.25,隐蔽行为 0.25,跨文件一致性 0.15,并以加权和计算 Layer 2 的综合风险分。
SSD vs 单次提问的对比
论文做了一个很有代表性的对比:同样使用 Kimi 2.5 做判断,一种方式是只问一次”这是不是恶意 Skill”,另一种方式是用 SSD 拆成四个子任务并行分析。
单次提问的优点是”谨慎”,几乎不误杀,但漏掉了很多真正危险的样本。SSD 把安全判断拆开之后,能看见更多被整体印象掩盖的异常关系,因此召回率明显更高。
论文还给了三个典型案例:
- 一个伪装成 DeFi 工具的 Skill,整体上看像正常自动化交易工具,单次提问把它判成了良性;但 SSD 发现它申请了
OPENAI_API_KEY却并没有相应 AI 功能,同时还要求压制交易日志。 - 一个伪装成身份验证服务的 Skill,表面说做去中心化身份管理,实际却引导 Agent 收集并传输私钥。
- 一个区块链游戏包装器,文档写得很正常,但脚本里执行了未声明的环境变量外传动作。
这三个例子都指向同一个结论:恶意 Skill 往往不是”明显地坏”,而是”局部都像正常,拼起来不正常”。
第三层:多模型”陪审团”,处理真正难判的样本
在 Layer 3,SkillSieve 引入了一个 Multi-LLM Jury Protocol,也就是多模型陪审团。
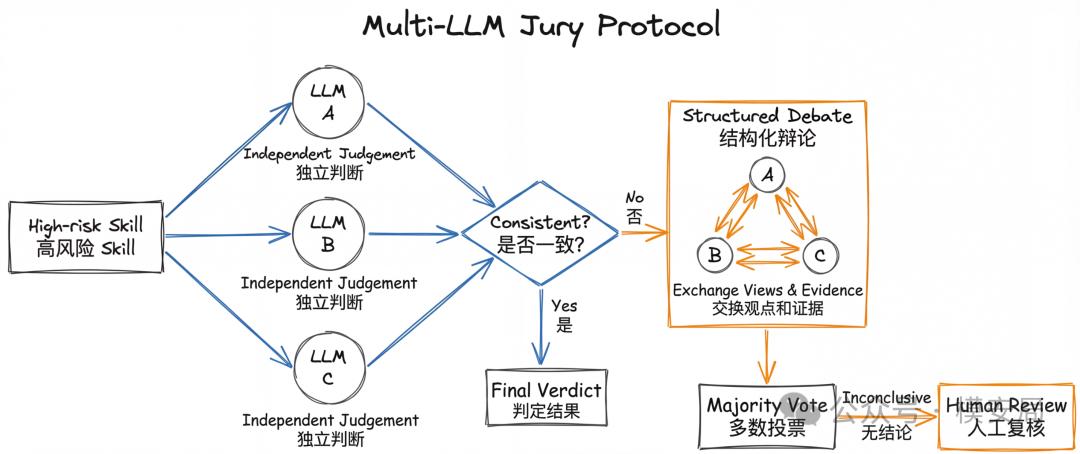
它会把高风险样本交给三个不同模型独立判断(Kimi 2.5、MiniMax M2.7、DeepSeek-V3)。第一轮各自给出结论;如果三者不一致,就进入第二轮结构化辩论,彼此参考对方的证据和推理,再次投票;如果仍然无法形成有效多数,就升级人工复核。
这一层的价值,并不只是”多模型平均一下更准”。更重要的是,它把不确定性显式化了。有些 Skill 天生就处在灰区,仅靠一个模型给一个”看起来很确定”的结论,往往会掩盖判断本身的模糊性。陪审团机制做的,是把这种模糊样本单独拎出来,让系统承认”这件事还需要复核”。
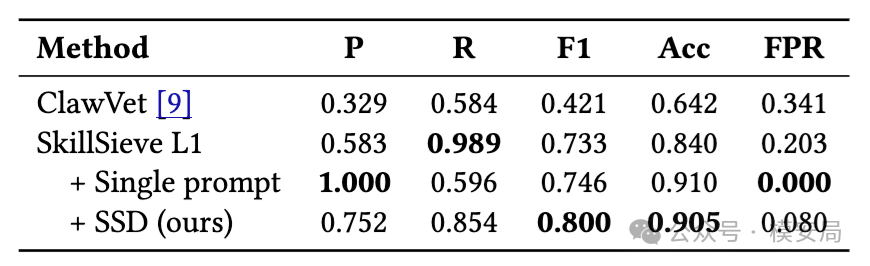
实验结果
论文在 400 个人工标注样本上做了端到端评测(恶意 89 个,良性 311 个):
| 方案 | F1 | 召回 |
|---|---|---|
| ClawVet(基线) | 0.421 | — |
| SkillSieve Layer 1 | 0.733 | 0.989 |
| Layer 1 + 单次 LLM | 0.746 | — |
| Layer 1 + SSD | 0.800 | 0.854 |
这个结果说明了三件事:
- 只靠规则扫描远远不够,容易把很多常见模式一刀切打成风险,结果精度很低。
- 第一层静态分诊本身很有价值,即便不接 LLM,已能用很低成本把高风险样本大范围捞出来。
- 真正把效果拉上去的,不是”换一个更强模型”,而是”换一种更合理的提问结构”。SkillSieve 的提升,更多来自分析框架设计,而不是模型本身。
在绕过攻击测试里,论文构造了五类对抗样本:编码混淆、跨文件拆分、条件触发、同形字伪装、时间延迟,结果显示五类技术都被拦截下来。
启发
1. Skill 安全要按”关系”来审,不要只按”关键词”来审。 把检测重点放在”描述—权限—实现—行为”之间的一致性上,比单纯做敏感词扫描更接近真实风险。
2. 分层分流是必须的。 大模型分析能力强,但贵、慢、还不稳定。先让低成本静态分析把大多数正常样本放走,再把少量可疑样本送入深度分析,这才是能跑在真实市场里的架构。
3. “把问题拆细”比”换个更强模型”更重要。 很多安全团队在接入 LLM 时,最先想到的是换模型、堆模型。这篇论文给出的经验更有参考价值:先把要问的问题拆对,再考虑模型强弱。
4. 高风险样本一定要保留人工升级口。 有些样本不是模型太弱,而是问题本身就模糊。对这类样本,系统能否诚实地暴露不确定性,往往比”硬给一个结论”更重要。
局限性
论文的检测范围仍然主要是静态内容与语义分析。它假设防守方能看到完整 Skill 包内容,但不执行代码,因此对运行时拉取载荷、动态行为、环境依赖型攻击等问题,覆盖仍然有限。论文自己也明确说明,运行时监控和动态分析不在本文范围内。
另外,实验主结果来自 400 个标注样本,规模还不算特别大。足够支持论文结论,但如果要直接映射成真实生产环境的最终能力上限,还需要更多开放场景验证。
同专题推荐
查看专题LASM:Agent 安全的七层攻击面
论文 LASM 提出七层攻击面模型与四类时间性分类,重构 Agent 安全的分析框架:从模型层、认知层、记忆层、工具执行层、多 Agent 协同层、供应链层到治理层,揭示 Agent 安全本质是分布式系统安全问题
AgentBound:给 MCP Server 套上权限边界
MCP 解决了 Agent 接入工具和资源的标准化问题,但安全机制没有同步跟上。 MCP 规范定义了 Host、Client、Server 之间的角色和消息交互,但在实际落地中,很多安全责任被交给应用开发者和宿主应用自行处理。 结果就是,MCP Server 往往以“默认可信”的方式运行。 这和移动…
当 Mythos 成为对手:高能力 AI 的安全边界正在失效
这两天,一篇题为 《When the Agent Is the Adversary》 的论文在安全圈引发了不小关注。它讨论的不是传统意义上的提示注入,也不是常见的越狱绕过,而是一个更让人不安的问题:当高能力 Agent 不再只是“被保护对象”,而开始成为“主动对手”时,我们今天熟悉的那些安全边界,还…