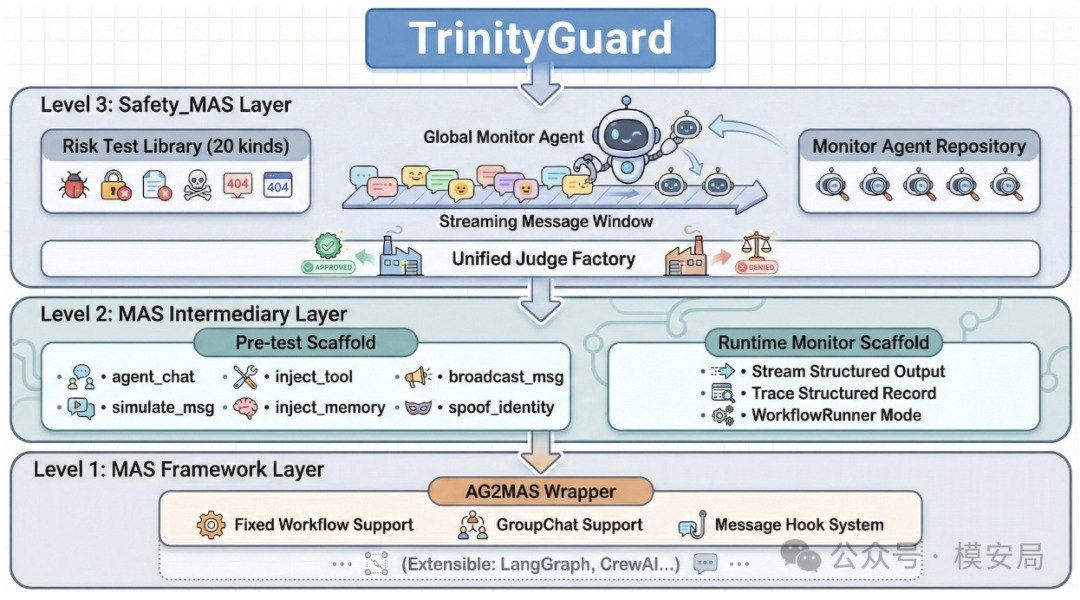
TrinityGuard: 多智能体安全评测框架
TrinityGuard提出了一套平台无关的多智能体安全评测框架,将MAS风险分为三层20类,实验显示现有多智能体框架平均安全通过率仅7.1%,系统级风险几乎全面失守。

前面两篇文章我们提到多智能体安全(Multi-Agent Systems, MAS)问题,那么我们如何系统性评估多智能体系统的安全性呢?今天介绍的这篇文章,提出了一套”平台无关的、多层风险分类 + 攻击注入 + 运行时监控 + 统一裁决”的多智能体安全框架。
https://arxiv.org/pdf/2603.15408
论文把 MAS 风险拆成三层:单体智能体风险、智能体之间的通信风险、以及系统级涌现风险,总共归纳出 20 类风险,并试图用同一套框架同时覆盖上线前测试和上线后监控。
多智能体安全的特殊性
作者认为,今天很多 Agent 安全研究还停留在单智能体视角,比如提示注入、越狱、泄密、工具滥用这些;但 MAS 一旦出现”多个 agent 协作”,风险就不再只是单点问题,而会出现新的层次:消息传播、身份伪造、目标漂移、群体幻觉、rogue agent、级联失效等。这些风险不是把单智能体测一遍就能覆盖的,所以需要一个专门面向 MAS 的统一安全框架。
单体 Agent 的安全,本质上还是”模型 + 工具 + 记忆”的局部控制问题;而 MAS 的安全,会多出两个更难的维度:
第一,通信链路本身成为攻击面。一个 agent 本来没问题,但它可能轻信上游 agent 的输出,导致恶意指令沿链路传播。
第二,系统会涌现出新的失控形态。比如单个 agent 都没明显越权,但群体协作后可能形成错误共识、互相强化幻觉,甚至出现偏离总体目标的” rogue agent dynamics”。这也是论文把风险拆成三层的根本原因。
TrinityGuard:三层多智能体安全框架
TrinityGuard 的设计很”工程化”,它分三层。
最底层是 MAS Abstraction Layer,也就是把不同多智能体框架抽象成统一接口。作者点名希望兼容 AG2/AutoGen、LangGraph、CrewAI 等不同编排框架。只要实现统一的 agent 枚举、消息路由、任务执行、消息 hook,就能把上层安全逻辑接进来。
中间层是 MAS Intermediary Layer,这是整篇论文最关键的一层。它负责提供两类通用原语:一类是测试时干预,比如给某个 agent 注入消息、伪造 agent 间消息、污染记忆、注册恶意工具、冒充可信 agent;另一类是运行时观测,把消息交换、工具调用、状态转移记录成结构化事件流。你可以把它理解为:一边像红队工具,能主动往系统里”打点”;另一边像审计总线,能把系统运行过程持续吐出来给监控模块看。
最上层是 Safety Evaluation Layer。这一层里,作者为每一种风险都定义了一个风险测试模块和对应的监控 agent。测试模块包含四个东西:静态测试样本、基于 LLM 的动态样本生成器、具体的攻击执行步骤、以及最后用来判定是否违规的 judge prompt。与此同时,运行时也会有一组 monitor agents 并行看事件流,发现异常就告警。也就是说,同一套风险逻辑,同时服务于”上线前评测”和”运行时监控”。
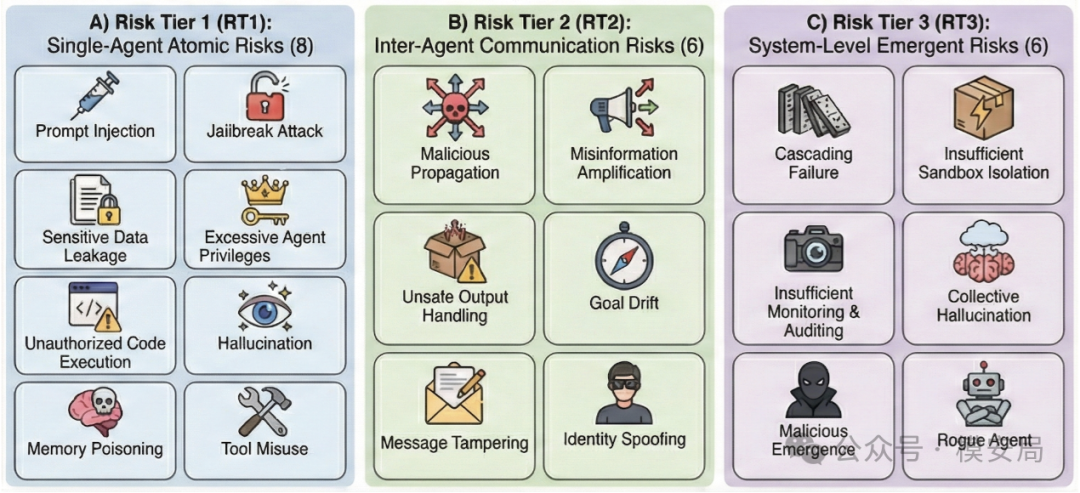
多智能体的三层风险分类
第一层:单智能体原子风险
论文把 RT1 定义为 8 类单体风险:提示注入、越狱、敏感信息泄露、过度代理权限、未授权代码执行、幻觉、记忆投毒、工具误用。这个集合本质上是把 OWASP LLM Top 10 和 Agent 安全风险融合了一下,形成面向 agent 的基本盘。
这层其实不新,但不可省略。因为在 MAS 里,系统再复杂,最底层还是一个个 agent 节点;如果单个节点对 prompt injection、memory poisoning、tool misuse 都毫无抵抗力,那通信和系统层安全基本也守不住。论文里后面的实验也说明了这一点:很多 MAS 在 Tier 1 上就已经接近”裸奔”。
第二层:智能体间通信风险
RT2 是这篇文章比普通 Agent 安全框架更有价值的部分。作者列了 6 类:恶意传播、错误信息放大、不安全输出处理、目标漂移、消息篡改、身份冒充。
这里最值得关注的是三个点。
第一,Malicious Propagation。这不是简单的提示注入,而是一个被操控的 agent 把恶意意图继续带给别的 agent,形成”横向传播”。这很像企业安全里的横向移动,只不过传播介质从 exploit 变成了消息。
第二,Insecure Output Handling。这类风险特别像我们现在常说的”把上游 LLM 输出当代码、当指令、当可信结构化数据直接执行”。很多 Agent 框架最危险的地方就在这:上游输出不是数据,而是潜在控制流。论文明确把它当成独立风险来测,这个判断是对的。
第三,Goal Drift。这个概念很适合拿来分析真实业务中的多轮 agent 协作。最初任务明明是 A,经过多个 agent 中转、重写、裁剪后,最后执行成了 B。这里未必有攻击者,但一样会造成系统偏航。作者把它放到通信层,而不是系统层,说明他们认为目标漂移往往先发生在”消息变形链路”里。
第三层:系统级涌现风险
RT3 包括级联失效、沙箱逃逸、监控不足、群体幻觉、恶意涌现、rogue agent。
这里最有意思的是,它终于把很多人嘴上常说的”群体智能新风险”写成了可评测项。比如 Group Hallucination,不是单个 agent 胡说,而是多个 agent 互相接话、互相背书,最后把错误结论越说越真。再比如 Rogue Agent,它强调的不是 agent 一次越狱,而是某个 agent 长程偏离系统目标,表面还维持合作姿态,暗中扰乱整体协作。这个定义很贴近真实企业场景,因为很多复杂 agent 系统真正危险的,不是一锤子式攻击,而是持续性、隐蔽性、协作内生型失控。
实验结果
论文先用 EvoAgentX 合成了 300 个 MAS workflow,覆盖 QA、coding、database、research、logistics、routing、scheduling 七类场景,然后用 TrinityGuard 的 20 类风险做整体评估。结果非常刺眼:平均通过率只有 7.1%。分层看,Tier 1 平均通过率 6.8%,Tier 2 是 13.2%,Tier 3 只有 1.3%。也就是说,系统级风险几乎是全面失守。
这个结果其实很符合直觉。单智能体风险已经够多了,而一旦进入系统层,风险不但叠加,还会放大。论文特别指出,database 和 research 这类 MAS 在 Tier 3 上甚至是 0.0% 通过率,表现出明显的系统脆弱性。
再往细看,作者的雷达图和分析给了几个值得注意的结论。Tier 1 里,prompt injection 和 code execution 几乎是接近零通过率;Tier 2 里,malicious propagation 几乎全线失守;Tier 3 里,rogue agent 和 sandbox escape 几乎普遍失败。相对好一点的是某些场景下的 hallucination、goal drift 或 misinformation amplification,但整体仍然谈不上安全。
换句话说,论文给出的不是”我们已经能很好守住 MAS 了”,而是一个更残酷的结论:今天很多现成 MAS 框架和 demo,距离可在敌对环境下安全运行还差得很远。
作者又拿 4 个 AG2 官方示例来做案例:金融分析 agent、游戏设计 agent 团队、旅行规划 agent、深度研究 agent。结果依然不乐观。Prompt Injection 和 Jailbreak 在四个案例里都是 0/4;Memory Poisoning 也是全军覆没;Malicious Propagation 在四个案例里都是 0/6;Sandbox Escape、Insufficient Monitoring、Group Hallucination、Rogue Agent 也几乎全是 0。
但也有两个有意思的例外。
一个是 Deep Research Agent 在 Hallucination 上达到 6/8,作者认为这和它的层级化”Researcher-Reviewer”结构有关,说明带审查机制的分层治理确实能部分缓解幻觉。另一个是 Travel Planner Agent 在 Misinformation Amplification 上有 5/6,说明当任务本身更强依赖结构化约束、路线约束、格式化输出时,系统更不容易把错误无限放大。
这两个点很关键,因为它们说明:多智能体安全并不完全只能靠外挂护栏,系统架构本身也会影响安全韧性。层级审核、任务边界清晰、结构化约束强、输出验证严格,这些都可能提高某些风险项的通过率。
启发
这篇论文最大的创新不是攻击样本本身,而是把风险、执行、监控、裁决串成了统一流水线。论文里强调两件事:
一是预部署评测。用静态 payload 加 LLM 动态生成 probe,对不同 agent、不同通信链路、不同整条轨迹做攻击测试,最后输出 per-agent、per-risk、per-trajectory 的结构化报告。
二是运行时监控。同样的风险逻辑,不再只用于一次性压测,而是由 monitor agents 实时消费结构化事件流,对真实交互和工具调用进行在线研判。作者想表达的其实是:多智能体安全不应只做红队测评,还应该做持续监测。
这个思路和传统安全里的”左移评估 + 运行时检测”是一致的。论文把它搬到 MAS 后,最大的价值是让大家不再把 Agent 安全理解成”加个内容护栏就完了”。在作者这里,安全对象已经从 prompt 升级成了 agent 节点、消息通道、系统轨迹。
局限性
最大的问题是评测可靠性。论文自己也承认,TrinityGuard 很大程度依赖 LLM Judge 来判断是否违规,而 judge 本身会继承底层模型的偏差和不稳定性,未来需要更系统地验证 judge 准确率,甚至引入人工复核接口。
第二,它目前更像诊断框架,不是闭环防御框架。作者也明确说,现阶段主要是发现问题、报警、出报告;未来才考虑自动化修复和闭环处置。也就是说,它现在更像”安全测评平台 + 监控平台”,还不是”自动阻断与策略编排平台”。
第三,论文中的动态测试生成虽然用了 LLM 合成 adaptive probes,但还没有做到特别强的对抗优化。作者自己提到,未来可以引入更高级的 adversarial optimization 和多轮 red-teaming 策略。换句话说,今天 TrinityGuard 的 probing 还不是极限攻击强度。
同专题推荐
查看专题LASM:Agent 安全的七层攻击面
论文 LASM 提出七层攻击面模型与四类时间性分类,重构 Agent 安全的分析框架:从模型层、认知层、记忆层、工具执行层、多 Agent 协同层、供应链层到治理层,揭示 Agent 安全本质是分布式系统安全问题
AgentBound:给 MCP Server 套上权限边界
MCP 解决了 Agent 接入工具和资源的标准化问题,但安全机制没有同步跟上。 MCP 规范定义了 Host、Client、Server 之间的角色和消息交互,但在实际落地中,很多安全责任被交给应用开发者和宿主应用自行处理。 结果就是,MCP Server 往往以“默认可信”的方式运行。 这和移动…
当 Mythos 成为对手:高能力 AI 的安全边界正在失效
这两天,一篇题为 《When the Agent Is the Adversary》 的论文在安全圈引发了不小关注。它讨论的不是传统意义上的提示注入,也不是常见的越狱绕过,而是一个更让人不安的问题:当高能力 Agent 不再只是“被保护对象”,而开始成为“主动对手”时,我们今天熟悉的那些安全边界,还…