不止于隐私:从ChatGPT聊天记录推断用户人格特征
过去我们谈 AI 隐私风险,通常关注的是用户有没有把身份证、手机号、住址、病历、银行卡号、账号密码发给大模型。但一篇来自 ETH Zurich 的论文提醒我们,真正麻烦的地方可能不止这些显性敏感信息。
过去我们谈 AI 隐私风险,通常关注的是用户有没有把身份证、手机号、住址、病历、银行卡号、账号密码发给大模型。但一篇来自 ETH Zurich 的论文提醒我们,真正麻烦的地方可能不止这些显性敏感信息。

https://arxiv.org/pdf/2604.19785
如果一个人长期使用 ChatGPT,他的提问方式、求助内容、情绪表达、职业困扰、关系咨询、健康焦虑和消费决策,会不会逐渐暴露出这个人的人格特征?
论文给出的答案是:会。
这种风险并不是 AI 时代才出现。搜索引擎、社交平台、IM 工具、电商平台早就在通过用户数据做画像。但对话式 AI 的变化在于, 用户把过去分散在不同平台里的碎片化行为,集中交给了一个更会理解、更会总结、更会记忆,也更可能反过来影响自己的智能系统。
人格推断不再只是后台广告模型的能力,它正在进入人与 AI 的日常对话之中。
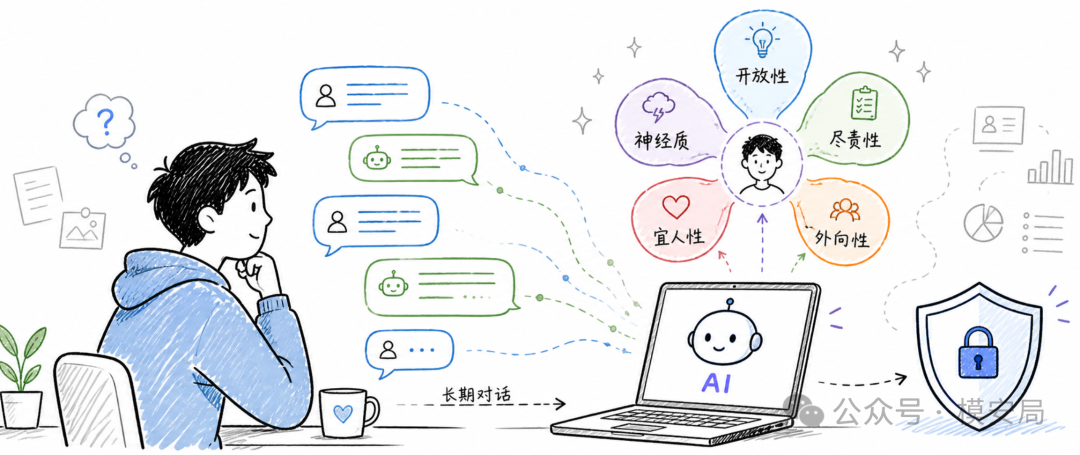
大五人格测试
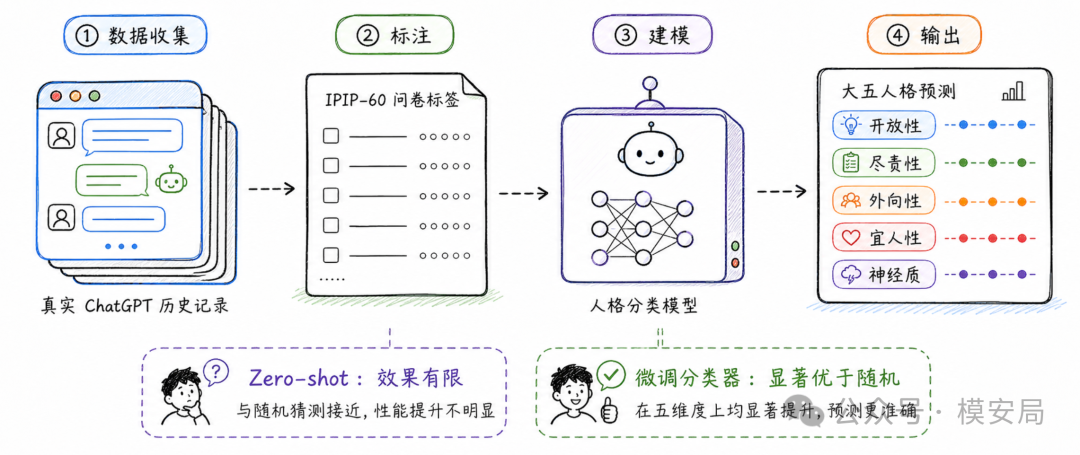
研究者收集了 668 名美国和英国英语用户的真实 ChatGPT 历史记录,总共包含 62090 个独立聊天会话。
与此同时,研究者让这些用户完成 IPIP-60 大五人格问卷,用问卷结果作为人格标签,再训练模型去判断:
只看用户过去和 ChatGPT 说过的话,能不能推断出这个人在五个人格维度上的高低倾向。
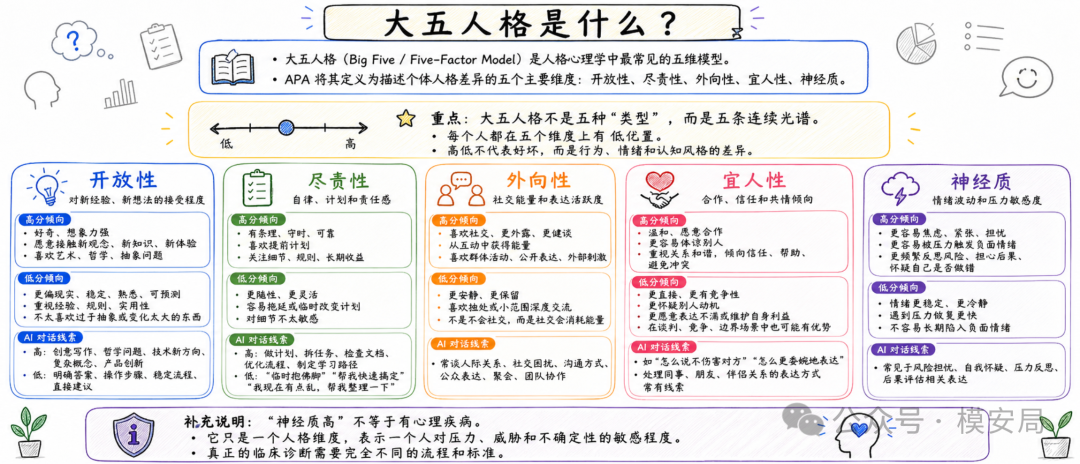
论文使用的 IPIP-60,就是一个常见的大五人格测量问卷。
用户需要回答 60 道自陈题,比如自己是否容易紧张、是否有条理、是否喜欢尝试新事物等。
研究者根据问卷结果,把每个用户在五个人格维度上的分数切成低、中、高三档,然后再看模型能不能从聊天记录中把这些档位猜出来。
这就把问题变成了一个非常明确的实验:用户没有主动告诉模型“我是外向的人”或者“我很容易焦虑”,模型能不能仅凭长期聊天痕迹推断出来?
更多上下文,让AI更了解自己
这篇论文最重要的地方,不是证明“AI 能算命”,也不是说大模型已经可以精准读懂每一个人的性格。
它真正提醒的是一种更隐蔽的隐私风险: 推断型隐私风险 。
传统隐私保护更关注显性信息。
比如用户输入了手机号、身份证号、住址、银行卡号,系统可以通过规则、模型或正则表达式识别出来,然后提醒、脱敏或拦截。这类风险相对清晰,因为敏感字段本身就在文本里。
但人格特征不一样。
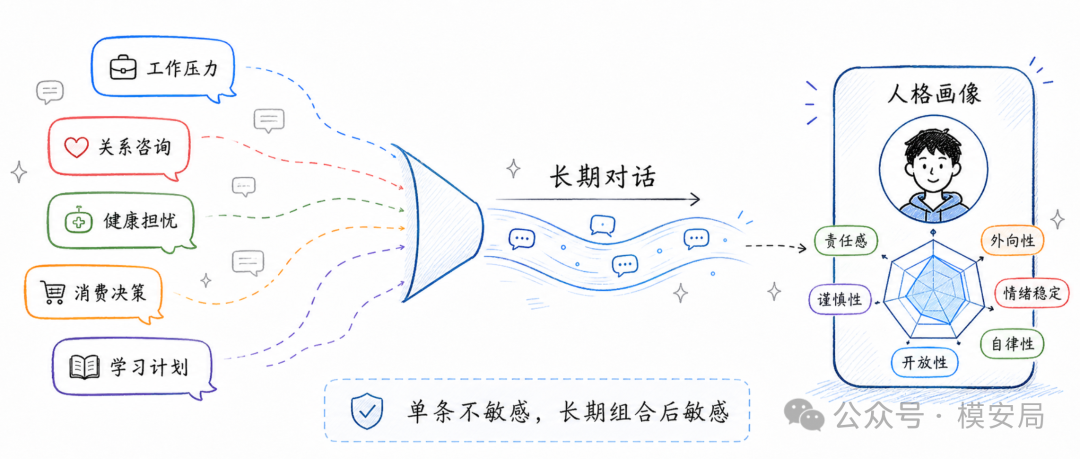
用户可能从来没有说过“我是一个外向的人”,也没有说过“我神经质比较高”。可如果他长期向 AI 倾诉工作压力、亲密关系、社交冲突、健康焦虑、消费纠结和职业规划,这些内容组合起来,就可能变成稳定的人格画像信号。
单条 prompt 可能不敏感,一组 prompt 就可能非常敏感。
比如一个用户今天问“领导一直不回我消息怎么办”,明天问“我是不是太在意别人评价了”,后天问“怎么委婉拒绝朋友又不伤害关系”,再过几天问“我最近总担心自己工作做不好”。
这些问题分开看,只是普通求助;连在一起看,就开始呈现出这个人的压力敏感度、人际处理方式、边界感和自我评价模式。
这也是对话式 AI 的特殊之处。
用户和搜索引擎交互时,通常输入的是短 query;和社交平台交互时,内容可能是公开表达;和 IM 工具交互时,内容是人与人之间的通信。
而在 AI 助手里,用户往往会主动提供更多背景,因为他希望模型给出更贴合自己的建议。
为了得到更好的答案,用户会告诉 AI 更多上下文。也正是这些上下文,让 AI 更容易理解用户。
模型推断人格的准确率已明显高于随机
论文做了两类实验。
第一类是直接让大模型 zero-shot 推断,也就是不专门训练模型,只让模型根据用户聊天内容去填写人格问卷。
这个结果并不强,整体没有显著优于随机基线。三分类任务的随机准确率大约是 33.3%,zero-shot 的结果虽然略高,但不足以说明模型已经能够稳定推断人格。
这点很重要。论文并没有夸张地说“大模型已经可以精准判断你的性格”。如果只靠通用模型直接猜,效果其实有限。
真正有意思的是第二类实验。
研究者用用户聊天记录和问卷标签训练了专门的人格分类器。经过微调后,模型在五个人格维度上都显著优于随机基线。
其中,外向性的单聊天预测准确率达到 44.2%,宜人性达到 40.2%,尽责性达到 39.1%,神经质达到 38.1%,开放性达到 36.9%。
这些数字看起来并不惊人,甚至离“精准识别”还很远。
但在隐私风险里,很多时候并不需要百分之百准确。广告推荐、舆论影响、内容投放、消费引导本来就不是追求对每个人完全判断正确,而是追求在大规模人群中比随机更有效。
如果一个系统能把一群用户更好地分成“更容易焦虑”“更重视关系和谐”“更喜欢新鲜体验”“更适合被某种话术说服”的群体,那么它已经具有商业价值,也已经具有操纵风险。
论文进一步把多个聊天会话汇总到用户级别后发现,宜人性和神经质两个维度表现更稳定。也就是说,虽然单次对话可能噪声很大,但当一个用户长期使用 ChatGPT 后,模型对他的情绪敏感度和人际合作倾向,反而更容易形成稳定判断。
这也符合直觉。
一个人是否外向,可能取决于当时聊什么场景;但一个人是否容易担忧、是否总是顾及别人感受,往往会在长期表达方式中反复出现。
哪些聊天最容易暴露人格?
论文最有价值的部分,是把风险拆到了具体对话类型上。结果显示,人格推断风险并不是平均分布在所有聊天中的。
和 心理健康、情绪状态、人格、自我反思 相关的聊天,往往更容易暴露用户的人格特征。比如用户在对话里反复描述自己的焦虑、压力、情绪波动、自我怀疑,模型更容易捕捉到神经质相关信号。用户讨论亲密关系、朋友冲突、家庭关系、沟通方式时,外向性和宜人性相关信号也会变得更明显。
工作和教育相关内容 也很重要。一个人如何描述自己的工作状态、学习计划、职业焦虑、任务安排和目标管理,很可能暴露他的尽责性、宜人性和开放性。比如有些用户会让 AI 帮自己拆计划、做复盘、设计学习路径;有些用户则更常表达混乱、拖延、压力和临时求助。这些差异本身就可能成为模型判断人格的线索。
健康、健身、美容、自我照护类 对话同样敏感。因为用户谈健康时,经常不只是谈身体状况,还会谈对风险的担忧、对外貌的在意、对生活方式的控制感,以及对不确定性的反应方式。
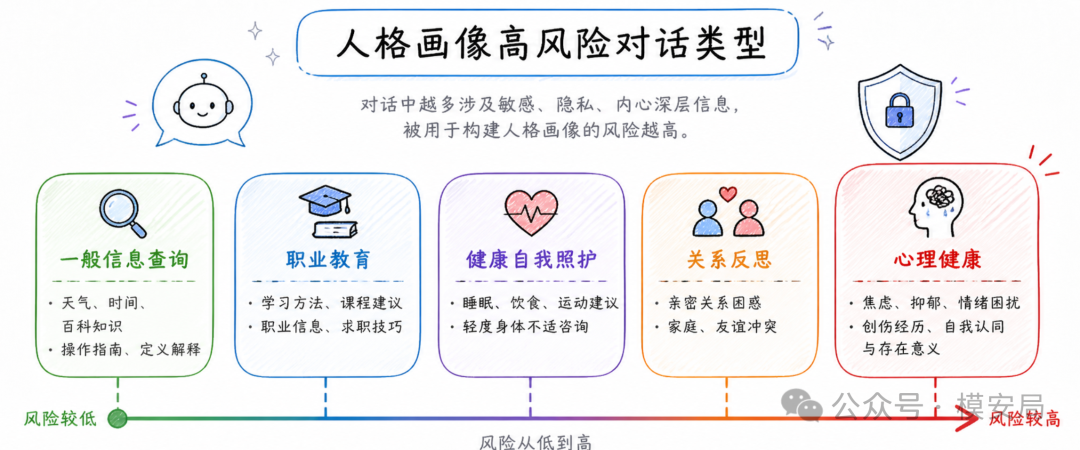
这意味着,AI 隐私防护不能只盯着身份证号、手机号和银行卡号。对话中的“敏感上下文”同样重要。心理状态、关系困扰、职业焦虑、健康担忧、消费偏好、价值判断,这些内容未必是传统意义上的 PII,却可以构成很强的画像信号。
这类风险不是 AI 独有,但 AI 把它推到了前台
有一个问题必须说清楚:人格推断型风险并不是 AI 独有的。
传统 UGC 平台、IM 平台、搜索引擎、电商平台、浏览器和广告平台,都能通过用户输入和行为数据做画像。用户搜索什么、点赞什么、评论什么、买什么、停留多久、和谁聊天,本来就可以用于兴趣建模、行为预测和受众分群。互联网广告行业过去很多年一直在做类似事情,只是它们通常不叫人格推断,而叫用户画像、标签体系、转化率预估、推荐策略。
所以,如果把这篇论文解读成“AI 第一次带来了人格推断风险”,那是不准确的。
更准确的说法是: AI 助手改变了人格推断风险的形态。
搜索引擎拿到的是用户想查什么,社交平台拿到的是用户愿意表达什么,电商平台拿到的是用户想买什么,IM 平台拿到的是人与人之间如何交流,它们都能做画像,但 数据往往分散在不同场景里 。
对话式 AI 的特殊之处在于,用户会把很多过去分散在不同平台的数据,主动汇聚到一个界面里。
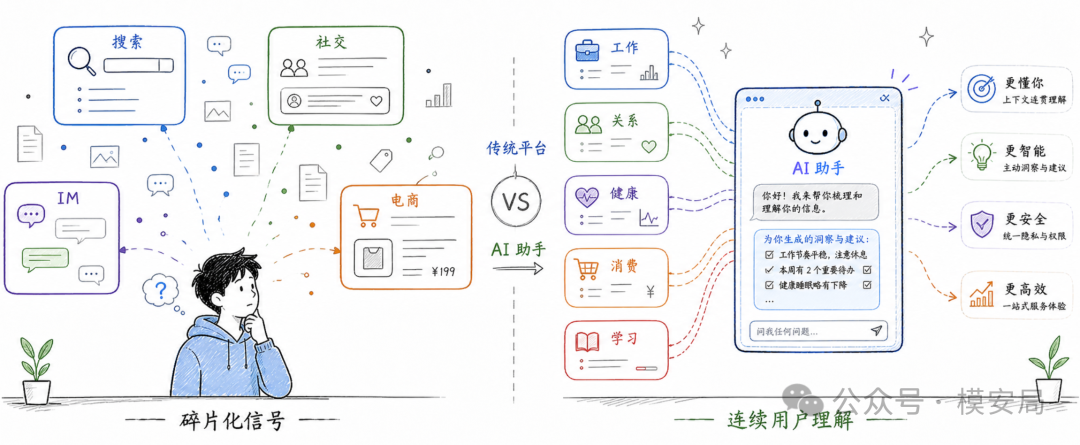
一个人在搜索引擎里查“失眠怎么办”,在社交平台看“职场焦虑”,在微信里和朋友聊“领导不回消息”,在购物平台比较“助眠产品”,这些数据本来分散在不同系统中。而当他面对 AI 助手时,很可能会直接说:“我最近睡不好,工作压力很大,领导不回我消息,我总觉得自己是不是哪里做错了,有没有办法让我放松一点?”
这句话里同时包含健康状态、工作压力、人际关系、情绪模式、自我评价和求助方式。它的语义密度远高于一条搜索 query。
更关键的是,AI 助手本身就是一个理解系统。传统平台要做人格画像,通常需要数据团队、推荐算法、广告系统和特征工程。对话式 AI 天然擅长从自然语言中总结偏好、情绪、目标和价值观。等到长期记忆、个性化助手、Agent 工具调用、跨应用上下文接入成为常态,系统对用户的理解会越来越连续。
这就是 AI 场景里更值得警惕的地方:人格推断不再只是后台广告系统的能力,它可能变成前台交互的一部分。模型会在对话中说:“我记得你之前提到自己容易焦虑”“你一贯比较追求确定性”“你可能更适合保守一点的选择”。
这些话听起来很贴心,但它们背后就是用户画像的显性化。
“知道你”之后还能“影响你”
单纯知道用户是什么样的人,已经构成隐私风险。但 AI 助手更进一步的问题在于, 它不只是观察用户,还会参与用户的判断过程 。
如果一个系统知道某个用户容易焦虑,它可以用更安抚的语气让用户依赖自己;如果知道某个用户很重视他人评价,它可以用关系压力影响他的选择;如果知道某个用户开放性高,它可以推送更新奇、更激进的产品和观点;如果知道某个用户尽责性高,它可以用目标、计划和责任感驱动他行动。
在广告推荐里,这意味着更细粒度的说服策略。在舆论场景里,这意味着更精准的叙事投放。在消费场景里,这意味着更适配人格弱点的营销话术。在 Agent 场景里,这甚至可能影响用户授权、交易、决策和行动。
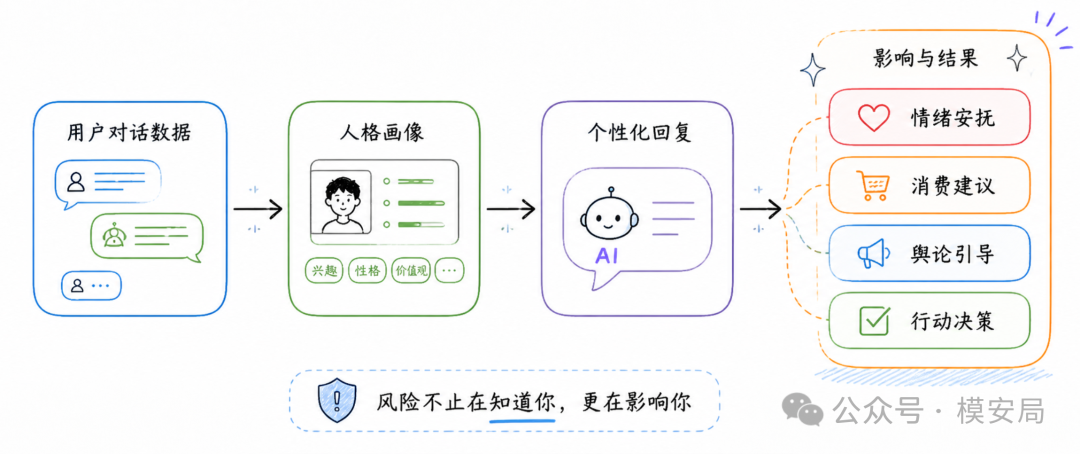
这也是为什么人格推断风险不能只被看作“隐私问题”。它还和操控、依赖、个性化诱导、算法治理有关。
过去,平台对用户做画像,更多发生在后台。用户看到的是推荐内容、广告内容和排序结果。到了 AI 助手这里,画像可能直接进入对话过程。系统会根据它对用户的理解,决定如何解释、如何建议、如何安慰、如何推动下一步行动。
这就是从“后台画像”到“前台说服”的变化。
对 AI 安全产品意味着什么?
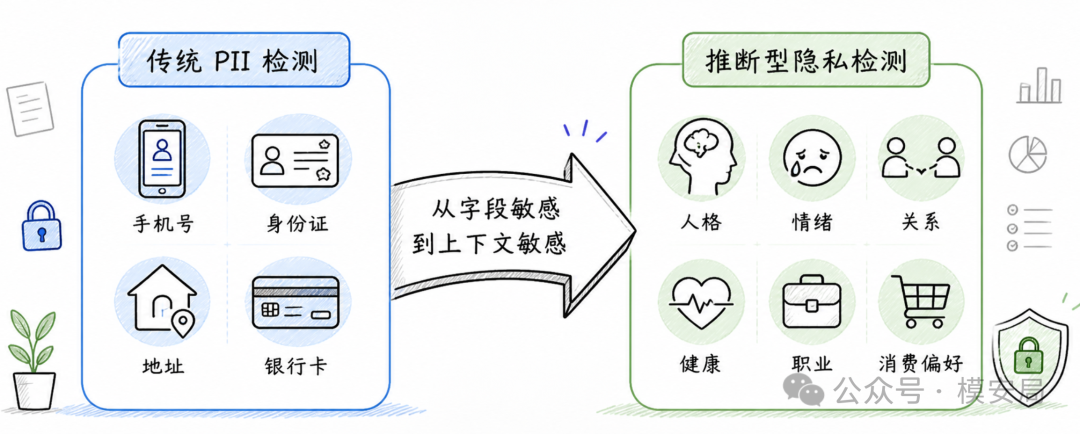
这篇论文对 AI 安全产品最大的启发,是隐私防护不能停留在 PII 检测。
身份证号、手机号、住址、银行卡号、账号密码当然要识别,这些是最基础的显性敏感信息。但在对话式 AI 和 Agent 系统里,还需要识别另一类风险: 可推断画像信号 。
这类信号不一定包含明确敏感字段,却可能帮助系统建立用户画像。比如长期的职业焦虑、关系冲突、健康担忧、消费偏好、政治态度、情绪表达和自我反思,都是可以被聚合、建模和利用的信号。
从产品设计上看,这类风险未必适合简单拦截。因为用户向 AI 咨询心理压力、关系问题、职业选择和健康困扰,本身是合理需求。如果一刀切拦截,产品体验会非常差,也会让 AI 助手失去价值。
更可行的方式是做 风险分级 和 使用边界控制 。对于高画像密度的内容,系统可以提醒用户这类信息可能被用于长期画像;可以默认不进入长期记忆;可以限制跨服务共享;可以禁止用于广告、推荐和商业画像;可以提供本地化处理、对话后删除、自动脱敏和记忆隔离等能力。
对企业级产品来说,还需要考虑 组织内部的数据边界 。员工用 AI 处理职业规划、绩效材料、团队冲突、客户沟通和研发文档,这些内容既可能泄露个人画像,也可能泄露组织画像。企业 AI 网关如果只做关键词审计,很难覆盖这种长期推断风险。
对监管来说,这类风险也提出了一个新问题:只要求平台保护显性个人信息是不够的。平台如何处理从用户长期交互中推断出来的人格、情绪、偏好和脆弱性,应该成为 AI 隐私治理的一部分。
不要夸大,也不要低估
这篇论文的结论需要冷静看,它并没有证明 AI 可以精准读心,实验准确率大多在 36% 到 48% 之间,相比随机基线有明显提升,但距离稳定、精确、可用于个体判断的人格测量还有距离。样本也只覆盖美国和英国英语用户,没有覆盖中文用户、多模态输入、语音对话、长期记忆和真实 Agent 工具调用。
但这并不影响论文的重要性,因为在大规模系统里,风险不一定来自百分之百准确的判断。很多商业和操控场景,只需要比随机更有效一点,就足够产生影响。尤其当用户持续使用 AI,把工作、生活、情绪、关系和消费决策都放进同一个系统后,画像信号会不断累积。
今天的研究只是在真实 ChatGPT 历史记录上做人格三分类。未来如果结合长期记忆、语音语调、图片文件、浏览记录、日程邮件、工具调用和多轮 Agent 行动轨迹,系统对用户的理解会更完整,风险也会更复杂。
所以这篇论文真正值得记住的结论,不是“AI 已经能精准判断你是什么人”,而是: AI 助手正在把用户的长期对话变成一种人格传感器。
写在最后
人格推断风险不是 AI 创造出来的。传统互联网平台早就通过搜索、点击、浏览、社交和消费行为做用户画像。
但对话式 AI 改变了画像的入口和密度。用户不再只是被动留下行为痕迹,而是在与 AI 的互动中主动解释自己、描述自己、暴露自己。工作压力、关系困扰、健康焦虑、消费选择、学习计划、价值判断和情绪反应,会在长期对话中逐渐沉淀成一个可被建模的人格轮廓。
更值得警惕的是,AI 助手不只是记录这些信息。它会基于这些信息继续和用户对话,给出建议,塑造判断,影响行动。
这也是 AI 隐私问题和传统互联网画像问题最大的分水岭。
过去,平台在后台猜测你是谁。 现在,AI 可能在对话中表现得越来越懂你。
而越懂你,越需要边界。
同专题推荐
查看专题LASM:Agent 安全的七层攻击面
论文 LASM 提出七层攻击面模型与四类时间性分类,重构 Agent 安全的分析框架:从模型层、认知层、记忆层、工具执行层、多 Agent 协同层、供应链层到治理层,揭示 Agent 安全本质是分布式系统安全问题
AgentBound:给 MCP Server 套上权限边界
MCP 解决了 Agent 接入工具和资源的标准化问题,但安全机制没有同步跟上。 MCP 规范定义了 Host、Client、Server 之间的角色和消息交互,但在实际落地中,很多安全责任被交给应用开发者和宿主应用自行处理。 结果就是,MCP Server 往往以“默认可信”的方式运行。 这和移动…
当 Mythos 成为对手:高能力 AI 的安全边界正在失效
这两天,一篇题为 《When the Agent Is the Adversary》 的论文在安全圈引发了不小关注。它讨论的不是传统意义上的提示注入,也不是常见的越狱绕过,而是一个更让人不安的问题:当高能力 Agent 不再只是“被保护对象”,而开始成为“主动对手”时,我们今天熟悉的那些安全边界,还…