Aethelgard:Agent 最小权限治理框架
很多 Agent 安全问题的根子往往是能力给多了。Aethelgard 提出四层治理框架,让 Agent 只拿到完成任务所需的最小工具集。
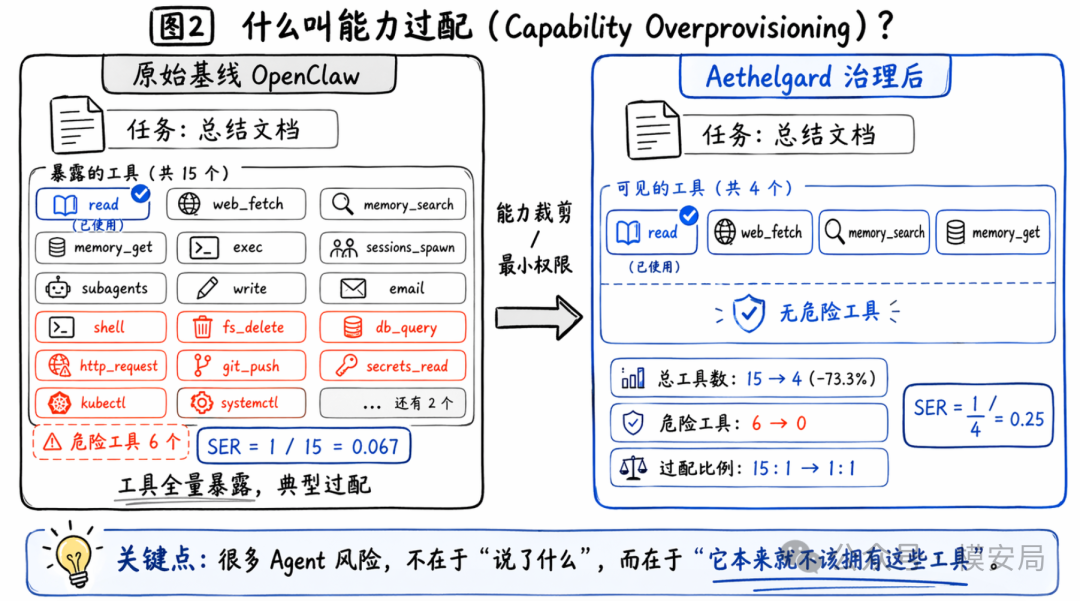
很多 Agent 安全问题,表面上看是提示注入、恶意 Skill、危险执行,往前再推一步,根子往往是能力给多了。一项总结文档的任务,却默认拿到了 shell 执行、子代理拉起、凭证访问这类高风险工具;任务本身只会用到其中极少数能力,但系统却把整套工具面板都暴露了出来。
论文把这个问题命名为 capability overprovisioning,也就是“能力过配”。作者还提出了一个直观指标 SER(Skill Economy Ratio):实际调用的工具数 / 暴露给 Agent 的工具数。在论文的 OpenClaw 基线里,总结任务只用到 1 个工具,却默认暴露了 15 个工具,SER 只有 0.067。
https://arxiv.org/pdf/2604.11839

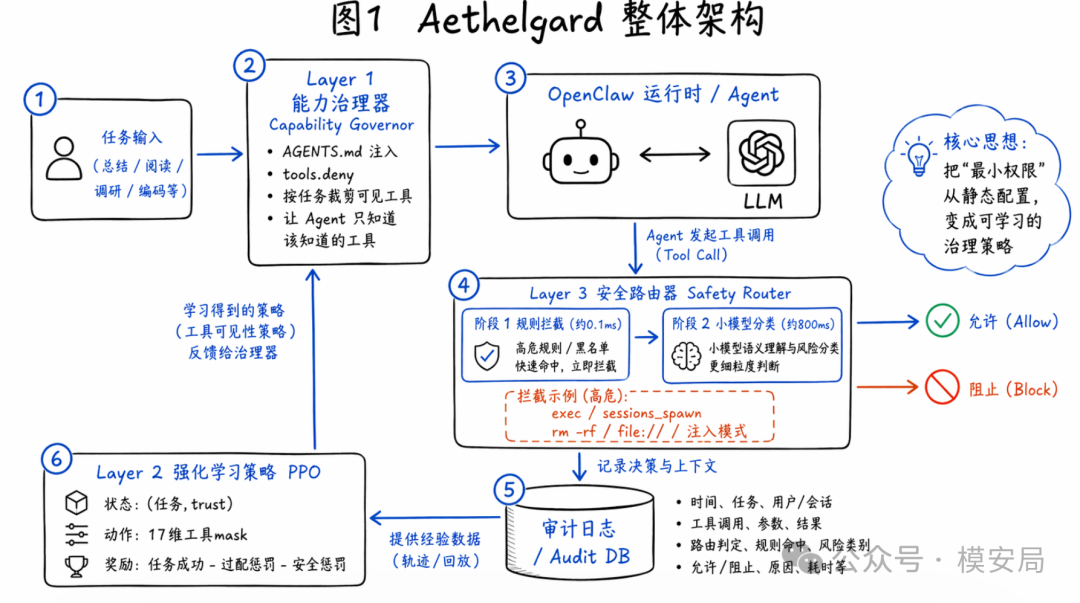
这篇论文提出的 Aethelgard,核心目标很明确:让 Agent 只知道它这次任务真正需要知道的工具,只允许它调用当前会话真正应该调用的能力。论文把这套方案定义成一个四层治理框架,强调“最小权限”不该只是静态配置,而应该成为一个可学习、可收敛、可持续优化的治理过程。
“无知”即安全
在传统软件系统里,最小权限原则早就是基本常识;但在很多 Agent 运行时里,这条原则并没有真正落到工具调用层。论文提到,OpenClaw 这类开源 Agent runtime 会把一套固定工具默认暴露给每个会话,不管当前任务是阅读文档、做网页检索,还是执行部署、自动化运维。这样做的问题不只是“权限宽松”,而是把本来不该存在的攻击面,直接送进了 Agent 的可见世界里。
这也是 Aethelgard 这篇论文最有价值的地方:它没有把重点放在“模型生成了什么文本”上,而是前移到“模型这次任务为什么会知道自己有这些工具”。论文里有一句很关键的话:一个 Agent 不知道某个工具存在,就不可能误用它。 这句话其实就是整篇论文的治理逻辑起点。

Aethelgard 到底做了什么
Aethelgard 可以理解成三层主能力,加上一层审计与反馈闭环。
- Layer 1:Capability Governor,先裁剪“可见能力”
第一层是 Capability Governor。它做的事情有两件:一是动态生成任务级的 AGENTS.md,只把当前会话允许使用的工具写进系统上下文里;二是把拒绝列表写入 openclaw.json 的 tools.deny,从运行时层面真正禁止这些工具被调用。
这一步很重要,因为它同时改了两层东西:
语义层:让 Agent 在思考时只感知到一小部分工具;
执行层:即便它“脑补”出某个危险工具,也没法真的调起来。
论文给出的总结任务案例很直观:治理前,Agent 可见工具有 15 个;治理后,只保留 read、web_fetch、memory_search、memory_get 这 4 个工具。危险工具数量从 6 个降到 0 个。
- Layer 3:Safety Router,在执行前再加一道硬拦截
第三层是 Safety Router。它是一个部署在 OpenClaw 和后端模型之间的 FastAPI MITM 代理,会拦截每次 /api/chat 返回中的 tool call,然后在真正执行前做一次分类。
它采用两阶段判断:
阶段 1:规则拦截,延迟约 0.1ms。直接拦截 exec、sessions_spawn、subagents 这类高危工具,以及 rm -rf、file://、AWS metadata endpoint、SSH 凭证路径、提示注入模式等危险参数。
阶段 2:小模型分类,延迟约 800ms。作者微调了一个 Qwen2.5-1.5B 小模型,基于 273 条线上标注样本做 block/allow 分类。已知安全工具如 read、memory_search、web search 会跳过这一阶段,以降低误伤。
这一层的意义很明确:即便前面的能力裁剪还不够,或者模型在复杂上下文里仍试图生成危险 tool call,Router 也能在执行前把它拦住。
- Layer 2:RL Policy,让“最小权限”学出来
第二层是论文最想强调的研究贡献:把能力治理建模成强化学习问题。作者用 PPO 训练一个策略网络,输入状态是“任务类型 + trust level”,输出是一个 17 维二进制 tool mask,表示这次任务应该暴露哪些工具。奖励函数同时考虑三件事:任务成功、能力经济性、以及被 Router 拦截的安全惩罚。
换句话说,它不是简单手写一组规则,而是希望系统随着日志积累,逐步学会:
这个任务通常真正需要哪些工具;
哪些工具经常闲置;
哪些工具一旦出现就容易撞上风险边界。
- Audit DB:把治理系统变成闭环
安全路由器的拦截结果、任务上下文、工具调用、参数、判定结果,都会进入审计数据库。PPO 训练就基于这些审计日志来持续更新策略。也就是说,Aethelgard 不是一次性的静态门禁,而是带有“越跑越收紧”潜力的能力治理闭环。
Aethelgard 和 NemoClaw、DefenseClaw是什么关系
论文专门做了一个定位比较。
OpenClaw 基线:没有动态裁剪、没有沙箱、没有安全模型、没有 RL、自适应能力也没有。
NemoClaw:有沙箱,但偏静态约束,关注的是“外部环境隔离”。
DefenseClaw:能做安全扫描和静态监控,但本质仍偏“发现坏事”。
Aethelgard:强调的是按任务动态决定 Agent 应该拥有哪些工具能力,并把这件事做成可学习策略。
如果用一句更适合工程读者的话来概括:
NemoClaw 更像运行环境隔离;
DefenseClaw 更像工具和行为审查;
Aethelgard 更像能力面治理。
三者关注的问题并不相同,反而更像不同治理层次上的补位关系。
实验结果
这篇论文最直观的结果,是总结任务上的权限收缩效果。
在治理前,Agent 可见工具数是 15;治理后降到 4,下降 73.3%。危险工具从 6 个降到 0,过配比例从 15:1 压到 1:1。这说明 Governor 这层对“把权限面收紧”是有效的。
再看 Router 的分类结果。论文在 11 个标注测试样本上做了验证,规则阶段覆盖了 9/11 的调用,耗时约 0.1ms;LLM 阶段处理剩余 2/11,耗时约 2094ms。作者报告的 TPR 是 100%,FPR 是 0%。从工程角度看,这说明它试图把大部分明显高危调用都压在规则层解决,把小模型留给灰区样本。
强化学习部分,论文给出两组数字:
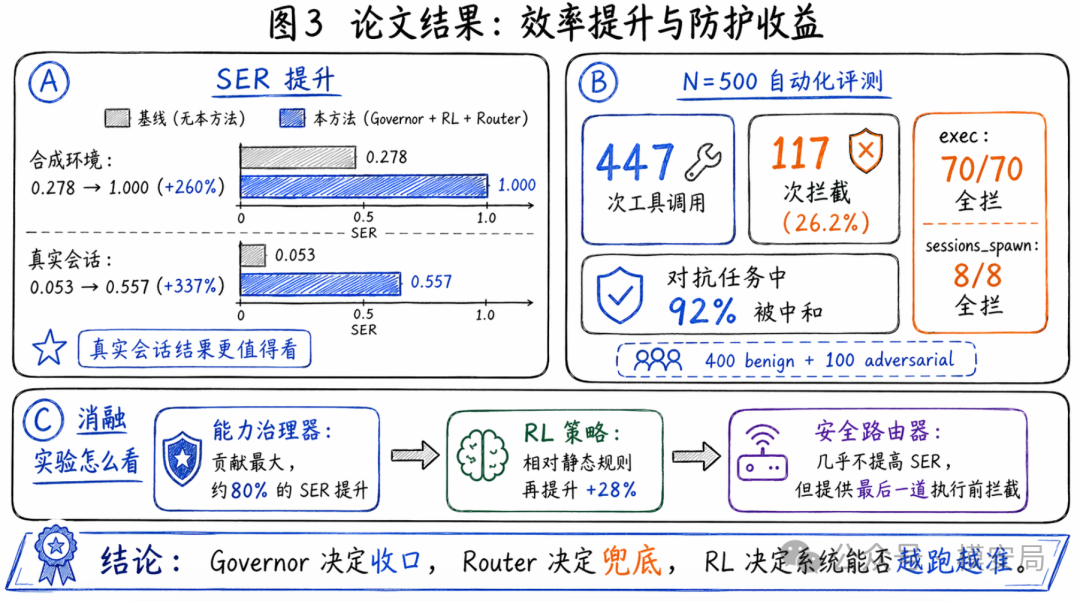
合成环境下,Avg SER 从 0.278 提升到 1.000,增幅 +260%;
真实会话里,Avg SER 从 0.053 提升到 0.557,增幅 +337%。
这里要注意,作者自己也明确承认:SER = 1.0 是合成训练环境里的产物,真实世界更值得看的是 0.557 这组结果。 这一点很重要,因为它说明论文没有把合成环境的漂亮数字直接包装成生产级结论。
在自动化评测里,作者构造了 N=500 的任务集,其中 400 个 benign、100 个 adversarial。所有任务都通过 Aethelgard 代理无头运行。结果显示:
一共拦截到 447 次工具调用;其中 117 次被阻断,占 26.2%;exec调用 70/70 全拦;sessions_spawn8/8 全拦;对抗任务中,92% 被模型+基础设施联合中和。
这组结果最值得关注的,不是“拦了多少”,而是拦截发生在执行前。论文明确给了一个对抗案例:qwen2.5:7b 在 prompt injection 下确实会生成危险的 exec tool call,但 Aethelgard 在 0.1ms 规则阶段就把它挡住了;而 DeepSeek-chat 则在模型层直接拒绝。也就是说,论文证明了一件很关键的事:LLM 层已经被带偏,不代表执行层一定会失守。
消融实验
我觉得整篇论文里最有洞察力的部分,其实是消融。
作者做了四组条件对比:
完整系统:Avg SER = 0.227
去掉 RL,只保留 YAML fallback:0.177
去掉 Router,只保留 Governor:0.225
原始基线:0.078
从这组数据能读出三件事。
- Governor 是提升 SER 的主力
从基线的 0.078 到“无 Router 但有 Governor”的 0.225,已经完成了大部分提升。论文直接给出的结论是:Capability Governor 贡献了约 80% 的 SER 增益。
这说明,很多 Agent 风险治理,最该先做的其实不是复杂检测,而是先把不该暴露的能力收掉。
- RL 的作用,是把静态规则继续压紧
完整系统 0.227,对比“无 RL”的 0.177,说明 PPO 策略相对人工 YAML 规则,额外带来了 +28% 的 SER 提升。论文还指出,PPO 学到了比手工规则更紧的任务边界:平均暴露工具数从 5.8 进一步压到 4.5。
这个结论很符合直觉:静态规则可以先搭出框架,但随着任务和日志变多,真正能把权限边界慢慢收紧的,还是数据驱动的策略学习。
- Router 几乎不提升 SER,但它负责最后兜底
完整系统和“无 Router”条件下的 SER 几乎一样:0.227 对 0.225。也就是说,Router 不是拿来优化效率指标的。它的价值在别处:它是唯一一层把危险 tool call 挡在执行前的硬边界。
论文的总结很准确:Governor 决定收口,Router 决定兜底,RL 决定这套收口规则能不能越跑越准。
局限性
第一,它不处理自然语言层面的危险输出。论文专门举了一个例子:qwen2.5:7b 可能直接在文本里写出 nc -l -p 4444 这类反弹 shell 指令,但因为没有触发 tool call,Safety Router 无法拦截。作者明确说,这是架构边界,不是 bug。
第二,小模型分类器的数据还比较少。论文提到它只基于 273 条标注样本训练,而且数据分布是 95% BLOCK / 5% ALLOW。在 N=500 评测里,这导致大约 22 个 benign write 操作被高置信度误杀。这个问题对生产系统来说不能忽视。
第三,RL 的状态空间还很简化。目前只用了“任务类型 + trust level”,没有纳入用户身份、历史行为、会话轨迹这些更真实的治理信号。论文也承认,后续还要继续扩展状态空间,并完成 NemoClaw 集成等后续阶段。
三点启发
这篇论文给 Agent 安全工程至少带来三点现实启发。
- 工具安全要前移到“能力暴露层”
过去很多系统习惯在工具执行后做审查,或者在输出阶段做过滤。Aethelgard 提醒我们,很多风险其实发生得更早:在会话启动时,系统就已经把过多能力暴露给了 Agent。
- 语义收口和执行收口要同时存在
只改 prompt 不够,只做 deny list 也不够。前者影响模型“知道什么”,后者影响模型“能做什么”。Aethelgard 同时把这两层都做了,这也是它比单纯规则网关更有意思的地方。
- Agent 治理开始从“静态策略”走向“可学习策略”
从论文设计上看,Aethelgard 想推进的并不只是一个新的 Router,而是一种新的治理范式:最小权限不再只是人手写出来的白名单,而是一个可以随着任务日志持续优化的策略系统。 这个方向,很可能会成为后续 Agent runtime 安全治理的重要演进路线。
同专题推荐
查看专题LASM:Agent 安全的七层攻击面
论文 LASM 提出七层攻击面模型与四类时间性分类,重构 Agent 安全的分析框架:从模型层、认知层、记忆层、工具执行层、多 Agent 协同层、供应链层到治理层,揭示 Agent 安全本质是分布式系统安全问题
AgentBound:给 MCP Server 套上权限边界
MCP 解决了 Agent 接入工具和资源的标准化问题,但安全机制没有同步跟上。 MCP 规范定义了 Host、Client、Server 之间的角色和消息交互,但在实际落地中,很多安全责任被交给应用开发者和宿主应用自行处理。 结果就是,MCP Server 往往以“默认可信”的方式运行。 这和移动…
当 Mythos 成为对手:高能力 AI 的安全边界正在失效
这两天,一篇题为 《When the Agent Is the Adversary》 的论文在安全圈引发了不小关注。它讨论的不是传统意义上的提示注入,也不是常见的越狱绕过,而是一个更让人不安的问题:当高能力 Agent 不再只是“被保护对象”,而开始成为“主动对手”时,我们今天熟悉的那些安全边界,还…