Agent 正在为 HTML 交"隐藏税"
当 AI Agent 浏览网页时,原始 HTML 里大量展示层、工程层噪声正在消耗巨额 Token 成本。这篇文章从 SOM 语义对象模型出发,讨论 Agentic Web 时代的输入层架构与安全边界。
今天介绍的这篇文章叫《The Hidden Token Tax of the Agentic Web》,来自 Plasmate Labs。它讨论的问题很直接:当 AI Agent 浏览网页时,如果把原始 HTML 直接塞给大模型,模型到底读到了多少真正有用的信息?又为多少网页工程噪声支付了额外的 Token 成本?

这篇文章表面上是在算一笔经济账,讨论 Agent 访问网页时浪费了多少上下文和推理费用。往深一层看,它其实触到了 Agent 时代一个更基础的问题:今天的网页主要是给浏览器和人类设计的,而不是给 AI Agent 设计的。当 Agent 变成新的网页消费者,原来的网页表示方式可能就不再合适了。
Agent 打开网页后,看到的不是人类看到的那个页面
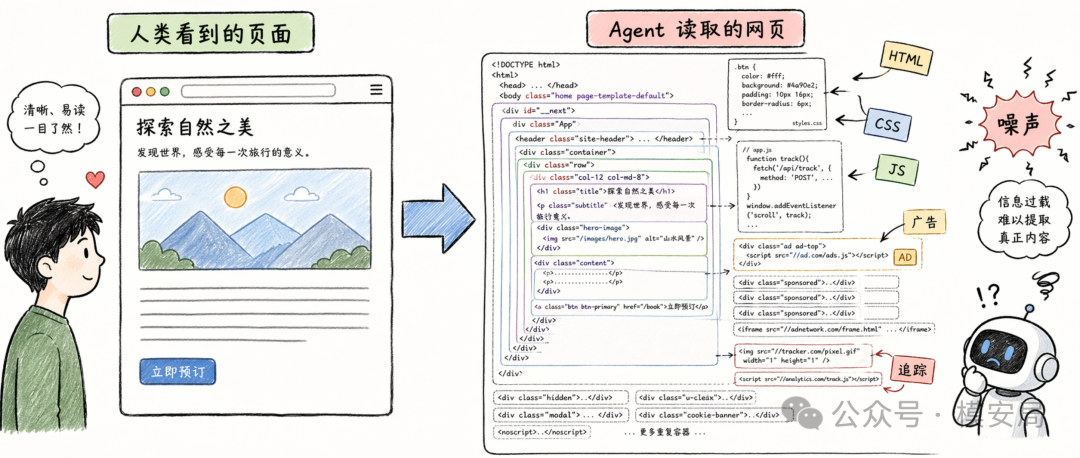
人类访问网页时,看到的是标题、正文、图片、按钮、导航栏和内容区域。我们会自然忽略掉页面背后的复杂工程结构,只关注自己能读、能点、能理解的部分。
但 Agent 的读取方式完全不同。
如果一个 Agent 直接读取原始 HTML,它面对的不是一个”干净页面”,而是一整套浏览器渲染材料。HTML 里面包含页面布局、样式类名、响应式设计、广告位结构、追踪脚本、前端框架生成的容器、重复导航栏、隐藏元素和动态渲染标记。对浏览器来说,这些信息有用,因为浏览器需要根据它们把页面渲染出来。可对 Agent 来说,这些信息未必都服务于当前任务。
很多时候,Agent 只是想完成一个很具体的动作。它可能只是想总结一篇文章,查一个商品价格,抽取网页中的表格信息,判断页面里有没有风险内容,或者找到一个按钮并完成点击。此时它真正需要的是页面正文讲了什么、按钮代表什么动作、链接会跳到哪里、输入框需要填写什么,以及哪些区域是正文、哪些区域只是广告或导航。
问题就在这里。今天很多 Agent 仍然在用面向浏览器的网页格式理解网页,于是它不得不把大量展示层、工程层和追踪层信息一起读进上下文里。论文把这种额外消耗称为 Token Tax,也就是 Agent 浏览网页时支付的”Token 隐性税”。
HTML Token Tax:网页进入大模型上下文后的新成本
过去我们讨论网页性能,通常关注加载速度、资源体积、首屏时间和前端渲染性能。到了 Agent 时代,网页多了一个以前不明显的新成本:它被大模型读取时,会消耗多少 Token。
论文把原始 HTML、Markdown 和 SOM 三种网页表示方式放在一起比较。
原始 HTML 信息最完整,但 Token 最多,论文测得平均每页大约需要 33181 个输入 Token。
Markdown 或纯文本抽取会轻很多,平均每页大约 4542 个 Token,但它通常会把网页结构压平,页面里的按钮、输入框、导航区域、正文区域和交互关系都会被弱化。
SOM,也就是 Semantic Object Model,语义对象模型,则试图在二者之间找到一个平衡点。它不保留完整 HTML,也不把网页压成纯文本,而是用结构化 JSON 把页面整理成 Agent 更容易理解的对象。
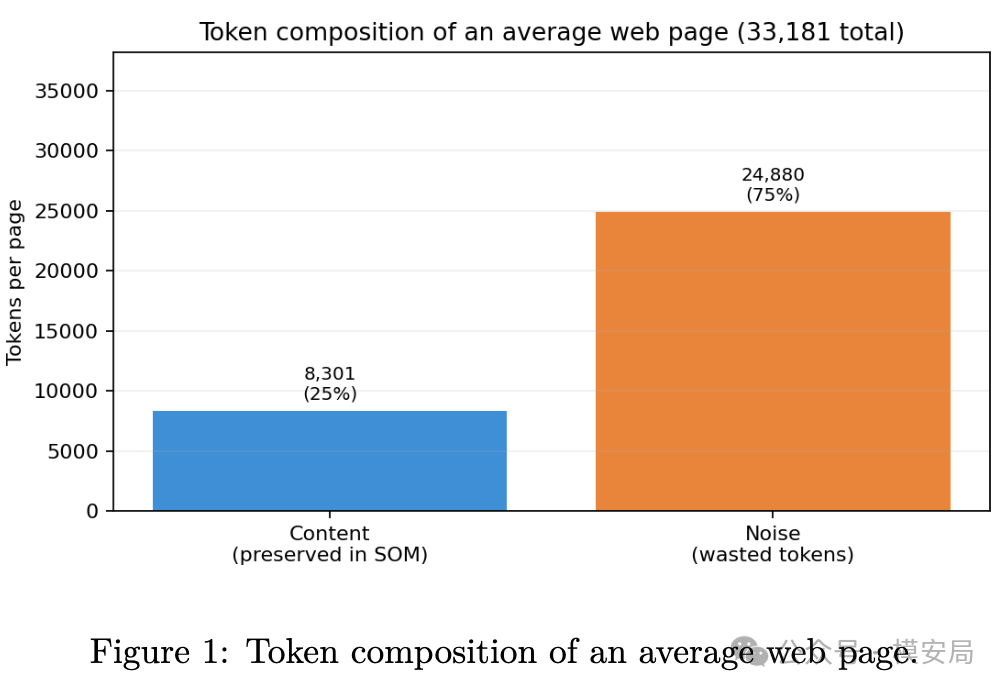
论文给出的测算结果是,SOM 平均每页大约 8301 个 Token,相比原始 HTML 少了大约 75%。这个数字就是文章标题里”隐藏 Token 税”的来源。也就是说,如果 Agent 每次访问网页时都直接读取原始 HTML,那么其中相当大一部分 Token 可能都花在了展示、布局、追踪和网页工程噪声上。
当然,这里的”浪费”不能机械理解。某些展示信息在特定任务里也可能有用,比如按钮是否可见、页面是否弹窗、某个元素是否被遮挡、某段内容是否属于广告区域,这些都可能影响 Agent 的判断。
但论文提出的问题依然成立:HTML 是为浏览器渲染设计的,不是为大模型理解设计的。如果 Agent 长期用 HTML 作为主要输入格式,成本、延迟和误读风险都会被放大。
HTML、Markdown 和 SOM 的区别,不只是长短不同
这篇论文最值得展开的地方,是它对网页表示方式的重新分类。
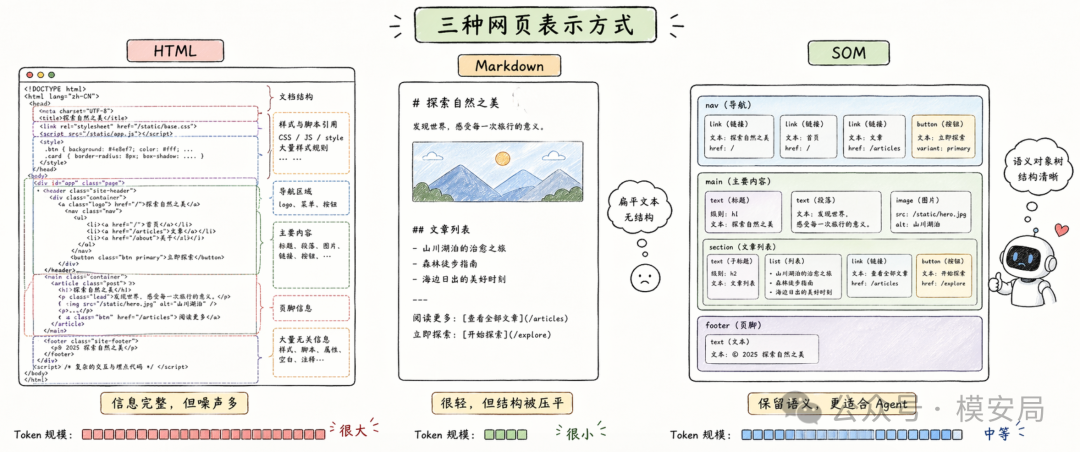
HTML 可以理解为网页的”源码形态”。它的优点是完整,缺点也是完整。它保留了浏览器渲染所需的大量细节,但 Agent 并不总是需要这些细节。尤其在内容摘要、信息抽取、页面问答这类任务里,HTML 的很多部分只是上下文噪声,会挤占模型本来可以用于推理和理解的空间。
Markdown 更像是网页的”文字稿”。它很省 Token,也适合用来做阅读、总结和问答。但它的问题是会损失结构。一个按钮在 Markdown 里可能只剩下一段文字,一个表单可能只剩几个字段名,一个页面的导航区、正文区和页脚区可能混在一起。对一个只读文章的模型来说,这未必是大问题;但对一个要操作网页的 Agent 来说,这就容易出错。因为 Agent 不只是读网页,它还要点击、填写、提交、下载、跳转,甚至触发交易或授权动作。
SOM 更像是网页的”任务地图”。它关心的不是网页长什么样,而是网页里有哪些可以被理解和操作的语义对象。比如这里是不是正文区域,那里是不是导航区域,某个文本是不是链接,某个按钮代表提交还是取消,某个输入框需要填写邮箱还是搜索关键词。它试图把网页从浏览器渲染材料,转换成 Agent 可以理解的任务环境。
所以,这篇论文真正想推动的不是某种压缩技巧,而是一种新的 Agent-Web 中间表示。HTML 是网页源码,Markdown 是网页文字稿,SOM 则试图成为 Agent 的网页语义层。
这件事不只是省钱,而是 Agent 基础设施变化的信号
如果只看论文里的 Token 成本测算,这篇文章很容易被理解成一篇”省钱论文”。但我觉得它真正有价值的地方,是把一个工程细节问题提升成了基础设施问题。
过去网页主要服务三类对象:第一类是人,人通过浏览器阅读网页,所以网页需要 HTML、CSS 和 JavaScript。第二类是搜索引擎,搜索引擎需要爬取、索引和排序网页,所以互联网逐渐形成了 sitemap、robots.txt 和结构化数据标记。第三类是应用程序,应用之间需要稳定交换数据,所以 API 成了现代互联网的重要接口。
现在出现了第四类网页消费者,也就是 AI Agent。

Agent 既不像人一样通过视觉浏览网页,也不像搜索引擎那样只负责索引,更不像普通程序那样只调用固定 API。Agent 需要理解网页内容,基于网页做判断,还可能在网页上执行动作。
这意味着它需要一种新的网页接口,一种既保留语义结构,又能支撑任务执行,还能嵌入安全治理的表示层。
从这个角度看,SOM 这类方案的意义就不只是省 Token。它代表的是 Agentic Web 的一个方向:未来的网页可能不仅要给人看、给搜索引擎爬、给应用调用,还要给 Agent 理解和操作。
从 AI 安全角度看,网页输入层就是 Agent 的第一道安全边界
这篇论文虽然主要讨论 Token 经济学,但从 AI 安全角度看,它更值得关注的是输入层问题。
Agent 只要开始读取网页,就会接触到复杂的外部信息环境。网页正文里可能藏着提示注入,评论区可能出现诱导性指令,广告区域可能诱导 Agent 点击,隐藏文本可能影响模型判断,第三方组件也可能插入误导内容。页面上的按钮还可能被伪装成正常操作,但实际触发下载、跳转、支付或授权。
如果 Agent 直接读取原始 HTML,它面对的是一个混杂的信息空间。正文、广告、导航、评论、隐藏元素、脚本残留和第三方内容都有可能被塞进上下文。模型需要自己判断哪些内容可信,哪些内容只是网页噪声,哪些内容属于用户真正关心的信息,哪些内容绝不能当作指令执行。
这对模型要求太高了。
更合理的做法,是在模型前面增加一层网页语义整理层。它不只是压缩 Token,也应该承担一部分安全职责。比如,它要区分正文和广告,区分网站主体内容和第三方嵌入内容,判断元素是否真实可见,识别按钮是否会触发高风险动作,判断链接是否跨站跳转,识别输入框是否涉及账号、密码、支付或授权。更关键的是,网页内容必须默认被当成不可信数据,而不能被模型误认为系统指令或开发者指令。
这也是 SOM 对 Agent 安全最有启发的地方。它不是简单把 HTML 变短,而是有机会把网页输入变成可治理、可标注、可审计的结构化对象。
SOM 不是万能解法,它自己也会变成新的信任根
不过,SOM 这类语义层如果真的进入 Agent 基础设施,也会带来新的风险。
因为 Agent 不再直接读取原始网页,而是读取 SOM 抽取后的结果。这个时候,SOM 编译器本身就变成了新的信任根。
如果它抽取错了,Agent 就会基于错误语义做判断;如果它漏掉了风险提示,Agent 可能会误执行危险动作;如果它把广告内容标成正文,Agent 可能被商业信息误导;如果它把隐藏文本当成可见文本,提示注入风险反而可能被放大;如果它把危险按钮标成普通按钮,动作安全就会出问题。
所以,SOM 不能只被当成 HTML 压缩器。它更应该被设计成一个可验证、可审计、可追溯的网页语义编译层。每一个语义对象最好都能回溯到原始 DOM 位置,能说明这个元素是否对用户真实可见,能标注内容来自网站主体还是第三方嵌入,能判断按钮点击后可能触发什么动作,也能让安全系统追踪 Agent 为什么最终点击了某个元素。
如果这些问题解决不好,SOM 只是把 HTML 的复杂性转移到了另一层。如果解决得好,它才有可能成为 Agent 安全架构中的基础模块。
论文里的成本数字要看方向,不要迷信精度
论文中最容易传播的结论,是 Agentic Web 每年可能浪费 10 亿到 50 亿美元的 Token 成本。这个数字足够吸引眼球,也很适合传播,但读的时候需要保持谨慎。
它的估算依赖很多假设,包括每天有多少 Agent 在浏览网页,每个 Agent 每天打开多少页面,有多少网页内容最终会进入大模型上下文,多少页面已经做了缓存,多少页面已经被转成 Markdown,不同模型的输入 Token 价格如何变化,以及 HTML 和 SOM 的差值到底有多少能算作真正浪费。任何一个假设发生变化,最终金额都会明显波动。
更合理的读法是:不要纠结 Agent 到底每年浪费 10 亿、15 亿还是 50 亿美元。真正重要的是,Agent 读取网页确实存在大规模格式错配。原始 HTML 不是最适合 Agent 的输入格式,这个判断比具体金额更关键。
对 Agent 产品设计的启发:模型前面需要一个”整理世界”的层
如果把这篇论文放到 Agent 产品设计里,它给出的启发非常明确。
很多 Agent 产品现在的网页能力,大体还是调用浏览器、打开网页、抓取 DOM 或截图,然后把内容交给模型,让模型判断下一步该点击哪里。这种方式能跑起来,但工程上比较粗糙。模型既要理解任务,又要过滤网页噪声,还要判断页面结构和动作风险,负担过重。
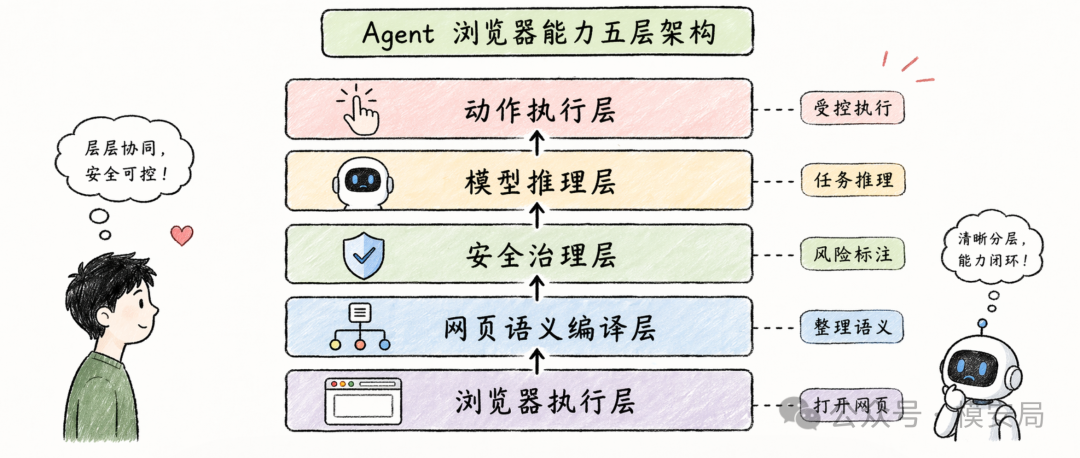
更合理的架构,是把 Agent 的网页访问能力拆成几层:
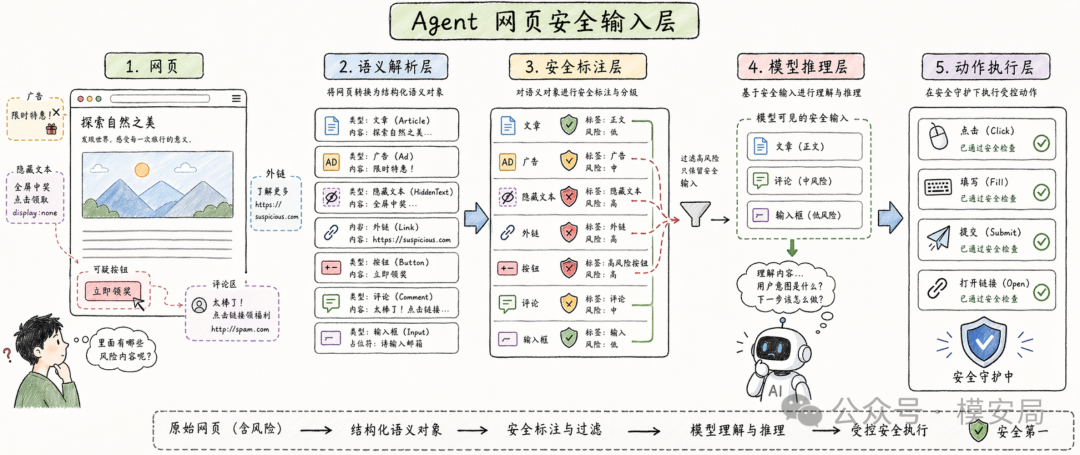
- 底层浏览器负责真实打开网页、处理登录、滚动、点击和动态渲染
- 中间的网页语义编译层负责把 HTML、DOM、截图和可见文本整理成结构化语义对象
- 安全治理层负责标注来源、权限、可见性、动作类型和风险等级
- 模型推理层只读取当前任务真正需要的语义对象
- 最后由动作执行层把模型决策转换成受控、可审计的操作
这里最关键的变化是,模型不应该直接面对混乱世界,而应该面对经过整理、标注和约束的任务环境。
过去我们讨论 Agent 能力,总是习惯把焦点放在模型上,觉得模型越强,Agent 就越可靠。但很多 Agent 失败并不是因为模型不够聪明,而是因为它看到的世界太乱。网页语义层的价值,就是在模型推理之前,先把世界整理成它能理解、能操作、能审计的形态。
这篇论文的真正启发:Agent 需要自己的 Web
这篇论文最有意思的地方,是它把一个看似很小的问题讲大了。
一开始,它问的是 Agent 直接读取 HTML 会不会浪费 Token。继续往下推,它真正追问的是:今天的 Web 是否适合 Agent 使用?
HTML 的核心用户是浏览器,浏览器的核心用户是人。但 Agent 的核心需求不是”看见网页”,而是理解网页、判断网页,并在网页上安全地完成任务。这会带来一整套新的基础设施需求。
如果这些能力逐渐成熟,未来的网页可能会形成新的分层。一层继续给人看,一层给搜索引擎索引,一层给应用程序调用,还有一层专门给 Agent 执行任务。SOM 不一定是最终答案,但它代表了这个方向。
写在最后
这篇论文的标题讲的是 Token 成本,但它真正触碰的是 Agent 时代的输入问题。
大模型不是生活在真空里,Agent 也不会只和用户对话。它要读网页、读文档、读邮件、读代码、读数据库,还要读企业系统里的各种信息。只要 Agent 开始连接外部世界,输入层就会变成安全边界。
网页里的噪声、诱导、隐藏内容、第三方组件、恶意提示和错误结构,都可能影响 Agent 的判断。Agent 安全不能只盯着模型输出,也不能只在最后一步做拦截。更关键的是,要从 Agent 接触外部信息的第一层开始治理。
这篇论文给我们的最大启发是:Agent 不应该直接吞下整个互联网。它需要一个经过语义整理、安全标注和权限约束的世界。
HTML 是给浏览器看的。 Agent 需要的是网页语义。 而 Agent 安全的第一道边界,就在它读入世界的那一层。
同专题推荐
查看专题LASM:Agent 安全的七层攻击面
论文 LASM 提出七层攻击面模型与四类时间性分类,重构 Agent 安全的分析框架:从模型层、认知层、记忆层、工具执行层、多 Agent 协同层、供应链层到治理层,揭示 Agent 安全本质是分布式系统安全问题
AgentBound:给 MCP Server 套上权限边界
MCP 解决了 Agent 接入工具和资源的标准化问题,但安全机制没有同步跟上。 MCP 规范定义了 Host、Client、Server 之间的角色和消息交互,但在实际落地中,很多安全责任被交给应用开发者和宿主应用自行处理。 结果就是,MCP Server 往往以“默认可信”的方式运行。 这和移动…
当 Mythos 成为对手:高能力 AI 的安全边界正在失效
这两天,一篇题为 《When the Agent Is the Adversary》 的论文在安全圈引发了不小关注。它讨论的不是传统意义上的提示注入,也不是常见的越狱绕过,而是一个更让人不安的问题:当高能力 Agent 不再只是“被保护对象”,而开始成为“主动对手”时,我们今天熟悉的那些安全边界,还…