智能体安全分类分级研究报告(模安局,2026.3)
从"它能做什么、能接触什么、能持续多久"出发,提出两层分类框架与0–100安全风险评分模型,覆盖内容创作型、检索问答型、编程执行型、自主工作台型等六类智能体形态,并给出 AISearch、Manus、Cursor、Claude Code、OpenClaw 示例评分与差异化治理建议。

智能体(agent)从安全视角看,关键不在”它能说什么”,而在**“它能做什么、能接触什么、能持续多久”**。经典人工智能教材将 agent 抽象为”在环境中感知并采取行动的实体”,风险根源因此天然与”环境可控性/可写性”绑定。近年的 LLM 智能体进一步把”推理(reasoning)+行动(acting)“耦合在同一条轨迹里,并通过工具调用与外部系统交互,从而把攻击面从”内容/对话”扩展到”工具/权限/执行链”。
本报告提出一套面向安全治理的分级体系:以**“两层分类逻辑”**为骨架——第一层按”环境影响/控制力”(从只输出到可执行/可改系统)划分;第二层按”自主性/运行时长”(从短程交互到长程自治/多会话记忆)细分。分类论证主要基于 OWASP 对 LLM 应用风险的归纳(如 Prompt Injection、敏感信息泄露、插件设计不安全、过度代理/过度自治等)以及英国国家网络安全中心将 Prompt Injection 视为”confused deputy/先天可混淆代理”问题的观点。
在此基础上,本报告设计了一个 0–100 的”安全风险评分模型”(分数越高风险越高),包含五个可量化子项:内容风险、数据风险、工具/权限风险、执行/代码风险、长期自主性风险,并给出权重、打分规则、分级阈值。
评分不仅用于”贴标签”,更用于驱动差异化控制:例如对可执行代码的编程智能体,应优先落地沙箱、最小权限、命令/网络策略、供应链治理与审计;对长程自治型,应额外要求任务边界、可中断性、关键动作强制人工确认与持续监控。
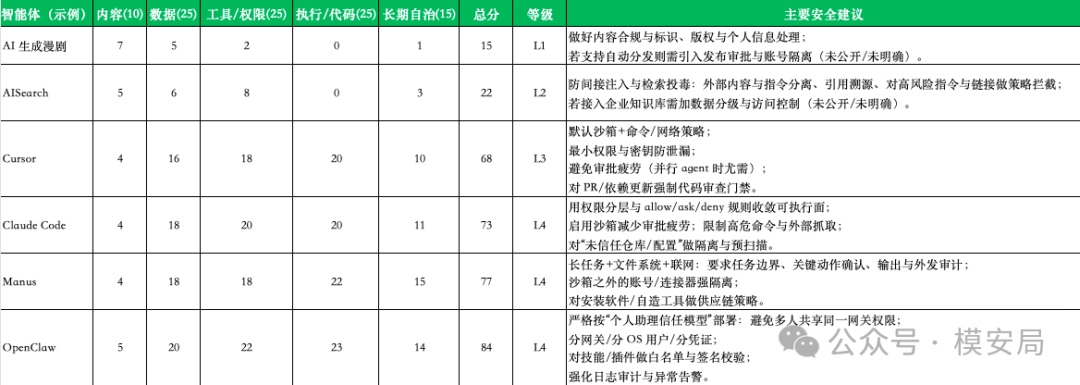
最后,报告对 6 个典型智能体形态(AISearch、AI 生成漫剧、Manus、Cursor、Claude Code、OpenClaw)给出基于公开信息的示例评分、等级与安全建议;若产品细节未公开/未明确,均标注并说明对评分的影响。
智能体定义与范围
从安全分级的角度,需要把”智能体”从一般聊天/生成系统中区分出来。一个可操作的定义是:
智能体 = 目标驱动(接收任务并规划步骤)+ 可行动(通过工具/接口对环境产生影响)+ 可累积状态(记忆/会话/文件)在一定程度上成立的系统。
该定义与经典 agent 模型中”在环境中感知并行动”的抽象相一致,只是现代 LLM 智能体把”行动”具体化为工具调用(检索、文件、Shell、API、插件等)。
本报告覆盖的”智能体”范围,按能力与风险面,包含以下典型形态:
- 搜索/检索型智能体(AISearch 类):以检索增强与总结为主,通常以只读方式访问网页/知识库并生成答案,主要风险集中在 Prompt Injection、RAG/检索投毒导致的错误引导与潜在数据外带。
- 内容创作型智能体(AI 生成漫剧类):主要输出文本/图像/音视频等内容,通常不直接操作外部系统。其合规与内容安全风险在中国监管语境下尤为关键(违法信息、深度合成标识、未成年人保护等)。
- 自主任务执行型通用智能体(Manus 类):官方文档将其描述为”自主通用 AI agent”,类比”有自己电脑的虚拟同事”,具备互联网访问、持久化文件系统、可安装软件与创建工具等能力。
- 编程/代码智能体(Cursor、Claude Code 类):面向代码库与开发工具链,典型能力包括读代码库、改文件、运行命令、与 git/CI 集成等。
- 多通道个人助理/网关型智能体平台(OpenClaw 类):定位为”自托管网关”,把 WhatsApp/Telegram/Discord/iMessage 等消息通道连接到”AI coding agents”,具备 sessions、memory、多 agent 路由、插件通道等能力。
分类分级框架
本报告采用”两层分类逻辑”,原因是:在智能体系统里,风险增量的主要来源通常不是”生成质量”,而是:
- 对环境的可写性/控制力(是否能把输出变为动作)
- 自主性/运行时长(是否能在更长时间里积累上下文、触发更多动作、被注入更多不可信输入)
该结构与 OWASP 强调的”过度代理/过度自治(Excessive Agency)""不安全插件设计""敏感信息披露”等风险项是一致的:当系统同时具备工具能力与较高自主性时,Prompt Injection 等输入操控更容易被”放大”为真实破坏。
六类可落地分类
| 类别 | 环境控制力 | 自主性 | 典型特征 | 代表形态 |
|---|---|---|---|---|
| 内容创作型 | E0 | S | 输出文本/图像/视频;无外部写入 | AI 生成漫剧 |
| 检索问答型 | E1 | S | 访问网页/知识库;理论只读;易受间接注入 | AISearch |
| 受控工具编排型 | E2 | S | 多步工作流;调用外部 API;关键动作可审批 | 轻量个人助理 |
| 编程执行型 | E3 | S | 读改代码库、运行 Shell、git 操作;需沙箱 | Cursor、Claude Code |
| 自主工作台型 | E3 | L | 自主规划长任务;虚拟机/沙箱;持久化文件系统 | Manus |
| 多通道网关与生态型 | E2/E3 | L | 多通道入口、sessions/memory、多 agent、插件生态 | OpenClaw |
安全评分模型
本报告给出一个”面向治理落地”的 0–100 风险评分:分数越高表示需要越强的隔离/审计/审批治理。
五维度与权重
- 内容风险(10%):输出类型与传播链路带来的合规/误导风险
- 数据风险(25%):智能体可接触的数据敏感度、持久化程度、跨系统聚合程度
- 工具/权限风险(25%):是否具备写入型工具、是否存在共享委托权限
- 执行/代码风险(25%):是否可执行命令/脚本、写文件、安装软件、触达 CI/CD 或生产资源
- 长期自主性风险(15%):是否长程运行、是否有记忆/会话树/计划任务/多 agent
风险等级阈值与治理强度
- L1(0–20):低风险,允许默认上线;以内容合规与基础日志为主
- L2(21–45):中风险,要求工具边界清晰、最小权限、输入输出审查与基础速率限制
- L3(46–70):高风险,要求沙箱/隔离、命令与网络策略、密钥治理、审计留痕、上线前红队测试
- L4(71–100):极高风险,要求强隔离、关键动作强制人工确认、多层检测与持续监控
典型智能体示例评分

以下打分基于公开信息与”典型部署假设”。若某产品在实际落地中具备额外能力(例如自动发布、直连生产、共享账号、多租户对抗场景),应上调对应分项。
- AISearch:内容风险低,但间接 Prompt Injection 与检索投毒是核心威胁,综合评估约 L2
- AI 生成漫剧:内容合规风险为主,若支持自动分发则上升,基础形态约 L1–L2
- Manus:自主工作台型,E3×L,持久化文件系统+可安装软件,约 L3–L4
- Cursor:编程执行型,Shell/文件/git 操作,审批疲劳问题突出,约 L3
- Claude Code:分层权限系统较完善,但执行面宽,约 L3
- OpenClaw:多通道网关,共享委托权限风险显著,E2/E3×L,约 L3–L4
缓解措施与治理建议
治理思路建议采用**“分级即分控”**:分类与评分输出的不是一个标签,而是一套强制控制清单与审计要求。
技术控制
重点应围绕”信任边界 + 最小权限 + 可执行面收敛”:
- 控制 LLM 访问后端系统的权限(单独 token、最小权限)
- 在特权动作加入人工环节
- 将外部内容与用户提示分离
- 在 LLM 与插件/下游系统之间建立信任边界并持续监控
- 对编程与可执行类 agent:默认沙箱/虚拟化隔离、网络 egress 白名单、文件系统 allowlist、命令 allow/deny 策略
流程控制
- 用沙箱边界减少审批频次,把审批资源集中在”跨出沙箱边界”的动作上
- 对批准动作做结构化记录(谁在何时批准了什么、在什么上下文下)
- 上线前完成威胁建模与红队测试
审计与监控
需要覆盖”模型输入—工具调用—环境副作用—数据流向”全链路,将以下纳入告警:
- 异常会话轨迹
- 异常工具序列
- 异常数据外发(目的地、体量、频率)
- 权限策略变更
局限性与未来方向
首先,这套分级体系是”以能力与部署边界为核心的风险刻画”,并不能替代针对具体业务的威胁建模与红队验证。
其次,Prompt Injection 及其衍生问题存在”结构性残余风险”。NCSC 直言应避免把 Prompt Injection 简化成可被单点修复的”类 SQL 注入”,更应将其视为”先天可混淆代理”的 confused deputy 类问题,工程上要做的是降低影响面、降低可用权限、提升可检测性——如果系统不能容忍残余风险,可能就不适合接入 LLM/agent。
第三,评分对”未公开/未明确信息”敏感:例如是否默认启用沙箱、连接器授权模型、日志留存策略、是否允许自定义插件/技能等,都会显著改变得分。这要求组织建立”证据优先”的评估机制:没有证据就按更坏假设评分。
未来改进方向:为工具与连接器建立”可验证身份与签名”,把策略引擎前置到每次工具调用前做实时评估,并为 agent 的行动轨迹提供更强的可解释与可复盘能力。
参考文献
- S. Russell and P. Norvig. Artificial Intelligence: A Modern Approach – Agents. Berkeley AI Materials, 2021.
- OWASP Foundation. OWASP Top 10 for Large Language Model Applications v1.1. 2024.
- UK National Cyber Security Centre. Guidelines for Secure AI System Development. NCSC, 2023.
- UK National Cyber Security Centre. Prompt Injection Is Not SQL Injection. NCSC Blog, 2024.
- Anthropic. Claude Code Sandboxing Architecture. 2024.
- Cursor Team. Agent Sandboxing in Cursor. Cursor Engineering Blog.
- OpenClaw Project. Threat Model Atlas for OpenClaw.
- Y. Li et al. Backdoored Retrievers for Prompt Injection Attacks on RAG. NDSS Symposium, 2026.
同专题推荐
查看专题AgentWard:高自主Agent全生命周期安全框架
AgentWard 提出面向自主 Agent 的五阶段生命周期安全架构,将初始化、输入、记忆、决策和执行分别纳入分层防护,并通过共享风险状态实现跨层联动。
TRACESAFE-BENCH:Agent执行过程的安全性评测框架
传统护栏盯住输入和输出两端,但 Agent 真正危险的地方在中间——每一次工具调用发出之前。TRACESAFE-BENCH 把 Agent 安全评测的重心推到了执行轨迹这一层。
GPT-5.5 System Card 深读:前沿模型安全,正在从拒答走向分层治理
从 GPT-5.5 System Card 出发,解析前沿模型从"回答问题"走向"执行任务"后,安全治理如何从内容审核升级为任务轨迹评估、工具调用管控与分层确认机制。