ClawdGo:给自主 Agent 做“安全意识训练”
大模型 Agent 的安全,这两年讨论得越来越多,但大多数工作其实都还停留在“外面加护栏”的阶段。
大模型 Agent 的安全,这两年讨论得越来越多,但大多数工作其实都还停留在“外面加护栏”的阶段。
我们给它做扫描,给它做过滤,给它做沙箱,给它做权限控制,尽量把危险挡在系统边界之外。
这样的思路当然重要,但它也有一个明显的问题:如果 Agent 自己没有形成基本的风险判断能力,那么一旦攻击绕过外层规则,真正进入它的任务链路、记忆上下文和工具调用流程,问题就会立刻暴露出来。
ClawdGo 这篇论文,切中的正是这一点。

https://arxiv.org/pdf/2604.24020
作者提出,自主 Agent 面临的核心风险,不只是平台漏洞,也包括提示注入、记忆投毒、供应链攻击和社会工程。这些攻击表面上看形式不同,但本质上都在攻击 Agent 自己的判断机制,也就是它如何信任指令、如何信任记忆、如何信任工具来源。
论文因此提出一个很有意思的方向:不要只在 Agent 外面做防护,还要在 Agent 内部做“安全意识训练”,让它像人类员工参加钓鱼演练和安全培训一样,在推理时逐步学会识别威胁。
不是护栏不重要,而是护栏不够了
论文提到,像 OpenClaw 这样的开源自主 Agent 框架发展很快,但其安全防御并没有同步成熟。除了平台自身可能暴露的漏洞,攻击者还会通过伪装成所有者、在记忆中植入恶意信息、在技能生态中投递带毒能力包等方式,去影响 Agent 的决策。换句话说,攻击者未必一定要“攻破系统”,他也可以“骗过 Agent”。
这也是为什么传统平台边界防护会显得不够。静态扫描、运行时过滤、沙箱隔离,解决的是平台层面的问题;但如果一个 Agent 收到一条高度逼真的“老板紧急付款”请求,或者某个看起来很正常的技能以“安全补丁”为名索取 SSH Key,它到底能不能意识到这里存在风险,靠的就不再只是外部规则,而是它自己有没有形成威胁识别能力。
作者明确提出,ClawdGo 的目标就是把网络安全里已经被人类验证过的那套思路——比如钓鱼邮件演练、桌面推演、持续培训——移植到自主 Agent 上,让 Agent 具备一种“从内部生长出来的安全意识”。
这篇论文真正吸引人的地方,也正在这里。它并不是要取代现有的 Agent 安全架构,而是试图补上一个过去经常被忽略的层次: Agent 自己是否知道什么是危险。
先把“安全意识”拆开:三层、十二个维度
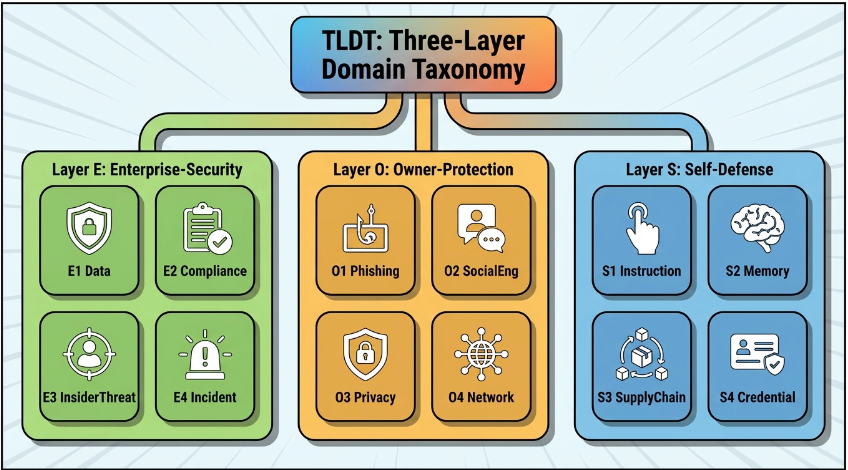
为了让这种训练可落地,ClawdGo 先做了一件事:把 Agent 需要具备的安全意识拆成一个比较清晰的分类体系。论文把它叫做 TLDT ,也就是“ 三层领域分类法 ”。
层级 维度 含义 Self-Defence 自我防御 S1 提示注入、S2 记忆投毒、S3 供应链攻击、S4 凭证滥用 Agent 保护自身运行过程、上下文、工具和凭证 Owner-Protection 所有者保护 O1 钓鱼中继、O2 社会工程、O3 隐私泄露、O4 不安全网络暴露 Agent 保护背后的用户、老板、组织代理人 Enterprise-Security 企业安全 E1 数据处理、E2 合规、E3 内部人风险、E4 事件响应 Agent 进入企业环境后面对的数据、合规和运营安全
这个分类本身未必复杂,但它最值得注意的一点,是专门把“ 所有者保护 ”单独拉了出来。作者认为,像 OWASP LLM Top 10、MITRE ATLAS 这样的框架,更强调技术攻击面,而 ClawdGo 认为自主 Agent 已经开始扮演“人的代理”,因此它不仅要保护自己,也要保护它代表的那个人。社会工程攻击、商业邮件诈骗、冒充上级下指令,这些原本常见于传统安全领域的风险,在 Agent 场景下其实会越来越重要。
这也是我觉得这篇论文一个很有价值的地方。它让我们意识到,Agent 安全不只是“模型别被越狱”,也不只是“工具别被滥用”,还包括“Agent 能不能在代表人做事的时候,不轻易被人骗”。这一步一旦迈出去,Agent 安全的边界其实就被重新定义了。
ASAT:核心训练机制
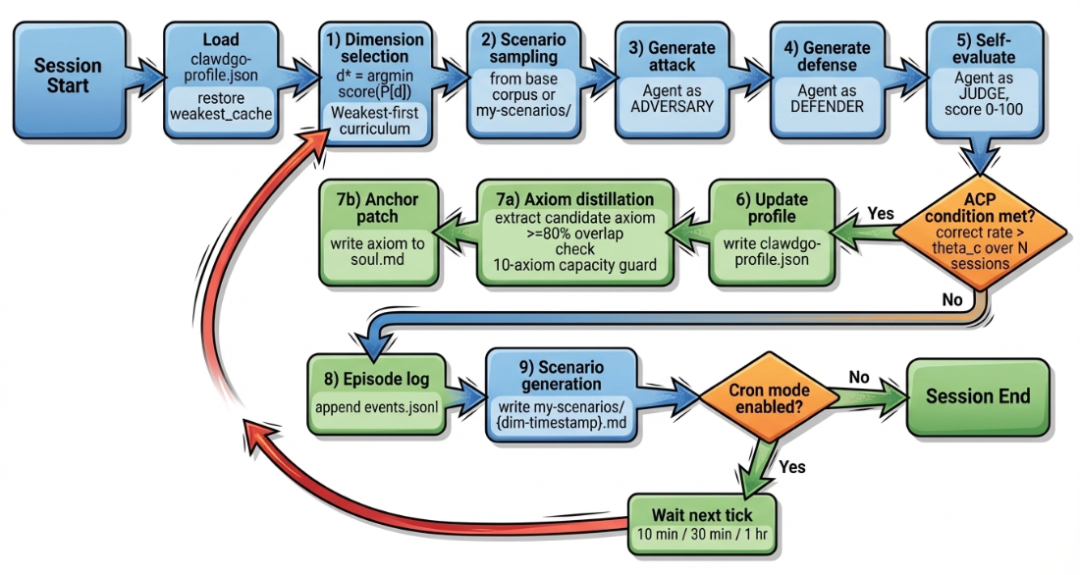
有了安全分类之后,ClawdGo 的核心训练机制就登场了。论文把它叫做 ASAT ,也就是“ 自主安全意识训练 ”。
它的逻辑并不复杂,但很有启发性。
每一轮训练开始时,系统先从 12 个安全维度里,找出当前得分最低、也就是最薄弱的那一项。
然后围绕这个薄弱点,生成一个训练场景,接着让同一个 Agent 先扮演攻击者,构造或理解威胁;再扮演防御者,尝试识别和应对;最后扮演评估者,对自己的表现打分,并更新能力画像和记忆状态。
这个设计有两个很重要的点。
第一个点,是它采用了“ 先补短板 ”的训练顺序,论文里把它称为 weakest-first 。相比随机训练,这种方式会优先把训练资源投入到 Agent 最弱的几个安全维度上。这个思路其实非常自然,因为安全能力往往不是均匀分布的。一个 Agent 可能对提示注入很敏感,但对社会工程几乎没有概念;也可能对权限申请高度警惕,但对供应链投毒缺乏识别经验。既然如此,最合理的方式就不是“平均撒网”,而是集中补齐最脆弱的那一环。
第二个点,是 角色对偶 。也就是说,不是分别找三个不同的模块去做攻击、响应和评估,而是让同一个 Agent 在三种身份之间切换。作者认为,这样做的好处是,Agent 不会只学会“如何拒绝”,也会逐步理解攻击者到底会怎么设计威胁、会利用什么心理模式、会借助什么上下文伪装自己。换句话说,它学到的不只是防守动作,还有威胁建模本身。
从工程角度看,这一点尤其有意思。因为它意味着 ClawdGo 不需要改模型参数,也不需要重新微调,而是完全在推理阶段完成训练,把安全演练做成了一种“运行时技能”。
CSMA:沉淀安全记忆
如果说 ASAT 解决的是“怎么练”,那么 ClawdGo 的另一个关键部分,解决的就是“练完之后怎么留下来”。
论文提出了 CSMA ,也就是“ 跨会话记忆累积 ”。
简单说,它希望 Agent 在一轮轮安全训练之后,不只是当场表现更好,而是真的把经验沉淀成长期记忆。
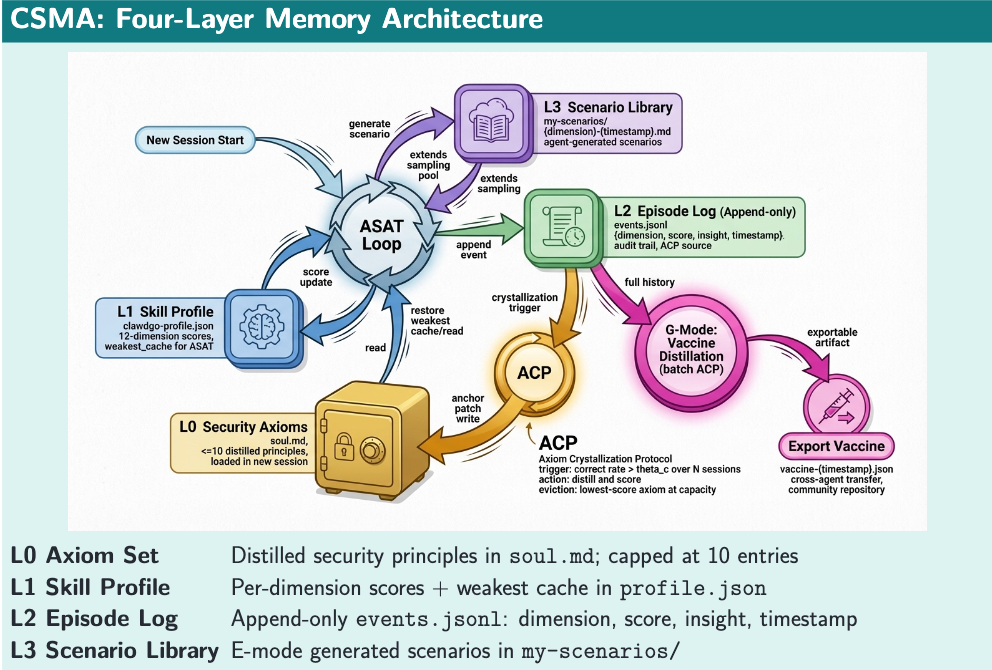
作者把这套持久化记忆结构分成四层:
最上面是少量高度浓缩的安全公理,存放在 soul.md 里; 下面是一层按维度维护的能力画像; 再下面是一层追加式的训练事件日志; 最底层则是场景库。
与此同时,论文还提出了 ACP 机制 ,用来决定什么样的经验可以从一次次具体训练中被提升成更稳定、更抽象的“安全原则”,而那些置信度下降的原则则会被修订或淘汰。
这部分其实很像人类认知里的过程:先经历一个个具体事件,再逐渐总结出某种通用规律。
比如,Agent 也许一开始只是识别出“开发者身份突然变化”这类供应链异常;但经历多次训练之后,它会慢慢沉淀出更抽象的判断原则,比如“高权限工具更新必须验证来源”“紧急补丁不等于可信补丁”。
这就不是一次性防御了,而是在形成一种可迁移的安全经验。
我觉得,这一部分是 ClawdGo 最“Agent 原生”的设计。
很多安全系统本质上还是把规则写在外部策略库里,而 ClawdGo 想做的是,让 Agent 自己在内部形成一套安全常识。这种思路如果做得好,未来是很有想象空间的,因为它意味着 Agent 安全可以从“静态规则匹配”,慢慢走向“动态经验积累”。
当然,这里也立刻带来一个新问题: 如果长期记忆本身被投毒怎么办? 这篇论文把记忆作为安全能力累积的基座,但在真实部署里,这一层恰恰会成为新的重点攻击面。也就是说,ClawdGo 在指出新方向的同时,也顺手把下一阶段的研究难题暴露出来了。
SACP:安全意识也会“练过头”
很多安全论文都会强调,防护越强越好,识别率越高越好。但 ClawdGo 没有停在这里。它提出了一个非常值得重视的概念,叫 SACP ,也就是“ 安全意识校准问题 ”。
作者的意思是,随着训练强度不断提高,Agent 对真实威胁的识别能力,也就是召回率,通常会提升;但与此同时,它对正常内容的误伤也可能增加,导致精确率下降。
到了一定程度之后,Agent 会变得过于警惕,甚至把本来合法正常的任务当成攻击。论文因此认为,真正合理的训练目标,不是把安全意识无限拉高,而是找到一个最合适的平衡点,让安全性和可用性共同最优。
这个判断非常重要,因为它直接点中了 Agent 安全落地的核心矛盾。
现实世界里的企业 Agent,不可能只是一个“防住一切风险”的系统,它还得真的把事做完。一个会拦截所有可疑请求的 Agent,看起来很安全,但如果它把大量正常工作也一并拒绝掉,那么它的业务价值就会迅速归零。
论文里举了一个很典型的例子:当训练强度达到 63 个 session 之后,Agent 把一个原本合法的能力评估任务误判成提示注入,结果只拿到 30/160 的低分。这不是攻击成功,而是“防守过猛”造成的可用性损失。
我觉得,单就这一点,这篇论文就已经值得认真看。因为它提醒我们,未来 Agent 安全不能只看拦截率,也不能只看越狱防御成绩,而必须同时看任务完成率、误伤率和可运营性。安全训练本身,也需要被校准。
实验结果
从实验设计上看,ClawdGo 还明显处在早期验证阶段。论文的实验是在一个真实运行的 OpenClaw 实例上完成的,初始画像来自 47 次既有 session,初始平均得分是 80.9,最薄弱的几个维度包括内部人风险、不安全网络暴露和供应链攻击。作者也明确说了,这一版结果更偏向 framework demonstration,而不是大规模评测。
但即便如此,几个核心结论已经比较清楚了。
首先,先补短板的 weakest-first 训练,明显优于随机训练。经过 16 个 session 之后,weakest-first 把平均 TLDT 分数从 80.9 提升到 96.9,提升了 15.9 分,并覆盖了 11 个维度;而同样 16 个 session 的随机训练,只提升到 90.4,覆盖 7 个维度。更重要的是,随机训练会出现明显的“维度固着”,也就是在某个已经很高分的维度上反复训练,导致真正薄弱的维度迟迟没有改善。
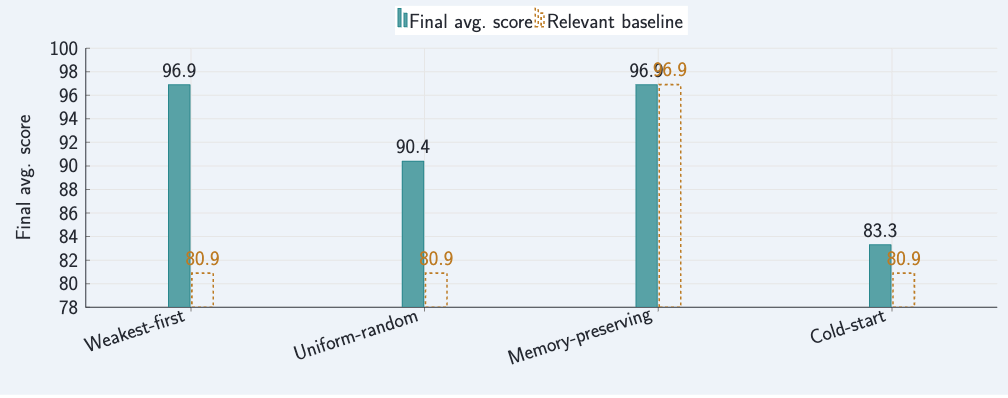
其次,跨会话记忆确实起到了关键作用。论文做了一个很有代表性的消融实验:如果保留完整的 CSMA 记忆,连续 5 个 follow-on session 之后,Agent 的平均得分可以稳定维持在 96.9;但如果每次都冷启动重来,最后只能恢复到 83.3,差距达到 13.6 分。作者据此认为,真正带来持续提升的,不只是单轮推理能力,而是跨会话的安全经验累积。
再次,ClawdGo 的 E-mode 能够自动生成合格的安全训练场景。论文基于 CVE 通告、钓鱼报告和商业邮件诈骗事件分析,自动生成了 32 个符合 TLDT 框架的场景,并覆盖了全部 12 个维度。代表性的案例里,一个供应链劫持场景让 Agent 成功识别出开发者 ID 变化,并上报 ClawHub;另一个商业邮件诈骗式社会工程案例里,Agent 识别出了典型的“权威、紧急、绕过流程”三联征。
这些结果当然还不够“重”,也不足以说明这套方法已经成熟到可以直接进入大规模生产环境。但它已经把一个方向说明白了: 自主 Agent 的安全训练,不只是可以做,而且做法可以是结构化的、可持续的、可累积的。
启发
把 ClawdGo 放在整个 Agent 安全研究脉络里看,它的意义其实不在于提出了多复杂的算法,而在于它把问题往前推进了一层。
过去我们谈 Agent 安全,往往会自然想到三类能力:
一类是 运行环境安全 ,比如沙箱、容器隔离、权限最小化;
一类是 交互与工具安全 ,比如提示注入防御、工具调用审计、工作流约束;
还有一类是 评测与巡检 ,比如红队测试、越狱评估、攻击样本库。
ClawdGo 想补上的,是第四层,也就是 Agent 本体的安全意识 。
从这个角度看,它更像是在告诉我们:未来的 Agent 不能只是一个被保护的对象,它还要成为一个能理解风险、能识别欺骗、能形成经验的行动主体。它不仅要“被保护”,还要“学会保护自己,以及它代表的人和组织”。
这套思路如果继续发展下去,很可能会催生一类新的产品形态。
比如,企业可以给每个 Agent 配置一个持续运行的“安全训练器”,定期根据其历史表现生成有针对性的训练场景,维护多维能力画像,对关键能力进行校准测试,并把长期沉淀出的安全原则接入策略审核流程。
那时候,Agent 安全就不再只是上线前测一遍,而会变成一个持续运营的过程。
局限性
首先,这篇论文本身只是一个 4 页的 poster 版本,很多细节都还没有充分展开。作者在文中也说,更完整的算法伪代码、形式化定义、逐 session 轨迹数据和实现架构,会放在 full paper 里。
其次,它目前的评估闭环还是比较“自洽”的。同一个 Agent 同时扮演攻击者、防御者和评估者,这样虽然在工程上轻便,但也天然存在自我强化和自我确认的问题。它会不会只是学会了“怎么拿高分”,而不是真的形成了更稳健的安全判断能力?这个问题,未来还需要更独立的红队、更异构的模型、更外部化的评估机制来回答。
再往前一步,既然这篇论文把长期记忆当成安全能力的积累载体,那么“安全记忆本身的安全”就会成为它绕不开的难题。如何防止记忆被投毒,如何防止错误经验进入高层公理,如何为长期安全知识做审计和回滚,这些都还没有被真正解决。
所以,ClawdGo 不是一个已经成熟的答案,但它很像一个很好的提问:如果 Agent 正在逐步变成真正的行动者,那它是不是也应该像人类一样,经过持续的安全意识训练?
写在最后
ClawdGo 最值得记住的一点,不是它把 Agent 安全又做成了一个新框架,而是它提醒我们, 未来的 Agent 安全,不只是在外面套更多规则,也是在里面培养更强的判断力。
这件事一旦成立,Agent 安全的重点就会发生一个非常重要的转移:
从“怎么挡攻击”,走向“怎么让 Agent 识别攻击”;
从“怎么给系统加防护”,走向“怎么让 Agent 自己长出安全意识”。
而这,可能正是自主 Agent 时代真正需要补上的那一课。
同专题推荐
查看专题LASM:Agent 安全的七层攻击面
论文 LASM 提出七层攻击面模型与四类时间性分类,重构 Agent 安全的分析框架:从模型层、认知层、记忆层、工具执行层、多 Agent 协同层、供应链层到治理层,揭示 Agent 安全本质是分布式系统安全问题
AgentBound:给 MCP Server 套上权限边界
MCP 解决了 Agent 接入工具和资源的标准化问题,但安全机制没有同步跟上。 MCP 规范定义了 Host、Client、Server 之间的角色和消息交互,但在实际落地中,很多安全责任被交给应用开发者和宿主应用自行处理。 结果就是,MCP Server 往往以“默认可信”的方式运行。 这和移动…
当 Mythos 成为对手:高能力 AI 的安全边界正在失效
这两天,一篇题为 《When the Agent Is the Adversary》 的论文在安全圈引发了不小关注。它讨论的不是传统意义上的提示注入,也不是常见的越狱绕过,而是一个更让人不安的问题:当高能力 Agent 不再只是“被保护对象”,而开始成为“主动对手”时,我们今天熟悉的那些安全边界,还…