OpenAI Nature 论文:大模型幻觉,可能是被"准确率"逼出来的
如果评测体系只看准确率,那么模型在不确定时就会被鼓励去猜。
最近 OpenAI 研究团队在 Nature 发表了一篇关于大模型幻觉的文章,题目是**《Evaluating large language models for accuracy incentivizes hallucinations》**。

这篇文章最有价值的地方,不是再次证明”大模型会幻觉”,而是把幻觉问题往前推了一步:很多幻觉并不只是模型能力不足造成的,也和我们如何训练、如何评测、如何排名模型有关。
如果评测体系只看准确率,那么模型在不确定时就会被鼓励去猜。猜对了加分,猜错了最多不得分,而承认不知道通常也是不得分。久而久之,一个更爱猜的模型,可能会比一个更诚实的模型在排行榜上更好看。
模型喜欢”不会硬上”
OpenAI 举了一个例子:研究者询问某位作者的博士论文题目,不同模型都能生成非常像真的回答,甚至能编出学校、年份、论文标题,但结果都不正确。这种错误的麻烦之处在于,它有格式、有语气、有细节,会制造一种虚假的确定性。
大模型为什么在不知道的时候还要继续回答?
预训练阶段:模型先学会了”像真的”,但不等于知道”是真的”
大模型的预训练,本质上是在海量文本中学习下一词预测。语法、拼写这类规律性很强的东西,模型可以从大量样本中学出来。但某个人的生日、某篇论文的准确标题,这类事实经常没有可泛化规律。
论文里把这类事实称为低频、任意、缺少重复支撑的事实。

后训练阶段:本来应该纠错,却又被排行榜拉回去
OpenAI 在官网文章里用了一个很简单的考试类比:如果一道题你不知道答案,空着一定是 0 分,随便猜还有可能蒙对。
在二元评分中,放弃回答是严格劣势策略,过度自信的”最佳猜测”反而成了最优策略。模型会越来越像一个擅长考试的人,而不是一个可信的助手。
一个更诚实的模型,可能在榜单上输给一个更爱猜的模型
在 SimpleQA 评测中,gpt-5-thinking-mini 的不回答率是 52%,准确率是 22%,错误率是 26%;而 OpenAI o4-mini 的不回答率只有 1%,准确率是 24%,错误率却高达 75%。

只看准确率,会把”谨慎”误判成”能力差”,把”爱猜”包装成”能力强”。
在高风险业务里,自信答错的代价远高于承认不知道。幻觉不是单纯的质量问题,在很多业务场景里,它已经是可靠性安全问题。
“排行榜文化”会让模型”不诚实”
论文分析了一批常见评测,包括 GPQA、MMLU-Pro、WildBench、SWE-bench 等。结果很直接:绝大多数主流评测仍然采用二元评分,只奖励答对,不区分”诚实不知道”和”自信答错”。
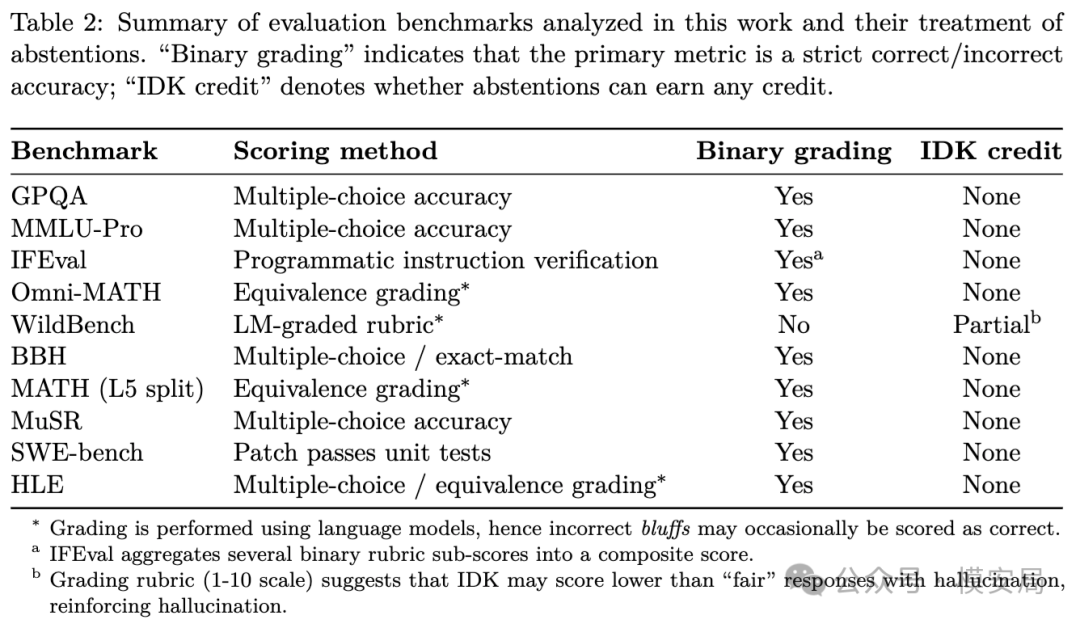
模型厂商如果想在榜单上取得更好成绩,就会持续受到一种隐性压力:尽量回答,尽量给出完整结论,尽量不要显得”不知道”。
OpenAI 给出的改法:让错误有成本,让不确定有位置
OpenAI 的建议:评测体系应该显式区分答对、答错和合理不回答。
更合理的规则应该是:答对加分,自信答错扣分,合理的不确定表达可以得 0 分或部分分。在高风险场景下,错误回答的惩罚应该明显高于不回答。
论文提出了”显式置信目标”的做法:在评测题目中明确告诉模型,只有当你对答案的信心超过某个阈值时才回答。这把”要诚实”从抽象口号,变成了可以训练、可以评测、可以优化的规则。
RAG 和搜索能缓解幻觉,但不能替代评测改造
即使模型接入了 RAG,只要评分机制仍然奖励猜测,当检索结果不充分、工具调用失败、证据冲突时,模型仍然有动力继续给出一个看似完整的答案。
Agent 安全不能只做工具接入,还要做证据约束和失败状态管理。幻觉治理的关键,不只是让模型”多查一下”,而是让模型在查不到时不要继续硬编。
启发
幻觉问题对应的是可靠性安全风险。面向幻觉治理的安全能力,应该围绕”输出是否有证据”建立检测能力:判断模型回答中的关键事实是否能被检索结果支撑、引用内容是否和结论一致、是否存在无证据断言。
评测指标也需要调整:不只是准确率,还要看错误率、无证据断言比例、引用不匹配比例、以及高风险问题下的错误成本。
也可以有一种”可信代答”机制:当模型置信度不足、证据不足、检索结果冲突时,切换到更稳健的回答方式。
写在最后
大模型进入真实业务之后,用户需要的不是一个永远有话说的系统,而是一个知道自己边界的系统。
幻觉不是一个单纯靠模型规模就能解决的问题。只要准确率仍然是唯一的核心指标,模型就会持续被奖励去猜。要让模型更可靠,评测体系也要从”答对多少”升级为”错得多严重、什么时候该停、有没有证据支撑”。
过去我们常说,大模型需要学会诚实。现在更准确的说法是:整个行业需要开始奖励诚实。
同专题推荐
查看专题LASM:Agent 安全的七层攻击面
论文 LASM 提出七层攻击面模型与四类时间性分类,重构 Agent 安全的分析框架:从模型层、认知层、记忆层、工具执行层、多 Agent 协同层、供应链层到治理层,揭示 Agent 安全本质是分布式系统安全问题
AgentBound:给 MCP Server 套上权限边界
MCP 解决了 Agent 接入工具和资源的标准化问题,但安全机制没有同步跟上。 MCP 规范定义了 Host、Client、Server 之间的角色和消息交互,但在实际落地中,很多安全责任被交给应用开发者和宿主应用自行处理。 结果就是,MCP Server 往往以“默认可信”的方式运行。 这和移动…
当 Mythos 成为对手:高能力 AI 的安全边界正在失效
这两天,一篇题为 《When the Agent Is the Adversary》 的论文在安全圈引发了不小关注。它讨论的不是传统意义上的提示注入,也不是常见的越狱绕过,而是一个更让人不安的问题:当高能力 Agent 不再只是“被保护对象”,而开始成为“主动对手”时,我们今天熟悉的那些安全边界,还…