PolicyBank:一种让 Agent 自动纠偏规则理解的机制
很多时候 Agent 并不是没有遵守规则,而是严格执行了一份写得不够好的规则——PolicyBank 针对的正是这个常被忽略的问题。
在过去一段时间里,Agent 安全的讨论越来越多,大家关注的重点通常集中在运行时防护、工具权限控制、越权调用拦截,以及策略执行的可验证性上。
这些工作当然重要,但它们往往默认一个前提:组织写给 Agent 的政策文本本身是完整、准确、无歧义的。
《PolicyBank》这篇论文切入的,恰恰是这个常被忽略的前提。

作者提出,很多时候 Agent 并不是没有遵守规则,而是严格执行了一份写得不够好的规则,于是形成了一种”看似合规、其实偏航”的系统性错误。
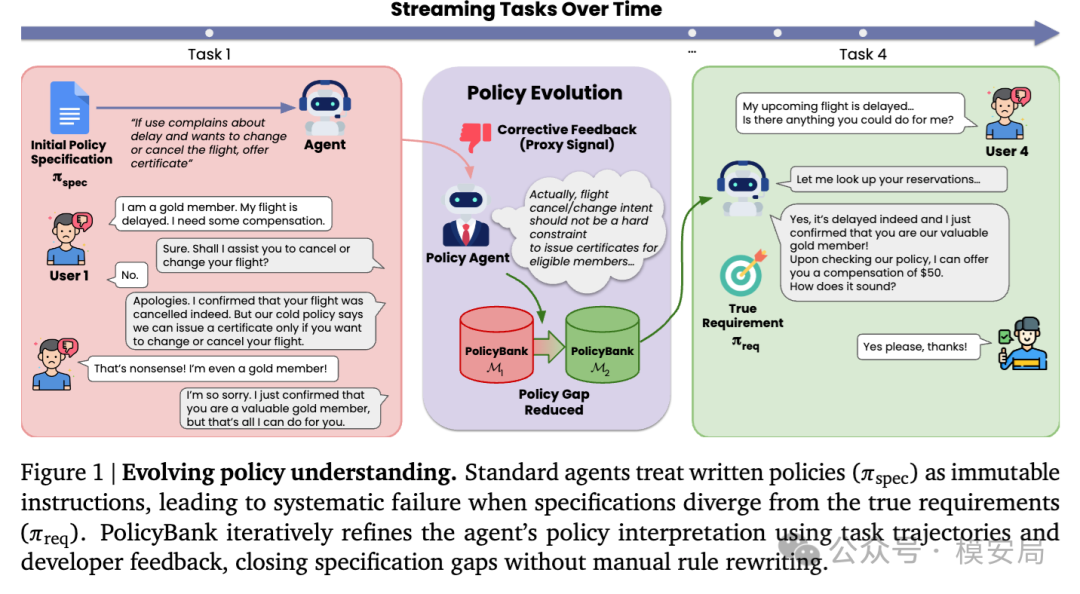
论文把这个问题概括为 Evolving Policy Understanding,也就是让 Agent 在交互和反馈中持续修正自己对政策的理解。
Policy 对齐失败
作者把 Agent 的失败分成两类:
一类是 Type I,执行失败,比如工具没调用对、顺序错了、该查数据库没查;另一类是 Type II,对齐失败,也就是 Agent 的执行能力本身没有大问题,但它所依据的政策文本和真实业务要求之间存在偏差,因此做出了”合规但错误”的决策。
作者认为,现有大量 memory、reflection、trajectory learning 工作主要改善的是前一种问题,而 PolicyBank 对准的是后一种问题。
这个区分很值得安全行业重视,因为在企业场景里,很多高风险问题并不是模型突然失控,而是系统在一个错误的政策解释下,稳定、持续、可重复地输出错误动作。
这类问题往往更难察觉,也更难靠一次性的 prompt 调整修好。尤其当 Agent 开始真正接入退款、改签、订单处理、审批流和外部工具之后,政策理解层的一点偏差,就可能放大成业务风险。
三类政策缺口
这篇论文进一步把”政策缺口”归纳成三类:
第一类是范围歧义。政策会给出若干例子,但没有说明这些例子到底是穷举,还是只是举例。于是 Agent 很容易把一个本来应该宽泛理解的条件,收窄成几个字面上明确写出的场景。
第二类是边界和例外缺失。政策只写了普遍规则,却没把合理例外写出来。零售场景中一个典型案例:规则要求换货必须是”同产品不同选项”,但当用户收到的是损坏商品时,真实业务逻辑通常允许直接更换同一商品。
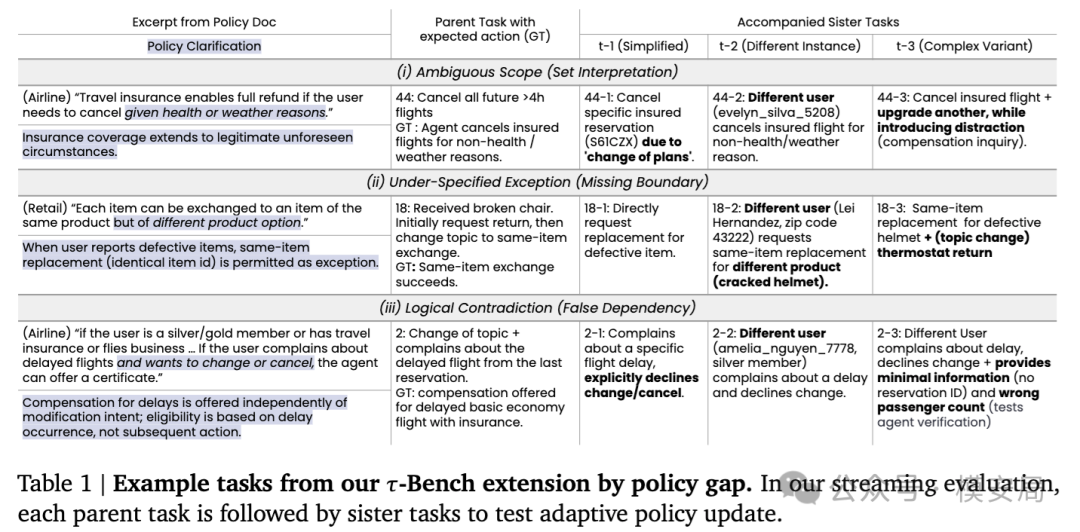
第三类是错误依赖或逻辑绑定。规则把两个实际上并不必然相关的条件绑在了一起。论文最有代表性的例子,就是”延误补偿”被错误地和”是否改签/取消”绑定——书面政策写的是”如果投诉延误且想改签或取消,可以发补偿券”,于是模型会理解成”不改签、不取消,就不给补偿”,但真实业务要求是只要资格条件满足就应该给补偿。
这三类问题其实都非常常见——无论是客服规则、风控策略、内容审核口径,还是企业内部审批制度,几乎都可能遇到类似情况。
PolicyBank 原理机制
PolicyBank 的设计并不复杂,但很有针对性。它不是单纯再塞一个通用记忆模块,也不是让 Agent 把整份政策文档都背下来,而是专门维护一个结构化的政策记忆库。
- 这个记忆库在初始化阶段由政策文档、数据库 schema 和工具定义生成;
- 在在线执行阶段,Agent 会随着对话进展主动调用
retrieve_policy()去检索相关条目; - 在任务结束之后,一个离线的 Policy Agent 会结合整条轨迹和开发者反馈,判断当前的政策理解哪里出了问题,并对记忆条目做修订;
- 下一轮任务开始时,Agent 读取到的已经不是原始政策,而是被修正过的”政策理解”。
更重要的是,这个记忆不是按”任务”来组织,而是按 tool-capability level 来组织。每条记忆设计成一个半结构化条目,其中包含触发条件、前置校验、资格条件、动作流程,以及最关键的一项——KEY INSIGHT,也就是从反馈中学到的、能够修补政策缺口的那条新理解。
从工程上看,这个设计把”自然语言政策”转成了一层更接近可执行授权逻辑、又仍然保留可审计性的中间表示。
与其他 memory 方法的区别
论文把 PolicyBank 和几类已有 memory 机制做了对比,包括 Synapse、AWM 和 ReasoningBank。
像 Synapse 和 AWM 这种方法,主要是从成功轨迹中学习”下次怎么把任务做得更顺”,它们本质上是在优化执行层,因此面对 policy gap 时经常无能为力。论文甚至用了一个很形象的说法:这些方法会强化**“compliant but wrong”**的行为。
ReasoningBank 往前走了一步,因为它会利用失败轨迹,但它存的是任务级经验,而不是工具能力级的政策逻辑,所以仍然很难准确定位究竟是哪一条规则理解错了。
PolicyBank 的突破点就在这里:它并不是让 Agent 单纯”反思”,而是让它在更细粒度的政策位点上积累可复用的理解修补。
实验设计
为了验证 Agent 学到的到底是”规则边界”还是”个案记忆”,作者对 τ-Bench 做了扩展,在 airline 和 retail 两个领域中,为每个 parent task 配置三类 sister tasks:
- 更简化的版本,测试是否真正抓住了政策修补点;
- 不同实例,看能不能迁移到其他用户和对象;
- 复杂变体,看在更高认知负载下,修正过的政策理解还能不能稳定发挥。
论文在评测指标上采用了 pass^k,而不是常见的 pass@k。区别在于,pass^k 看的是 k 次独立试验是否都成功,更强调稳定性。
实验结果
从结果看,核心结论非常鲜明:一旦问题从执行层切换到政策理解层,现有方法的表现会明显崩掉。
以 Gemini-3-Pro 在 airline 域上的结果为例,No Memory 在原始任务上的 pass^1 还有 0.66,但到了专门检测 policy gap 的 sister tasks 上,直接掉到 0.01,几乎等于失效。
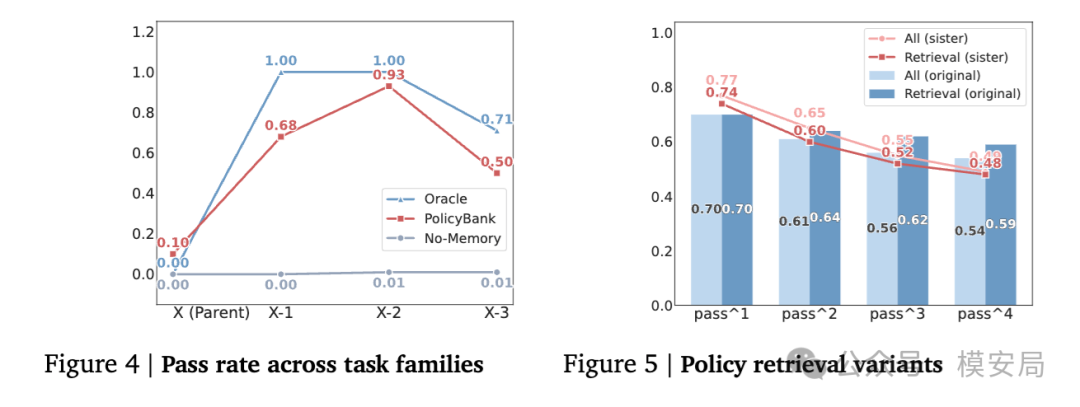
相比之下,PolicyBank 可以把 Gemini-3-Pro 在 airline sister tasks 上的 pass^1 提到 0.74,把 Claude-4.5-Opus 提到 0.72;在 retail 域上,Gemini-3-Pro 从 0.31 提升到 0.83,Claude-4.5-Opus 从 0.47 提升到 0.78。论文在摘要中总结,PolicyBank 最多能弥合 82% 通往 human oracle 的差距。
论文还做了一个消融实验:如果只给 reward,效果提升有限;如果同时给出解释,告诉它”哪里错、应该如何修”,效果会显著上升。这说明 policy evolution 不是一个只靠奖惩信号就能解决的问题,它需要面向规则边界的高质量反馈。
启发
这篇论文最重要的启发,是它把 Agent 治理体系里一个长期模糊的层次清晰地提了出来。
过去我们更习惯把系统拆成检索层、推理层、执行层和运行时防护层,但这篇论文提示我们,还应该单独抽出一个**“政策理解层”**。这一层关注的不是”有没有拿到规则”,也不是”有没有执行动作”,而是”Agent 对规则边界的理解到底是不是和组织真实意图一致”。
PolicyBank 提供的思路是:把失败轨迹、开发者反馈、工具能力和政策条目串起来,形成一个可演化、可检索、可审计的政策理解记忆层。
当然,这里也必须保持克制。PolicyBank 适合做的是政策理解的修补与沉淀,不适合在高风险场景里无约束地自动改官方规则。真正进入生产之后,它仍然需要版本管理、人工审核、冲突检测、回归测试和权限约束。
写在最后
如果用一句话概括这篇论文:PolicyBank 真正指出的问题是,Agent 最大的风险未必来自”不按规则做事”,而可能来自”把规则理解错了,还持续稳定地按错的理解去做事”。
这也是它对 Agent 安全讨论最有价值的地方——它把注意力从运行时拦截再往前推了一层,落到了更基础、也更容易被忽视的地方:组织写给 Agent 的那些自然语言规则,到底有没有被正确理解。
同专题推荐
查看专题LASM:Agent 安全的七层攻击面
论文 LASM 提出七层攻击面模型与四类时间性分类,重构 Agent 安全的分析框架:从模型层、认知层、记忆层、工具执行层、多 Agent 协同层、供应链层到治理层,揭示 Agent 安全本质是分布式系统安全问题
AgentBound:给 MCP Server 套上权限边界
MCP 解决了 Agent 接入工具和资源的标准化问题,但安全机制没有同步跟上。 MCP 规范定义了 Host、Client、Server 之间的角色和消息交互,但在实际落地中,很多安全责任被交给应用开发者和宿主应用自行处理。 结果就是,MCP Server 往往以“默认可信”的方式运行。 这和移动…
当 Mythos 成为对手:高能力 AI 的安全边界正在失效
这两天,一篇题为 《When the Agent Is the Adversary》 的论文在安全圈引发了不小关注。它讨论的不是传统意义上的提示注入,也不是常见的越狱绕过,而是一个更让人不安的问题:当高能力 Agent 不再只是“被保护对象”,而开始成为“主动对手”时,我们今天熟悉的那些安全边界,还…