从"技术滥用"到"应用乱象":中央网信办2026 AI 专项行动释放了什么新信号
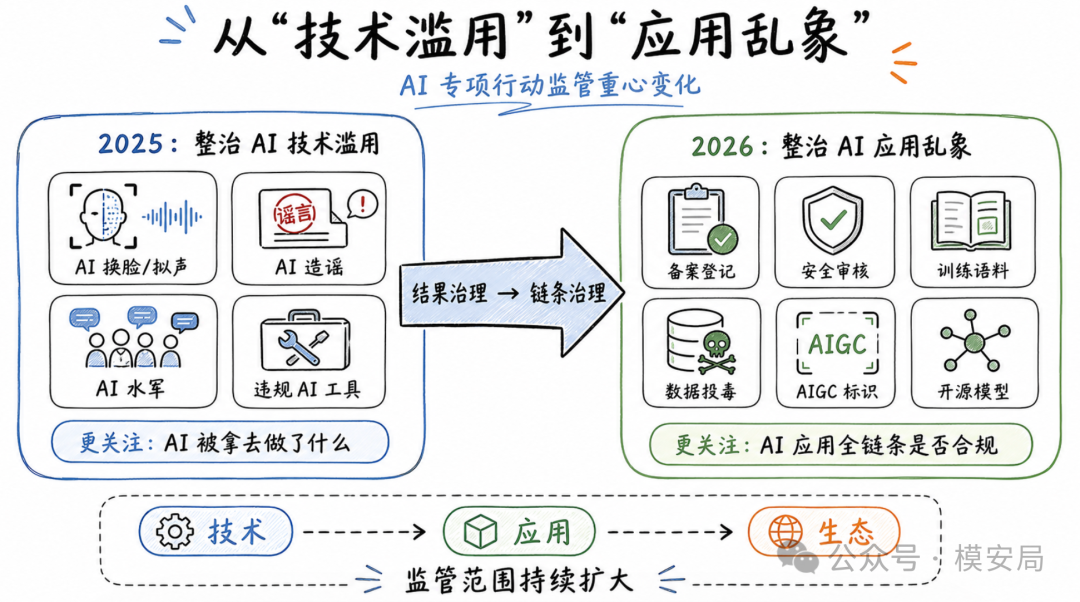
去年打的是 AI 黑灰产,今年管的是 AI 产业链——监管正在从治理"AI 技术被滥用",进入治理"AI 应用全链条"的阶段。

2026年 4 月 30 日,中央网信办部署开展为期 4 个月的”清朗·整治AI应用乱象”专项行动。
如果只看标题,这似乎是一次常规的网络治理行动。但把它和去年 4 月 30 日中央网信办部署的”清朗·整治AI技术滥用”专项行动放在一起看,变化就非常明显了。

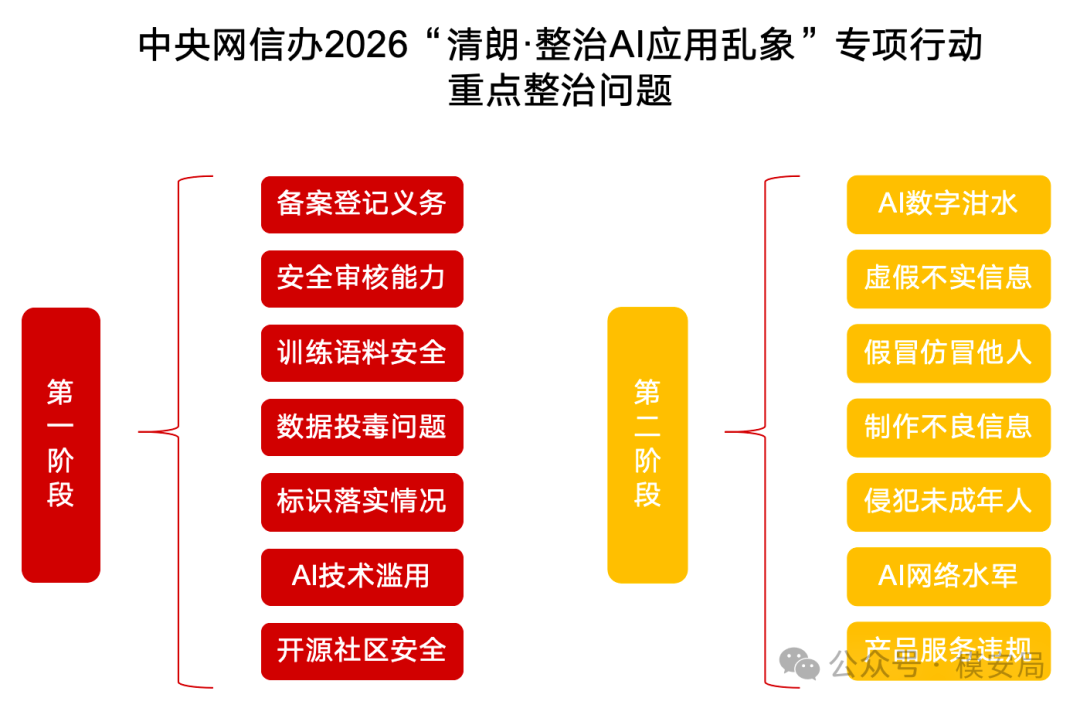
去年的关键词是”技术滥用”。监管重点主要是 AI 换脸、AI 脱衣、AI 造谣、AI 水军、违规 AI 应用等典型问题。也就是说,监管关注的是”有人拿 AI 干了什么坏事”。
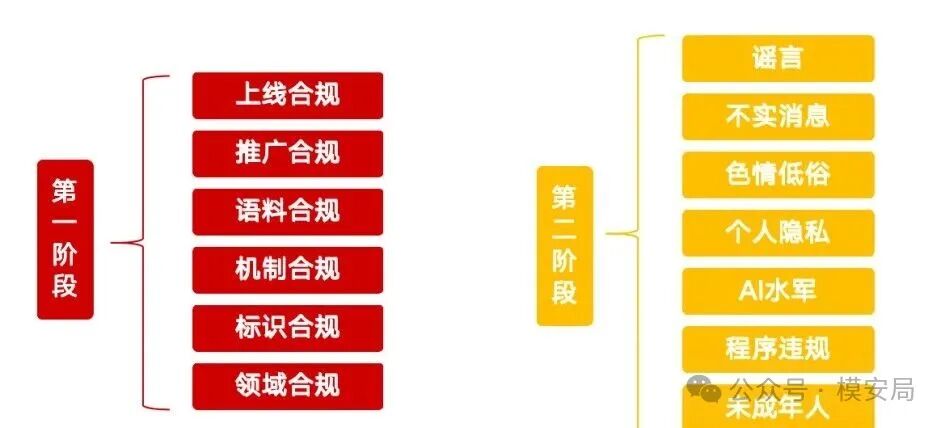
今年的关键词变成了”应用乱象”。监管重点从具体违规内容和黑灰产工具,进一步前移到大模型备案登记、平台安全审核、训练语料安全、AI 数据投毒、生成合成内容标识、智能体滥用和开源模型安全管理。
这背后的信号很清楚:AI 监管正在从治理”AI 技术被滥用”,进入治理”AI 应用全链条”的阶段。

名称变了
去年专项行动叫”清朗·整治AI技术滥用”,今年叫”清朗·整治AI应用乱象”。
这个命名变化很值得注意。
“技术滥用”强调的是 AI 被不法主体拿去做了什么,比如造谣、诈骗、换脸侵权、色情低俗、刷量控评。它的治理对象更偏向行为结果,也更接近过去互联网内容治理中的黑灰产打击。
“应用乱象”覆盖范围更大。它不只看 AI 生成了什么内容,也看这个 AI 应用从哪里来,用了什么模型,模型有没有备案,训练数据是否合规,生成内容有没有标识,是否具备安全审核能力,开源模型和数据集有没有管理机制。
这意味着监管视角已经从”事后处置问题内容”,转向”事前规范 AI 服务和应用”。
过去,一个 AI 产品出问题,平台和厂商可能会解释说,这是用户滥用,是外部攻击,是第三方模型的问题,是开源社区上传的数据集有问题。到了今年,这种解释空间会越来越小。只要你在 AI 应用链条中提供模型、数据、工具、入口、分发、托管、插件、智能体或开源资源,就可能需要承担相应的安全责任。
入口变清楚了
今年第一阶段第一类问题,就是”未按规定履行大模型备案登记义务”。
这个排序本身就有信号意义。
去年也提到备案登记问题,但它更多放在”违规 AI 产品”这类问题里,和 AI 脱衣、声音克隆、人脸克隆等违规功能放在一起。今年则把”应备未备”单独列为第一类突出问题,说明大模型备案登记已经成为 AI 服务上线运营的基础门槛。
这对大量 AI 应用开发者尤其关键。
很多 AI 应用并不训练自己的底层模型,而是调用第三方大模型 API,外面套一层网页、小程序、App 或智能体工作流。过去这类产品常见的想法是:底层模型已经备案,应用层只是调用接口,合规压力应该主要在模型厂商那里。
今年的专项行动释放的信号是,应用层也不能天然免责。面向公众提供 AI 服务时,产品本身是否登记,使用的模型是否合规,服务页面是否公示相关信息,应用场景是否存在高风险功能,都会成为治理对象。
这会直接影响 AI 写作、AI 陪聊、AI 搜索、AI 数字人、AI 图片视频生成、AI 智能体平台、AI 客服、AI 办公助手、AI 法律咨询、AI 医疗问答等产品。
从产业角度看,AI 产品的合规入口正在变得更清楚:先看底层模型是否合规,再看上层应用是否合规,最后看具体内容和行为是否合规。AI 应用不能再只拼功能、拼价格、拼流量,也要拼安全能力和合规能力。
能力被审视
去年监管关注的是平台有没有建立内容审核、意图识别、安全自评估等措施。今年的表述更深入,直接点名”模型底层安全能力缺失""设计训练及部署应用阶段价值导向存在偏差""纠偏能力不足""缺乏安全围栏机制""审核过滤能力不足”。
这说明监管不再只看企业有没有做一层内容审核,还会看模型和应用本身的安全能力是否扎实。
这对大模型厂商是一个更高要求。内容审核接口只能解决一部分问题,模型底层安全能力不足时,外层审核很容易被绕过。比如用户通过角色扮演、语义拆分、多轮诱导、代码包装、翻译转换等方式绕过限制,模型如果自身没有足够的风险识别和拒答能力,最终仍然可能生成违法不良信息。
这对 AI 应用平台也一样。一个应用即使调用了安全性较好的底层模型,只要在提示词、插件、工具调用、上下文拼接、联网检索、知识库召回等环节缺少安全设计,也可能把模型带到高风险输出上。
所以,今年的监管重点已经从”有没有安全措施”,转向”安全措施是否真的有效”。
这会推动企业建立更完整的大模型安全体系,包括训练前的数据审核,训练后的安全评测,部署阶段的红队测试,运行时的输入输出审核,敏感问题的拒答和安全代答,日志留存、人工复核、投诉处置和持续迭代。
一句话说,AI 安全不再只是上线之后补一个审核模块,而是要嵌入模型设计、训练、部署和运营全流程。
数据被前移
今年最值得关注的新增点之一,是”AI 数据投毒”。
去年也提到训练语料管理不严,重点包括数据来源不合规、侵犯知识产权和隐私权、使用虚假无效信息、缺乏训练语料管理机制等。今年在此基础上进一步拆出”AI 数据投毒”,并且把问题描述得很具体:篡改训练语料、伪造权威数据、使用 GEO 技术恶意营销、炒作和教授数据投毒方法、兜售教程和工具,以及模型生成回答时缺少信源交叉验证和风险提示。
这个变化非常重要。
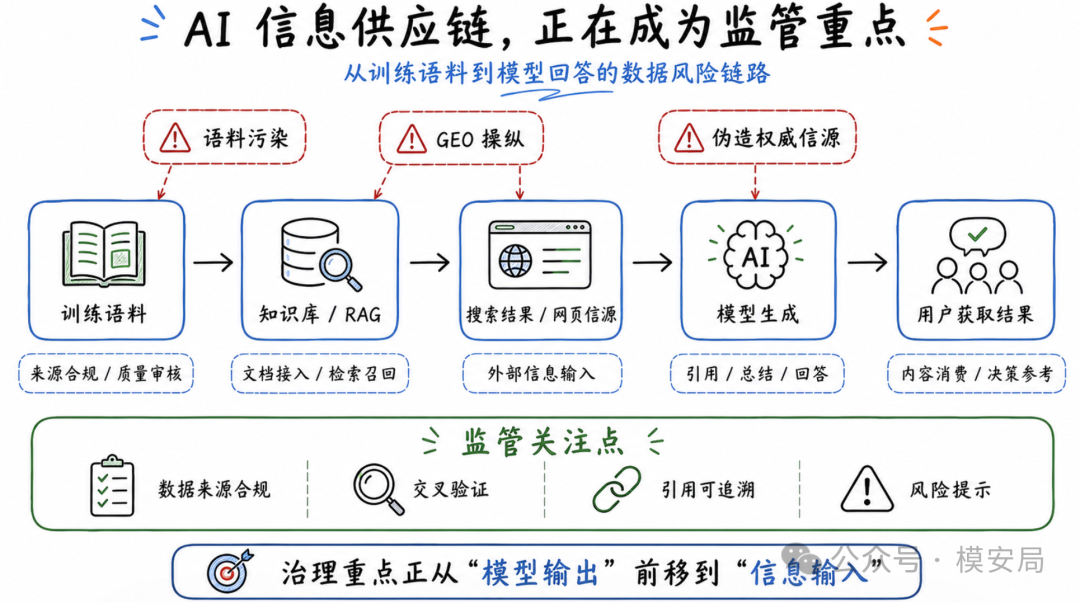
它说明监管已经开始关注 AI 模型的信息供应链。模型最后生成什么内容,不能只看输出端,也要看它训练时吃了什么数据,检索时读了什么网页,引用时依赖了什么信源。
这对 AI 搜索、RAG 知识库问答、企业智能客服、政务问答、投研助手、联网智能体尤其关键。这类系统往往不是只依赖模型内部参数,而是会实时读取搜索结果、网页内容、企业文档、知识库条目和第三方工具返回结果。如果这些外部信息源被污染,模型就可能被引导生成错误信息、虚假结论、商业软文甚至有害内容。
这也是为什么 GEO 会被写进专项行动。GEO 本来是生成式搜索引擎优化,正常情况下可以理解为围绕 AI 搜索和大模型回答进行内容适配。但当它被用于伪造权威信源、操纵模型引用、恶意影响模型回答时,就会从营销手段变成信息污染。
未来,AI 产品不能只回答”模型准不准”,还要回答”模型依据的信息可靠吗”。知识库有没有被投毒,搜索结果有没有风险,引用来源能否追溯,多个信源之间有没有交叉验证,风险信息有没有提示,这些都会成为 AI 应用安全能力的一部分。
标识进入执行期
AIGC 标识也是去年和今年都出现的重点,但今年的口径明显更硬。
去年更多是在强调,服务提供者要给生成合成内容添加显式标识和隐式标识,传播平台要提升生成合成内容检测鉴伪能力。到了今年,通知直接点名《人工智能生成合成内容标识办法》及配套强制性标准,关注标识大小、位置、透明度,跨平台隐式标识互识互认,生成合成内容周边显著提示,以及违规”去标识”工具服务。
这说明 AIGC 标识已经从原则要求进入执行检查阶段。
很多产品过去把标识理解得比较简单,觉得在图片角落加一行”AI生成”,或者在视频页面提示一下就够了。但从今年的专项行动看,监管关心的不只是有没有标识,还包括标识是否规范,是否容易被用户看到,隐式标识是否能被平台识别,跨平台传播后是否还能识别,用户能不能轻易去除标识,平台是否存在”去标识”教程和工具。
这会给内容平台带来新的压力。
平台不只要给自己生成的 AI 内容加标识,还要识别用户上传的 AI 内容;不只要识别显式标识,还要处理隐式标识;不只要管理内容本身,还要治理去标识服务、去标识教程和相关工具链。
这背后的逻辑很直接:当 AI 图片、AI 视频、AI 音频越来越逼真时,社会需要一种可识别、可追溯、可治理的内容标识机制。否则,真假边界被不断冲淡,谣言、诈骗、侵权、假冒、舆论操纵都会变得更难治理。
Agent 被点名了
今年专项行动中还有一个很新的表述:利用智能体技术窃取用户数据或账户密钥,侵犯他人隐私或合法权益。
这句话很短,但分量很重。
过去谈 AI 风险,很多人想到的是模型生成有害内容。现在智能体开始具备浏览网页、调用工具、执行代码、操作文件、连接数据库、调用 API、控制工作流的能力,风险也就从”说错话”升级为”做错事”。
一个聊天机器人如果输出了错误建议,风险主要停留在内容层。一个智能体如果拿到了浏览器权限、账号权限、邮箱权限、云盘权限、代码仓库权限或企业系统权限,风险就会进入真实业务流程。它可能误发邮件,误删文件,泄露数据,调用高风险接口,也可能被间接提示注入诱导,把用户密钥、内部文档、系统指令和隐私信息发出去。
今年把智能体滥用写进专项行动,说明监管已经注意到 AI 应用正在从内容生成工具变成行动执行系统。
这对 Agent 产品是一个明确提醒:权限边界、工具调用审批、敏感信息保护、凭证管理、动作审计、外部网页风险识别、间接提示注入防护,都将成为基础安全能力。
未来一个 Agent 产品是否安全,不能只看模型有没有拒答能力,还要看它能访问什么数据,能调用什么工具,能执行什么动作,高风险动作是否需要人工确认,执行过程是否有日志,出现问题后能否追溯和处置。
开源也要治理
今年新增”开源模型安全管理不到位”,同样值得关注。
通知提到,开源社区缺乏身份认证和安全管理机制,对社区上传的数据集、模型代码等内容未建立有效审核和应急处置机制,未及时清理存在严重风险隐患的数据集或开源模型。
这说明监管视野已经延伸到开源生态。
过去很多人对开源模型有一种天然宽容,认为开源社区只是技术交流平台,风险主要由下载使用者承担。但现实情况是,模型权重、数据集、微调代码、插件工具、提示词模板、越狱样本、恶意模型文件,都可能通过开源社区大规模传播。
尤其是现在很多企业会直接下载开源模型做微调,或者把开源模型部署到内部业务里。如果模型本身含有后门、恶意能力、污染数据,或者数据集存在违法不良信息和侵权内容,企业就会把外部风险引入自己的生产系统。
因此,开源不等于免责。模型托管平台、开源社区、企业内部模型仓库,都需要建立基本的安全准入和应急处置机制。上传者身份认证、模型风险标签、数据集审核、举报下架、恶意模型处置、许可证和数据来源说明,都会变得越来越重要。
这对行业的影响可能会逐渐显现。未来企业采购或使用开源模型时,不能只看参数规模、榜单成绩和推理成本,也要看模型来源、训练数据说明、安全评测结果、许可证风险和已知滥用风险。
内容治理升级
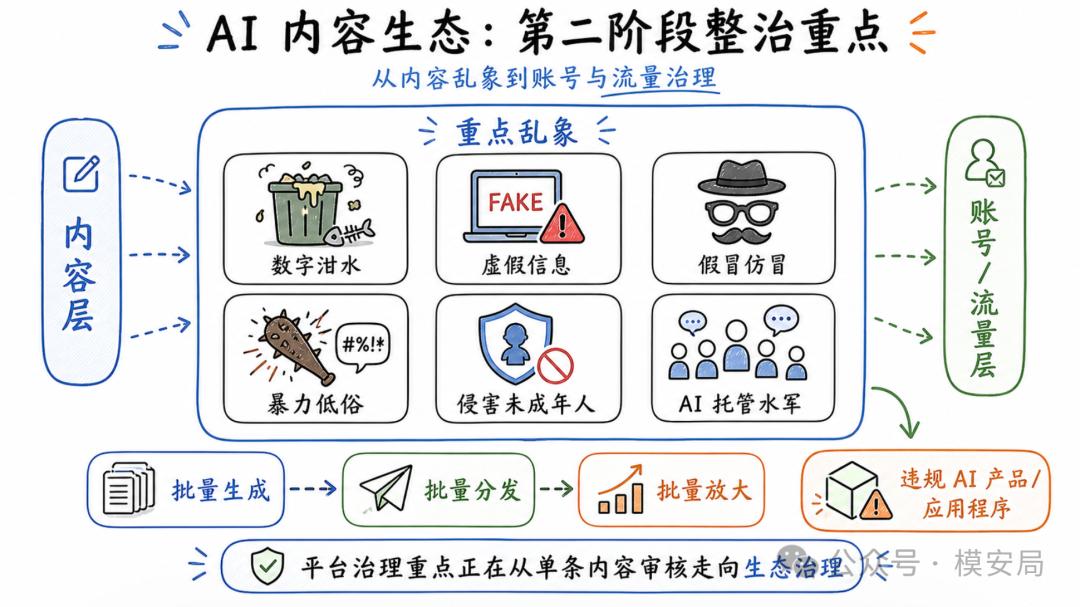
第二阶段重点整治 AI 信息内容乱象,包含”数字泔水”、虚假信息、假冒仿冒、暴力低俗、侵害未成年人权益、AI 托管水军和违规 AI 应用程序。
这些问题看起来和去年类似,但今年的表达更细,也更贴近 AI 内容生态的新变化。
其中最有代表性的词,是”数字泔水”。
这个词指向的不只是违法违规内容,也包括大量逻辑混乱、价值空洞、低质同质、带有错误价值观或扭曲文化认知的 AI 内容。它可能没有明显触碰违法红线,但会持续污染信息环境,挤压优质内容,干扰平台推荐系统,影响用户认知。
这对内容平台是一个新的治理压力。
传统内容审核更多关注单条内容是否违法违规。AI 内容泛滥之后,平台还要关注内容生产方式是否异常,账号是否批量生成低质内容,MCN 是否用 AI 批量蹭热点,是否存在内容农场式生产,是否通过 AI 生成大量相似文案和视频污染推荐池。
今年还特别提到 AI “魔改”经典,歪曲解构传统文化、历史人物、历史典故,恶搞古典名著精神内涵,颠覆重要人物人设。这说明 AI 内容治理已经不只停留在真假和低俗层面,也开始进入文化表达、历史叙事和价值导向层面。
对于平台来说,这会让 AI 内容治理从”审核问题”变成”生态问题”。平台需要治理的不只是某一条违规内容,而是整套 AI 批量生产、分发、放大和变现机制。
水军自动化了
去年已经提到利用 AI 技术养号、批量注册运营社交账号、AI 内容农场、AI 洗稿、群控刷量等问题。今年的关键词进一步变成”AI 托管”。
这个词比”AI 辅助”更值得警惕。
“AI 辅助”意味着人还在主导,AI 只是帮助写文案、修图、生成评论。“AI 托管”意味着账号运营流程正在被自动化系统接管。它可以自动注册账号,自动养号,自动寻找热点,自动生成内容,自动发布,自动评论,自动转发,自动控评,自动制造虚假流量。
这会改变网络水军的形态。
过去水军依赖人工团队和群控工具,规模化运作成本仍然较高。AI 加入之后,低质文案、情绪化评论、热点跟帖、洗稿内容都可以快速生成,账号行为也可以更像真人。平台如果只看单条内容,很难识别背后的自动化组织行为。
因此,未来平台风控需要同时看内容、账号、设备、行为、关系和流量。AI 生成同质文案识别、账号异常行为检测、群控设备识别、虚假互动图谱、账号交易链追踪,都会成为治理 AI 水军的关键能力。
这也说明,AI 内容安全和平台风控正在融合。AI 乱象不只是内容审核部门的问题,也会牵涉账号安全、反作弊、广告风控、推荐治理和舆情治理。
安全成为门槛
把今年和去年的专项行动放在一起看,可以得出一个更大的判断:AI 安全正在从”加分项”变成”准入项”。
去年,监管重点更像是在清理 AI 技术滥用带来的明显乱象。到了今年,监管开始系统性检查 AI 应用的基础合规能力:模型是否备案,安全审核是否有效,训练语料是否干净,数据来源是否合规,生成内容是否标识,智能体权限是否可控,开源社区是否有安全管理机制。
这意味着 AI 企业未来不能只拿”模型能力强""用户增长快""功能体验好”作为竞争优势。只要面向公众提供 AI 服务,安全和合规就会成为产品能否稳定运营的前提。
对大模型厂商来说,需要建立模型训练、评测、部署、迭代全过程的安全治理体系。
对 AI 应用开发者来说,调用第三方大模型并不能免除自身责任,应用层仍然要做好功能边界、用户管理、内容审核、标识提示、日志留存和风险处置。
对内容平台来说,治理重点要从单条内容审核扩展到 AI 生成内容识别、账号行为风控、批量低质内容治理和水军生态打击。
对开源社区来说,模型、数据集和代码都可能成为风险载体,需要建立上传审核、身份认证、风险标签、举报下架和应急响应机制。
对企业客户来说,采购 AI 服务时也不能只看价格和效果,还要看模型备案情况、安全评测结果、数据处理方式、AIGC 标识能力、内容安全能力、Agent 权限控制和日志审计能力。
AI 正在成为基础设施,监管也会按照基础设施的方式来要求它。能力越强,触达的人越多,承担的安全责任也越高。
写在最后
如果用一句话概括今年相对去年的变化,可以说:去年打的是 AI 黑灰产,今年管的是 AI 产业链。
2025 年的专项行动,重点是 AI 技术被拿去做了什么。2026 年的专项行动,重点变成 AI 应用从哪里来、用什么模型、吃什么数据、生成什么内容、如何标识、怎样传播、出了问题谁负责。
这也是 AI 行业走向成熟必然要经历的一步。
当 AI 只是一个生成工具时,监管重点自然是内容结果。当 AI 变成模型服务、搜索入口、知识引擎、账号运营工具、智能体系统和开源生态的一部分时,治理也必须进入更深的链条。
对行业来说,这未必是坏事。野蛮生长阶段,劣币往往跑得更快。进入规范治理阶段,真正有技术能力、安全能力和长期运营能力的企业,反而更容易建立壁垒。
AI 应用的下半场,不只是比谁生成得更快、更像、更便宜,也要比谁更安全、更可控、更可信。
同专题推荐
查看专题智能体正式进入监管周期:中国开始为 Agent 时代建立治理底座
2026年5月8日三部委联合印发《智能体规范应用与创新发展实施意见》,监管对象从大模型转向智能体,提出七层安全框架、权限边界、行为围栏、AIP协议与智能互联网等核心议题,标志着 Agent 时代治理底座正式铺底
中国大模型输出内容的法律法规体系
从基础法律到生成式AI专项规章,系统梳理中国大模型内容安全的五层法律框架:网络安全法、数据安全法、算法监管规定、生成式AI暂行办法及技术标准,厘清平台主体责任与合规路径。
全球AI治理的政治制度基础、治理逻辑、立法结构和治理工具
梳理全球AI治理的三条主路径,比较不同政治制度下的治理逻辑、立法结构与工具组合,并聚焦生成式AI、深度合成与算法透明度的差异化监管。