工具不是免费的:Agent 正在为“调用工具”交税
工具,正在成为 Agent 时代最常见的能力增强方式。
工具,正在成为 Agent 时代最常见的能力增强方式。
模型不会算,就接计算器;模型不知道实时信息,就接搜索;模型需要执行任务,就接 API;模型要处理企业流程,就接数据库、工单系统、浏览器、代码执行器。很多时候,我们默认认为:模型加上工具,能力就会变强,推理就会更可靠。
但这篇论文提出了一个很值得警惕的判断:工具调用不是免费的。

https://arxiv.org/pdf/2605.00136
论文研究的是 LLM Agent 在语义干扰场景下的表现。作者发现,当输入中混入看似相关、但对任务没有帮助甚至会误导模型的信息时,工具增强推理并不一定优于原生 CoT;更关键的是,工具调用协议本身可能成为新的错误来源。作者把这种由工具调用协议引入的性能损耗称为 tool-use tax,也就是“工具使用税”。
这不是一个关于“工具有没有用”的简单问题,而是一个更接近真实工程部署的问题:什么时候应该让 Agent 调用工具?什么时候工具会帮忙?什么时候工具反而会把模型带偏?
Agent 时代:模型不够,工具来凑
过去两年,Agent 系统有一个非常清晰的发展方向:把大模型从单纯的文本生成器,改造成可以调用工具、访问外部环境、执行复杂任务的系统。
这个方向当然合理。大模型本身有很多天然短板:知识可能过期,计算可能出错,不能直接访问业务系统,也不能真正执行操作。工具调用看起来正好补上这些短板。函数调用、搜索增强、代码执行、数据库查询、浏览器操作,都被视为让模型进入真实世界的关键通道。
论文并不否认工具的重要性。它真正质疑的是另一个更隐蔽的前提:只要加上工具,系统就会更稳。
作者指出,很多工具使用评测是在相对干净的输入条件下完成的。但真实世界里的输入并不干净,用户问题、网页内容、检索结果、业务日志、历史工单里,经常夹杂大量语义相关但推理无关的信息。这些内容看起来像证据,实际上可能只是噪声。论文把这类内容称为 semantic distractors,语义干扰项。
在 Agent 场景下,语义干扰会变得更麻烦。因为 Agent 不只是“读完输入后直接回答”,它还要决定是否调用工具、调用哪个工具、如何构造参数、如何理解工具返回结果、是否继续下一步调用。每一个中间环节,都可能让噪声进入推理链。
这就是论文的核心出发点:工具增强并不是简单加法,而是会改变模型推理路径的系统机制。
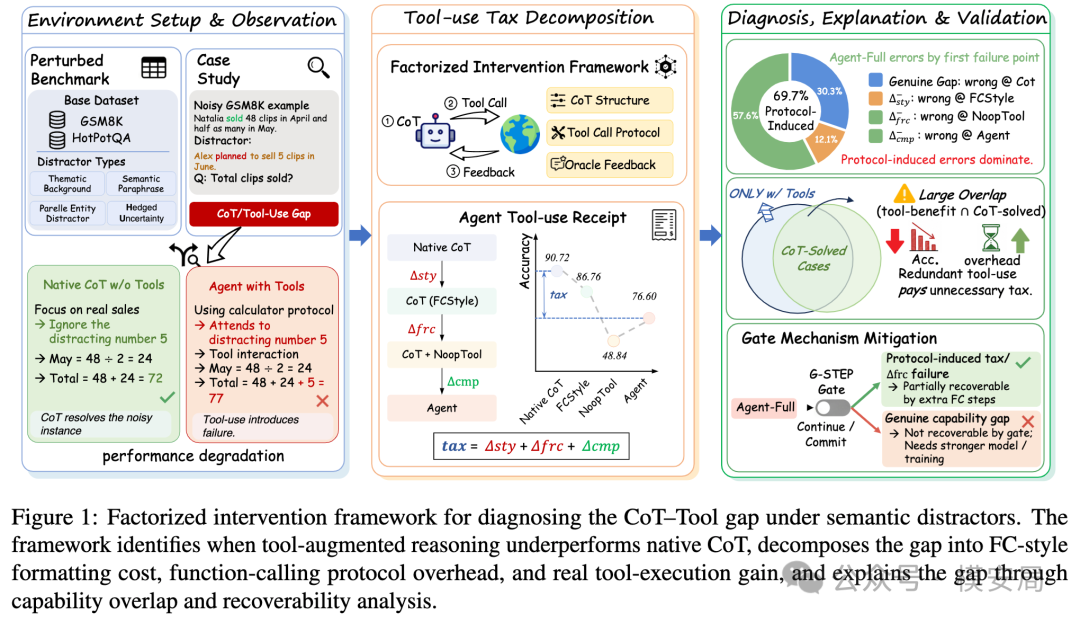
论文怎么构造“语义干扰”
为了观察工具调用在噪声环境下的表现,作者基于两个经典任务构造了带语义干扰的数据集。
一个是 GSM8K-Sem-Distractor,主要测试数学推理;另一个是 HotPotQA-Sem-Distractor,主要测试多跳问答。前者更像“连续计算任务”,后者更像“检索问答任务”。
这里的干扰项不是随机乱码,也不是无关文本,而是四类“看起来很像有用信息”的语义噪声。
第一类是主题背景信息。比如题目问某人卖了多少夹子,干扰项会补充销售趋势、市场变化、未来策略之类的背景。这些内容和主题有关,但对计算没帮助。
第二类是语义改写。它会把题目里的关键信息换一种说法重新表达,制造冗余信息。
第三类是平行实体干扰。它会引入另一个人物、另一个时间、另一个相似事件。比如原题问 Natalia 4 月和 5 月卖出的夹子,干扰项可能加入 Alex、Ethan、Sophia 等其他人卖夹子的描述。这类干扰最容易让模型把不同实体的信息混在一起。
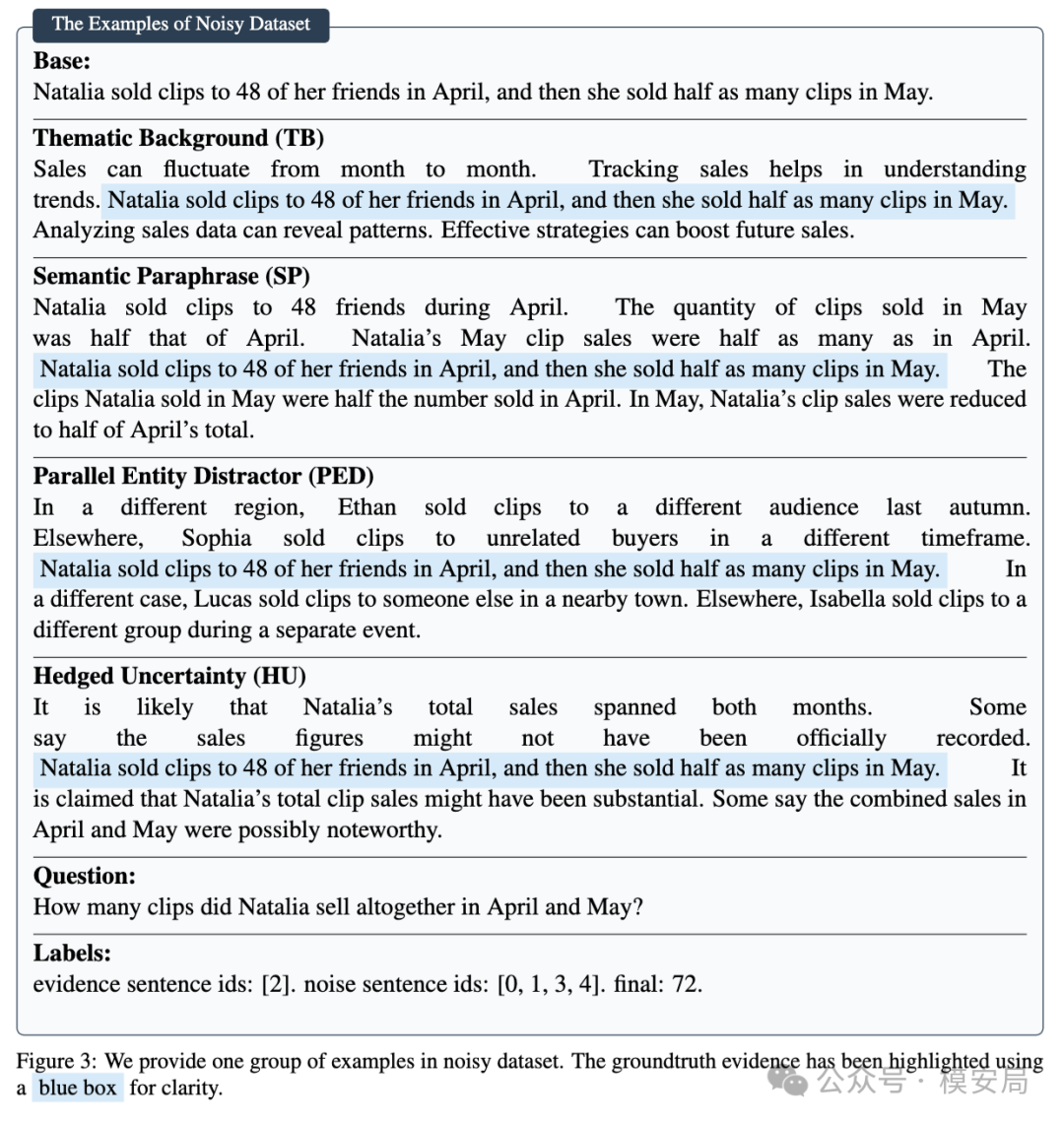
第四类是带不确定性的表述。比如加入 “据说”“可能”“尚未正式记录” 这类措辞,让模型在证据选择上更容易摇摆。
这几类干扰很贴近真实 Agent 场景。企业知识库里经常有相似但不同版本的制度文档,安全日志里经常有相似但不同主机的告警,运维工单里也经常有同类问题的历史记录。它们不是“无关噪声”,恰恰是最危险的那种噪声:看起来相关,但推理上不该被采用。
把工具调用拆成三层成本
这篇论文最有价值的地方,不只是发现 Agent 可能输给 CoT,而是设计了一套拆解方法,试图回答:到底是哪一步让 Agent 变差了?
作者提出了一个 Factorized Intervention Framework,因子化干预框架。它把从原生 CoT 到完整工具 Agent 的过程拆成四个状态:
NoTool-CoT → NoTool-FCStyle → Agent-NoopTool → Agent-Full
这四个状态可以理解为逐步加组件。
NoTool-CoT 是最普通的链式思考,不使用工具。
NoTool-FCStyle 仍然不使用工具,但把提示词改成函数调用风格,用来观察“函数调用格式”本身是否会影响模型。
Agent-NoopTool 开始进入工具调用协议,但工具返回的是空操作结果,用来隔离“工具交互协议”本身带来的损耗。
Agent-Full 才是真正完整的工具 Agent,模型可以正常调用工具并获得真实结果。
基于这条链路,论文把工具调用的整体影响拆成三个部分。
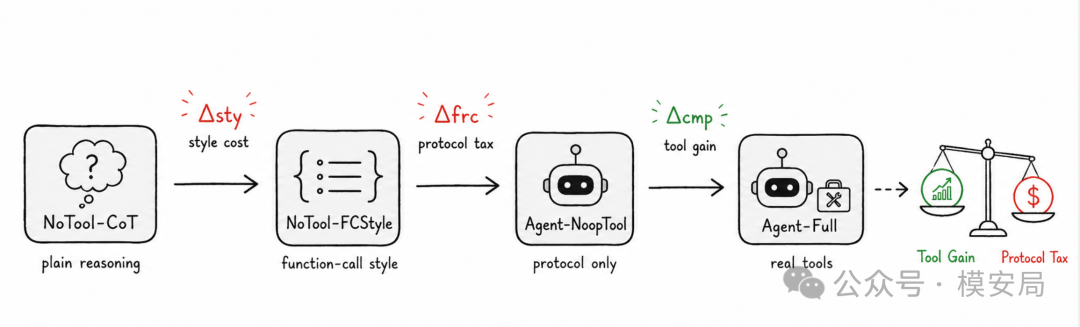
第一个是 ∆sty,也就是从普通 CoT 变成函数调用风格提示词带来的影响。它对应的是格式成本。
第二个是 ∆frc,也就是进入函数调用协议之后产生的协议开销。这里还没有真实工具收益,主要观察工具调用交互机制本身是否会把模型带偏。
第三个是 ∆cmp,也就是真正执行工具之后带来的收益。比如计算器确实算对了,搜索确实找到了证据,API 确实返回了结果。
最终,完整 Agent 相对 CoT 的准确率变化,可以写成:
Acc(Full) − Acc(CoT) = ∆cmp + ∆frc + ∆sty
这套拆法非常重要。因为它把过去一个模糊的问题拆开了:工具有没有用,不只取决于工具本身有没有能力,还取决于工具调用协议会不会破坏原本正确的推理路径。
数学推理里,Agent 明显输给 CoT
实验结果非常直接。
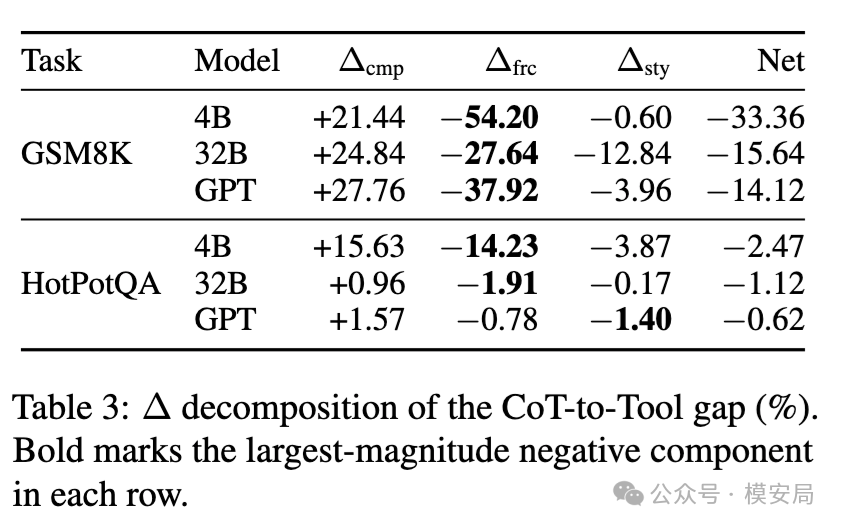
在 GSM8K-Sem-Distractor 上,完整工具 Agent 的表现显著低于原生 CoT。GPT-4.1-mini 的 Agent-Full 准确率是 76.60%,而 CoT 是 90.72%;Qwen3-4B 的 Agent-Full 是 52.08%,CoT 是 85.44%;Qwen3-32B 的 Agent-Full 是 75.76%,CoT 是 91.40%。也就是说,在这个带语义干扰的数学推理任务上,Agent-Full 分别比 CoT 低 14.12、33.36、15.64 个百分点。
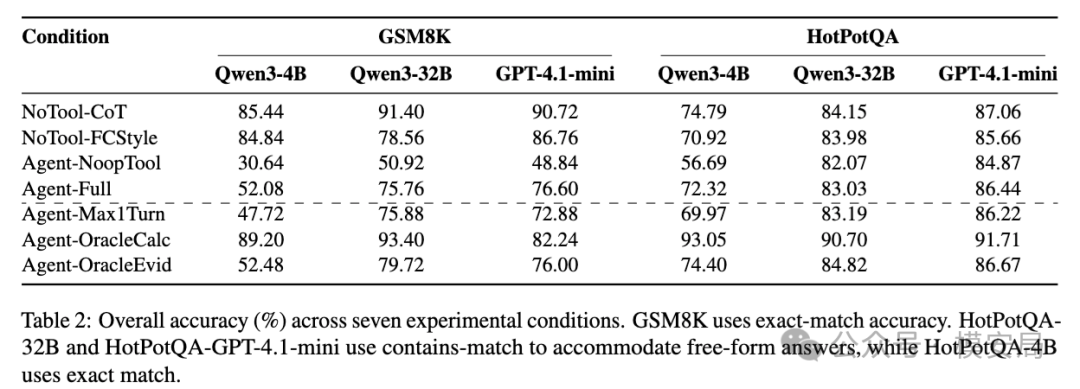
这组结果很有冲击力。因为 GSM8K 是数学题,而工具里有计算器。直觉上,计算器应该提升准确率。但结果显示,计算器带来的收益没有抵消工具调用协议带来的损耗。
HotPotQA 上的差距小得多。论文显示,在 HotPotQA-Sem-Distractor 上,Agent-Full 相对 CoT 的差距只有 0.62 到 2.47 个百分点。作者认为,这说明工具使用税具有明显的任务差异:数学推理这种连续计算任务,一旦中间步骤被噪声干扰,后面会一路错下去;检索问答任务中,模型的参数知识、部分证据和答案容错空间,可能会抵消一部分工具协议的不稳定性。
这里有一个很重要的产品启发:工具调用对不同任务的收益和风险完全不同。
对于需要连续推理、连续计算、连续状态更新的任务,工具调用协议里的任何一次偏移,都可能被放大成最终错误。对于事实问答类任务,工具调用的风险可能没那么大,因为答案经常可以被部分证据、常识或模型已有知识纠正。
所以,Agent 系统不应该笼统地说“这个场景要不要工具”,而应该区分任务结构。连续计算型、流程执行型、运维操作型、安全响应型任务,都比普通问答更需要谨慎设计工具调用链。
收益被“协议税”吃掉了
论文的核心结论并不是“工具没用”。恰恰相反,真实工具执行通常是有收益的。
在 GSM8K 上,∆cmp 一直是正的。Qwen3-4B 的工具执行收益是 +21.44,Qwen3-32B 是 +24.84,GPT-4.1-mini 是 +27.76。说明计算器确实提供了帮助。问题在于,工具调用协议带来的负收益更大。Qwen3-4B 的 ∆frc 是 -54.20,Qwen3-32B 是 -27.64,GPT-4.1-mini 是 -37.92。
这就形成了一个很清楚的结构:
工具执行本身在加分,但工具调用协议在扣分;当扣分大于加分,Agent 就会输给 CoT。
这也是“工具使用税”这个概念最有价值的地方。它提醒我们,工具调用的成本不只是延迟、Token、API 费用,也包括准确率层面的系统损耗。模型进入函数调用模式后,注意力分配、输出格式、决策路径、多轮交互状态都会发生变化。它不再是原来那个直接推理的模型,而是一个被协议包裹起来的执行体。
在产品设计里,这一点很容易被忽略。很多 Agent 系统为了显得“能力强”,会倾向于让模型尽可能多地调用工具。论文的结论刚好相反:工具调用应该是一个有门槛的动作,而不是默认动作。
判断一个工具是否值得调用,不能只看它有没有能力,还要看它提供的增量收益能不能覆盖协议成本。
很多工具收益和模型原生能力重叠
论文进一步提出了一个很重要的解释:Capability Overlap Principle,能力重叠原则。
意思是,很多看起来是工具帮模型做对的样本,其实原生 CoT 本来也能做对。也就是说,工具收益并没有真正提供独特能力,而是在重复模型已经具备的能力。
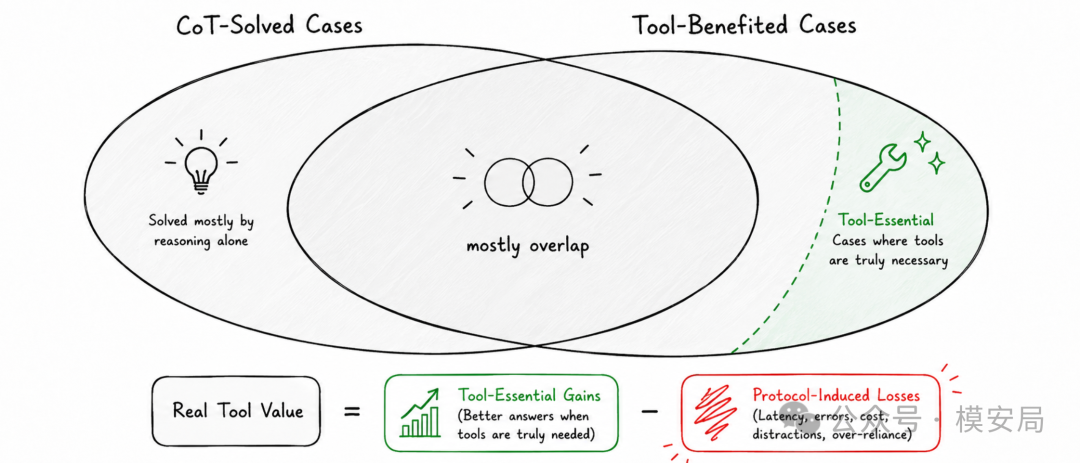
在 GSM8K 上,这种能力重叠非常明显。论文统计,在“Agent-Full 做对、Agent-NoopTool 做错”的工具受益样本中,同时也能被 CoT 做对的比例非常高:Qwen3-4B 是 89.6%,Qwen3-32B 是 94.0%,GPT-4.1-mini 是 95.4%。换句话说,真正“非工具不可”的样本只占很小一部分。
这就解释了为什么工具收益抵不过协议税。
如果工具提供的是模型本来就会的能力,那么工具收益就是冗余收益;但工具调用协议的损耗会作用在整个流程上。最后的结果就是:工具帮你拿回了一些本来就能拿到的分数,却又因为协议复杂度丢掉了更多本来能做对的样本。
这对 Agent 产品非常关键。很多时候,我们会高估工具的价值,因为只看到“用了工具之后这个样本做对了”。但如果这个样本 CoT 本来也能做对,那工具并没有真正贡献增量能力。真正应该关注的是:
工具解决了多少模型原本解决不了的问题?又破坏了多少模型原本能解决的问题?
这两个数的差,才是工具调用的真实价值。
大量错误是进入工具协议后才出现
论文还做了样本级归因,试图判断 Agent-Full 的错误最早出现在哪一步。
结果显示,在 GSM8K 上,大多数 Agent-Full 错误都是协议诱发的。Qwen3-4B 中 79.4% 的错误属于协议诱发,Qwen3-32B 是 75.8%,GPT-4.1-mini 是 69.7%。更细看,最大的错误来源是 ∆frc,也就是函数调用协议本身。
这点非常重要。
在真实 Agent 运行轨迹里,我们经常会看到几类错误:工具调用太少、证据漂移、最终整合失败、规划路线不对。直觉上,我们可能会把它们归因于模型规划能力差、工具结果理解能力差、上下文选择能力差。
但论文指出,这些表面症状背后的根因,很多是在进入函数调用协议之后才产生的。换句话说,模型原本可能能推对,但一旦被要求遵守工具调用格式、生成结构化参数、等待工具回传、再继续推理,就开始偏离原来的正确路径。
这对 Agent 安全评测很有启发。只看最终结果是不够的,只看工具有没有成功调用也不够。真正需要做的是过程归因:错误到底发生在原生推理阶段、函数调用格式阶段、工具协议阶段,还是工具执行阶段?
这会直接影响治理策略。如果是原生推理阶段就错,那需要增强模型能力。如果是工具执行阶段错,那需要修工具或修参数。如果是在 NoopTool 阶段就错,也就是还没有真实工具收益时就开始错,那问题很可能出在协议设计本身。
G-STEP:用门控机制减少一部分工具使用税
论文没有只停留在诊断,还提出了一个轻量级修复方法:G-STEP。
G-STEP 本质上是一个推理时门控机制,插在函数调用循环的终止点。当模型准备停止工具调用、直接给出最终答案时,G-STEP 会判断系统应该继续工具交互,还是提交当前答案。如果它判断应该继续,就会注入一个继续执行的提示,让模型再进行一步工具条件下的推理。作者还测试了一个 +CRITIC 版本,在工具调用之后加入显式反思步骤。
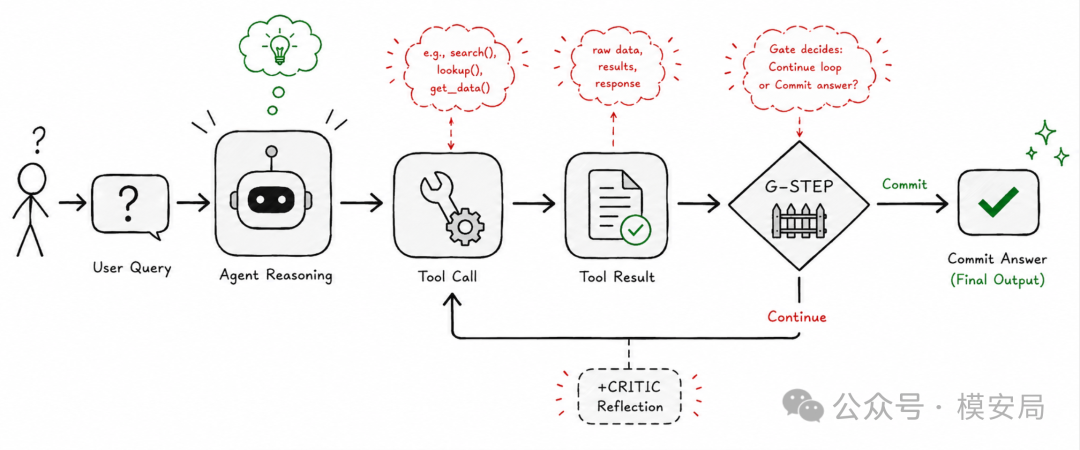
实验结果显示,G-STEP 对 GSM8K-4B 的帮助最明显。Qwen3-4B 在 GSM8K 上,Agent-Full 准确率是 50.64%,加 G-STEP 后提升到 69.12%,加 +CRITIC 后进一步提升到 74.88%,恢复了 Full-to-CoT 差距的 75.75%。但在 GSM8K-32B、GPT-4.1-mini 和 HotPotQA 上,收益就明显变小,有些场景甚至基本消失。
这说明 G-STEP 的价值是有边界的。它适合修复协议诱发错误,尤其是过早停止、工具步骤不足、工具循环没有走完这类问题。但如果任务瓶颈是模型真实能力不足,比如复杂证据综合、深层理解、跨文档推断,那么额外多走一步工具调用并不能解决根本问题。
这个结论很符合工程直觉。门控机制可以减少一部分流程错误,但不能把一个能力不足的模型变成强模型。它更像运行时安全控制,而不是基础能力提升。
对Agent安全的启发
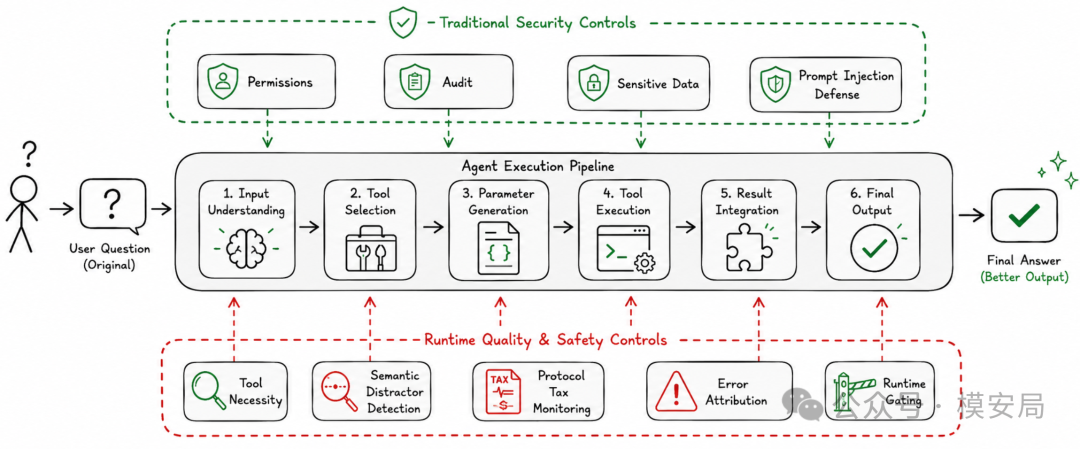
这篇论文对 Agent 安全最重要的启发是:Agent 的风险不只来自恶意工具、越权 API、提示注入或工具返回污染,也来自工具调用协议本身对推理路径的扰动。
过去我们讨论 Agent 安全,经常关注工具权限控制。比如哪些工具能调用,调用前是否需要确认,参数是否越权,结果里是否含有提示注入,是否会泄露敏感数据。这些当然重要,但这篇论文提醒我们,还要多看一层:这个工具调用本身有没有必要?
一个 Agent 原本可以直接回答的问题,如果被迫进入工具调用流程,可能会经历更多状态转换、更多上下文拼接、更多中间结果解释。每一步都可能把语义噪声放大。
在企业场景里,这个问题会更典型。
一个知识库 Agent 回答一个简单制度问题,检索结果里可能混入旧版本制度、相似部门制度、历史通知和用户评论。一个安全运营 Agent 分析一条告警,工具返回结果里可能包含相似 IP、相似进程、相似攻击链和历史误报。一个运维 Agent 处理服务异常,监控工具可能返回同集群、同业务线、相邻时间窗口的大量指标。
这些内容都不是传统意义上的恶意输入,但它们足以改变 Agent 的推理路径。
所以,Agent 安全控制平面不应该只做“危险工具拦截”,还应该做“工具调用必要性判断”和“工具调用扰动监测”。系统需要判断当前问题是否真的需要工具,需要观察模型是否在工具调用后开始关注无关实体,需要检测工具返回结果是否改变了原始任务目标,也需要追踪错误最早出现在推理链的哪个阶段。
这里可以形成一个很有价值的产品方向:Agent 运行时诊断。
它不是只看输入输出是否合规,而是记录并分析 Agent 的完整执行轨迹,包括任务理解、工具选择、参数生成、工具返回、上下文写入、下一步规划和最终回答。工具使用税,本质上就是运行时诊断要捕捉的一类系统性风险。
局限性
这篇论文也有明显局限。
它主要测试 GSM8K 和 HotPotQA,分别代表数学推理和多跳问答,但真实 Agent 系统会更复杂。真实系统里的工具不只是计算器或检索接口,还包括数据库写操作、浏览器操作、代码执行、文件系统、云服务 API、办公系统、工单系统和安全响应系统。
语义干扰项虽然设计得比较精细,但仍然是实验构造出来的。真实世界里的噪声更长、更杂、更隐蔽,有些还会带有明确攻击意图。比如网页里的提示注入、文档里的恶意指令、工单里的错误操作建议,都会比论文里的干扰项更复杂。
另外,论文里的 NoopTool 用来隔离工具协议开销,但空工具返回并不完全等价于真实工具协议。真实工具返回会有数据结构、错误码、延迟、异常、权限失败、格式不一致等问题,协议税可能更复杂。
不过这些局限并不影响论文的核心价值。它至少证明了一个非常关键的方向:Agent 的工具调用流程本身需要被评测、被诊断、被优化,而不能只评测最终答案。
写在最后
这篇论文给 Agent 领域泼了一盆很有价值的冷水。
工具当然重要。没有工具,Agent 很难真正进入业务系统,也很难完成复杂任务。但工具不是免费的,每一次工具调用都意味着模型进入一个更复杂的协议环境。这个环境可能带来外部能力,也可能带来格式成本、协议成本、噪声放大和推理路径漂移。
过去我们常说,Agent 的能力来自“模型 + 工具”。但这篇论文提醒我们,真实公式可能更接近:
Agent 能力 = 模型能力 + 工具增量能力 − 工具协议税 − 噪声放大 − 集成错误
如果工具提供的是模型本来没有的能力,比如实时查询、精确计算、业务操作、外部系统访问,那么工具很有价值。可如果工具只是重复模型本来就能完成的推理,同时又引入复杂交互流程,那么工具调用就可能从增强器变成干扰源。
所以,Agent 系统真正需要的不是“更多工具”,而是更好的工具调用治理。
什么时候调用工具,调用哪个工具,调用后如何验证,工具结果是否真的改变了答案,工具调用是否引入了语义漂移,错误最早发生在哪个环节,这些问题会成为 Agent 运行时安全和可靠性的核心。
这篇论文最值得记住的一句话可以概括为:
工具不是 Agent 的免费外挂,而是一种有成本、有风险、会改变推理路径的系统行为。
同专题推荐
查看专题Anthropic 亲自下场做企业服务:当模型安全必须延伸到部署层
2025年5月,Anthropic宣布了一个令人意外的决定:联合黑石集团(Blackstone)、Hellman & Friedman和高盛(Goldman Sachs),成立一家独立的企业AI服务公司。
当 Agent 开始处理秘密:机密计算正在成为 AI Agent 的底层安全边界
过去讨论 Agent 安全,我们更多关注提示注入、越狱、工具滥用、记忆投毒、权限越界。