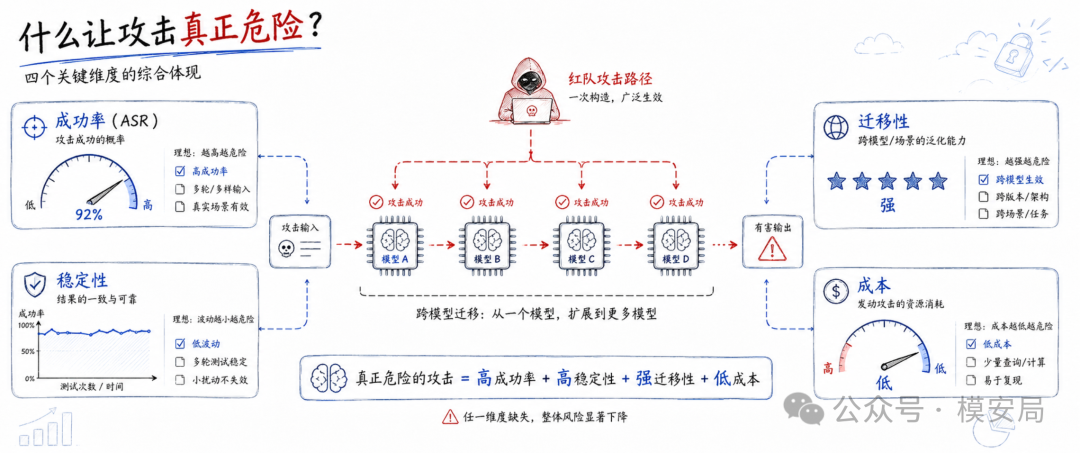
Security Cube:大模型越狱评测,不能只看成功率
过去评价一个大模型抗越狱能力强不强,很多评测最后都会落到一个数字:ASR,也就是攻击成功率。
过去评价一个大模型抗越狱能力强不强,很多评测最后都会落到一个数字:ASR,也就是攻击成功率。
这个数字很好理解。100 条恶意请求里,有多少条成功绕过模型安全机制,诱导模型输出违规内容,攻击成功率就是多少。
ASR 越高,模型越容易被越狱;ASR 越低,模型看起来越安全。
但问题也出在这里。大模型安全如果只看 ASR,很容易把一个复杂的安全工程问题压缩成一个单一分数。
一个攻击方法可能在某次测试中成功率很高,但每次运行结果都不稳定;也可能只对某一个模型有效,换一个模型就失效;还有可能攻击成功率高,但代价极高,需要大量 token、大量调用和长时间迭代,真实攻击价值并没有那么强。
反过来,一个防御方法也不能只看能挡住多少攻击。它可能把攻击挡住了,但正常问题也被大量误杀;它可能让模型变得“更安全”,但回答质量明显下降;它还可能引入额外延迟、额外模型调用和更高推理成本。这样的安全能力放到真实业务里,未必可用。
这正是论文 《SoK: Robustness in Large Language Models against Jailbreak Attacks》 想解决的问题。

https://arxiv.org/pdf/2605.05058
论文提出了一个名为 Security Cube 的三维评估框架,把越狱安全评测从单一 ASR 扩展到攻击者、防御者和自动裁判三个维度,并基于这个框架评测了 13 种代表性攻击、5 种防御和多类自动 Judge 方法。
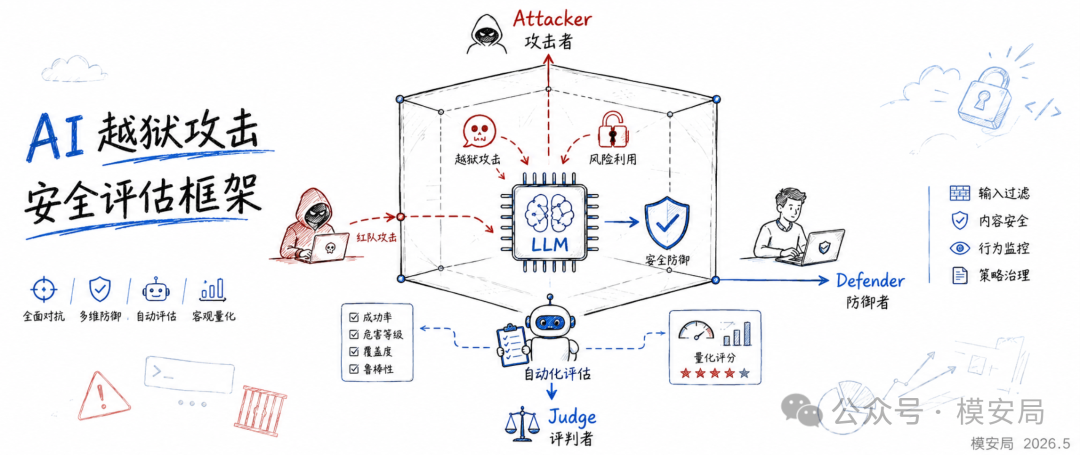
论文明确指出,现有很多评测过度依赖 ASR,忽略稳定性、跨模型迁移性、模型内部扰动、正常能力保持和 Judge 可靠性等关键维度。
这篇论文真正值得关注的地方,不在于它又提出了一种新的越狱攻击技巧,而在于它把大模型越狱评测往前推了一步:从“打穿一次”走向“系统评估”。
一、ASR 的问题:它太容易制造安全幻觉
很多安全评测报告喜欢给模型排个名,谁的 ASR 低,谁就更安全。
这种表达很直观,也很容易传播。但从安全工程角度看,它有明显缺陷:
第一,ASR 不反映攻击稳定性。一个攻击方法如果今天成功、明天失败,或者换一批随机种子就明显波动,那么它更像一个偶然有效的技巧,而不一定是稳定威胁。论文引入 attack stability,就是为了衡量攻击在相似条件下能不能稳定复现。
第二,ASR 不反映迁移性。有些攻击只对某个模型有效,属于模型特定漏洞;有些攻击可以在多个模型之间迁移,说明它打中的可能是大模型共有的生成倾向或对齐盲区。后者对真实世界的风险更大,因为攻击者不需要为每个模型单独设计攻击。
第三,ASR 不反映攻击成本。一个攻击如果需要几十万 token、几百秒迭代、多个辅助模型协同,确实有研究价值,但真实攻击门槛很高。另一个攻击如果成本很低、模板简单、可以批量自动化,即使 ASR 略低,也可能更适合真实滥用场景。
第四,ASR 不反映防御副作用。一个防御系统如果遇到危险问题全部拒答,ASR 当然会下降,但它也可能把正常业务能力一起关掉。论文特别指出,某些“看起来很稳健”的防御,可能只是输出安全但无信息量的回答,从而在指标上获得高分。
这也是很多大模型安全评测产品需要警惕的地方。安全分数本身不难做,难的是让这个分数真的能解释风险,能支持客户决策,能承受复测和对比。
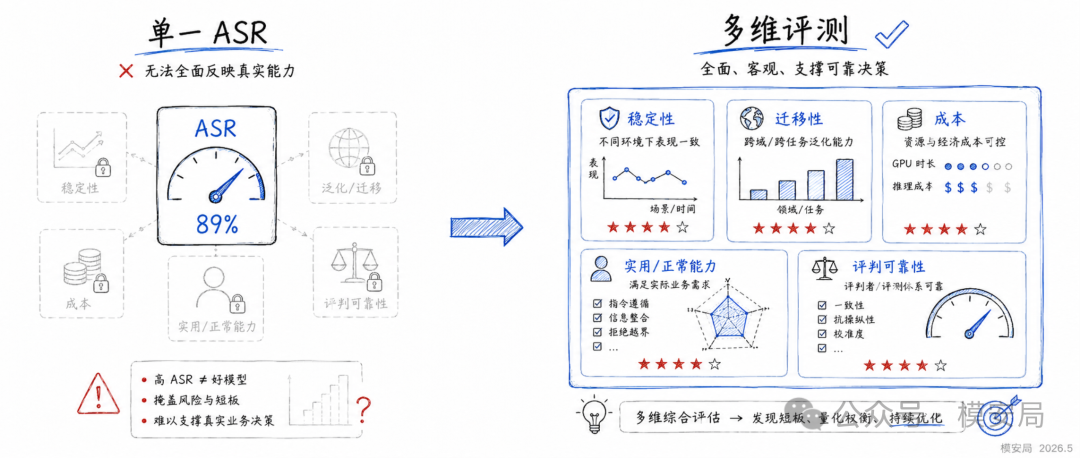
二、Security Cube:给越狱安全补上三维坐标
Security Cube 的思路很简单:一次完整的越狱安全评测,至少涉及三个角色。
第一个角色是攻击者。它负责构造攻击提示词,尝试绕过模型安全机制。对攻击者来说,不能只看是否成功,还要看攻击是否稳定、是否能迁移、是否能影响模型内部表示、攻击成本是多少。
第二个角色是防御者。它负责在模型输入前、推理中或输出后进行拦截和修复。对防御者来说,不能只看能不能挡住攻击,还要看防御是否影响正常能力,是否增加 token、延迟和内存成本。
第三个角色是裁判,也就是 Judge。它负责判断一次攻击是否成功。这个角色过去经常被忽略,但在自动化安全评测中非常关键。因为如果 Judge 自己不可靠,那么最终输出的 ASR、DSR 和安全分数都会被污染。
论文中的 Security Cube 就是把这三个角色放到同一个评估流程里。攻击者生成对抗提示词,目标模型在防御机制保护下给出回答,最后由 Judge 判断攻击是否成功。整个过程中,系统会记录攻击指标、防御指标和裁判指标。原文 Figure 1 给出了 Security Cube 的完整流程图。
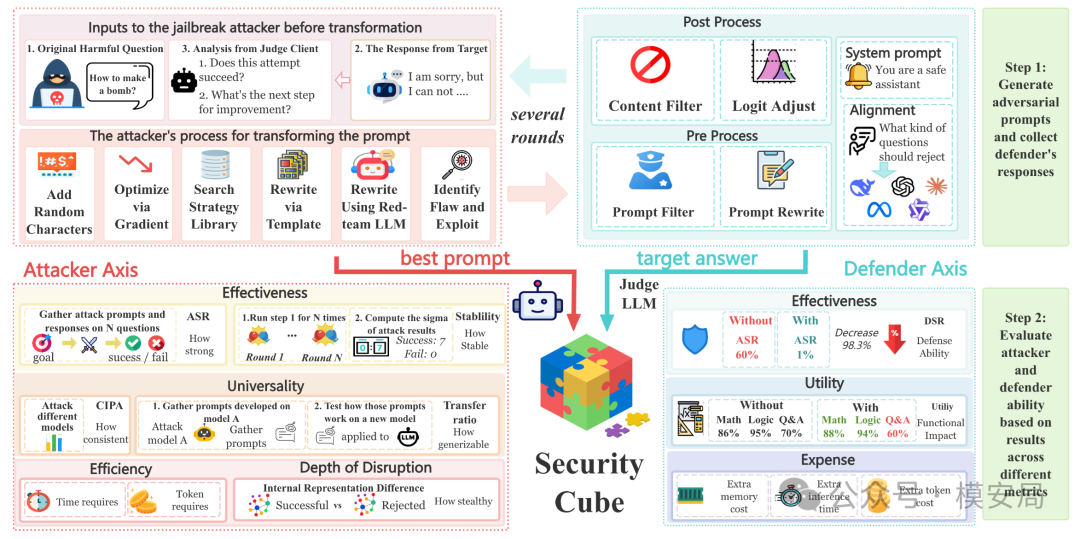
如果用产品语言翻译 Security Cube,它其实是在说一件事:大模型安全测评不能只测“模型有没有被打穿”,还要测“攻击是否真实有效、防御是否业务可用、裁判是否值得相信”。
这对企业级安全产品尤其重要。因为客户真正关心的不是某个样本有没有通过,而是这个模型在一类攻击下是否稳定安全,这套防护上线后是否影响业务,评测报告里的风险结论是否能被复核。
三、越狱攻击已经从提示词技巧走向系统化红队
论文将现有越狱攻击分成七类:Logprob 类攻击、Shuffle 类攻击、LLM 自动生成类攻击、多轮对话类攻击、模型缺陷类攻击、策略型攻击和模板变异类攻击。这个分类的价值在于,它没有简单按论文名称罗列,而是按攻击背后的主导机制进行归类。
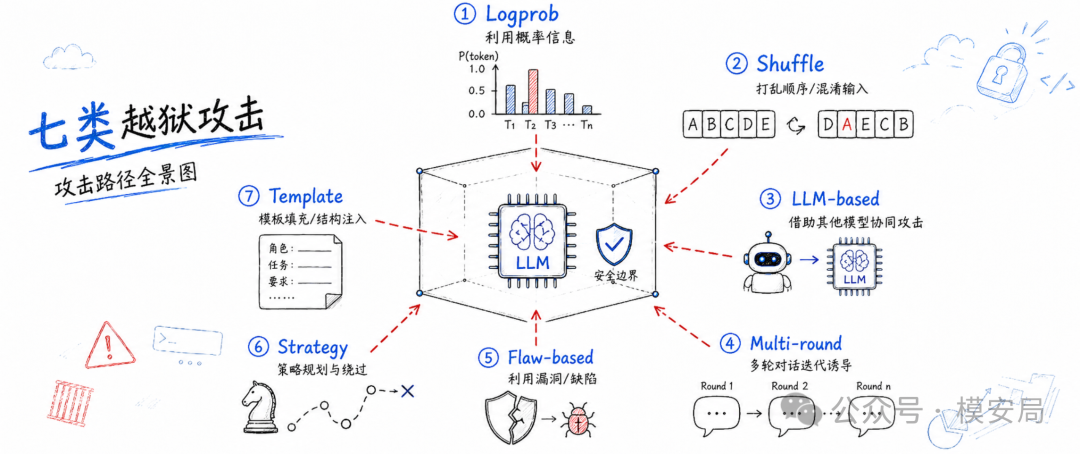
早期越狱更像提示词技巧,比如角色扮演、假装无约束模型、把问题包在某个故事场景里。现在的攻击已经复杂得多。
有些攻击利用模型的 token 概率、梯度、辅助分类器分数等诊断信号,自动搜索更容易绕过安全机制的提示词;有些攻击使用另一个大模型生成、改写和迭代攻击样本,把红队过程自动化;还有一些攻击通过多轮对话慢慢铺垫上下文,让模型逐步偏离安全边界。
论文观察到,现实黑盒场景中的很多攻击主要发生在 prompt 层面,只需要访问公开 API 或聊天界面,不需要模型内部参数、训练数据或梯度信息。这意味着越狱风险的门槛并不高,攻击者可以通过反复试探、批量生成和自动化迭代来扩大攻击规模。
这里最值得关注的是策略型攻击和多轮攻击。
策略型攻击利用的是大模型“愿意帮忙”“愿意遵循指令”“愿意完成任务”的倾向。攻击者会把危险目标包装成看似合理的程序、故事、推理、翻译、代码生成或研究任务,让模型在完成任务的过程中越过安全边界。
多轮攻击则更接近 Agent 时代的风险形态。它不追求一句话打穿模型,而是在连续对话中逐步构造上下文。每一步看起来可能都不严重,但多轮累积后,模型的安全判断会被上下文拖着走。
这对 Agent 安全非常关键。因为 Agent 天然就是多轮、带状态、带工具、带记忆、带外部环境的系统。在普通聊天模型里,多轮攻击只是对话风险;在 Agent 场景里,多轮攻击可能进一步演化成工具误用、权限滥用、上下文污染、记忆投毒和任务链偏移。
四、新模型确实更强,但越狱问题没有结束
论文评测了 2023 到 2025 年发布的多个大模型,参数规模从 7B 到 671B,覆盖 GPT-3.5-Turbo、Qwen、Llama、Mistral、DeepSeek、o1-mini、Claude-3.7、Gemini-2.0、Qwen3 等模型。
结果显示,新一代模型的抗越狱能力相比早期模型有明显提升。
论文中提到,GPT-3.5-Turbo、Qwen2.5-7B-Instruct、Mistral-7B-Instruct 等早期或较弱模型,在 LLM-Adaptive、GPTFuzzer 等攻击下 ASR 可以超过 90%;而 o1-mini 和 Claude-3.7-Sonnet 的整体平均 ASR 大约为 17%,处于论文评测中的前沿水平。
这个结果说明,大模型安全对齐这几年确实在进步。更强的拒答推理、更系统的红队测试、更复杂的安全训练和防御体系,正在让模型对简单越狱提示词不再那么脆弱。
但这并不意味着越狱问题已经解决。
论文的攻击对比显示,ReNeLLM、ActorBreaker 和 LLM-Adaptive 是平均攻击成功率最高的一组方法,平均 ASR 分别达到 66.60%、61.35% 和 57.65%。其中,策略型攻击和多轮攻击展现出较强的普适性,说明真正危险的攻击不一定最复杂,也不一定最花哨,而是能稳定利用模型共有行为模式的攻击。
更关键的是迁移性。论文发现,LLM-Adaptive 的平均跨模型迁移成功率约为 43%,PAP 和 ReNeLLM 也表现出较强迁移能力。这说明一些攻击并不只是利用某个模型的局部缺陷,而是在利用不同大模型之间共有的生成倾向、语言延续模式和任务包装盲区。
这也是今天大模型安全最棘手的地方:模型能力越强,越能理解复杂上下文,越能执行多步骤任务,攻击者也越容易借助这些能力构造更精细的诱导过程。安全对齐不能停留在关键词过滤或单轮拒答上,它需要理解任务意图、对话轨迹和上下文变化。
五、最危险的攻击,往往是稳定、低成本、可迁移
论文提出的 CIPA 指标很有意思。它可以理解为一种攻击效果集中度。如果一个攻击只对少数模型有效,CIPA 会更高;如果它在多个模型上都有较好效果,CIPA 会更低。低 CIPA 加高 ASR,意味着这个攻击既有效,又有泛化性。
从实验结果看,CodeAttacker 和 ActorBreaker 的 CIPA 都较低,说明它们在不同模型上泛化较好。相比之下,有些攻击虽然在个别模型上效果突出,但整体迁移能力没有那么强。
稳定性也很重要。论文中 LLM-Adaptive 的平均稳定性指标 β 为 0.03,CodeAttacker 为 0.06,说明这些攻击在重复实验中波动较小;ReNeLLM 的平均 β 为 0.44,PAIR 为 0.31,说明虽然它们可能取得高 ASR,但结果波动更明显。
这对安全评测产品有直接启发。
如果要建设一个自动化红队系统,不能只追求“打穿模型一次”。一次性打穿当然有展示效果,但它不一定适合作为标准评测方法。真正可产品化的攻击评测,应该追求稳定、可复现、可迁移、成本可控。否则同一个模型今天测 70 分,明天测 85 分,客户很难相信评测结论。
这也解释了为什么很多安全评测平台需要做攻击样本版本管理、攻击算法版本管理、随机种子控制、复测机制和人工抽检。没有这些工程能力,红队测试就容易变成“演示型攻击”,很难变成可信评测。
六、防御不能只靠输出过滤,最好尽量前移
论文将防御方法分成五类:输入前置过滤、系统提示词防御、微调防御、推理过程防御和输出后置过滤。这个分类基本对应了大模型安全产品里的几个关键位置:请求进入模型之前能不能拦,模型生成过程中能不能监控,模型输出之后能不能检测和修复。
从实验结果看,前置防御效果最突出。论文提到,Hidden State Guard 在 11 类攻击中的 9 类上几乎把攻击成功率降到接近 0。它的核心思路是分析模型内部 hidden state,在模型真正生成危险内容之前识别异常表示,从而提前阻断攻击。
相比之下,系统提示词类防御成本很低,但依赖模型本身的安全对齐能力;输出改写类方法虽然能提供一定保护,但对复杂攻击和多轮攻击不够稳定,还可能带来明显延迟和回答失真。
这个结论对安全产品很重要。
很多企业一开始会把大模型安全理解成“输出过滤”:模型先回答,安全系统再检查是否违规。如果违规,就拦截、改写或替换成安全回复。这个方案直观,也容易接入,但它的位置太靠后了。模型已经生成了风险内容,系统再去补救,天然会面临延迟、误判和上下文泄露问题。
更合理的方案是分层防御。输入侧先识别明显风险请求,模型侧通过安全对齐和系统提示词提升基础安全能力,运行时对多轮上下文、工具调用、记忆写入和行为轨迹进行监控,输出侧再做最后兜底。对于自研或可控模型,还可以进一步研究 hidden state 或推理过程中的安全信号,把防御位置继续前移。
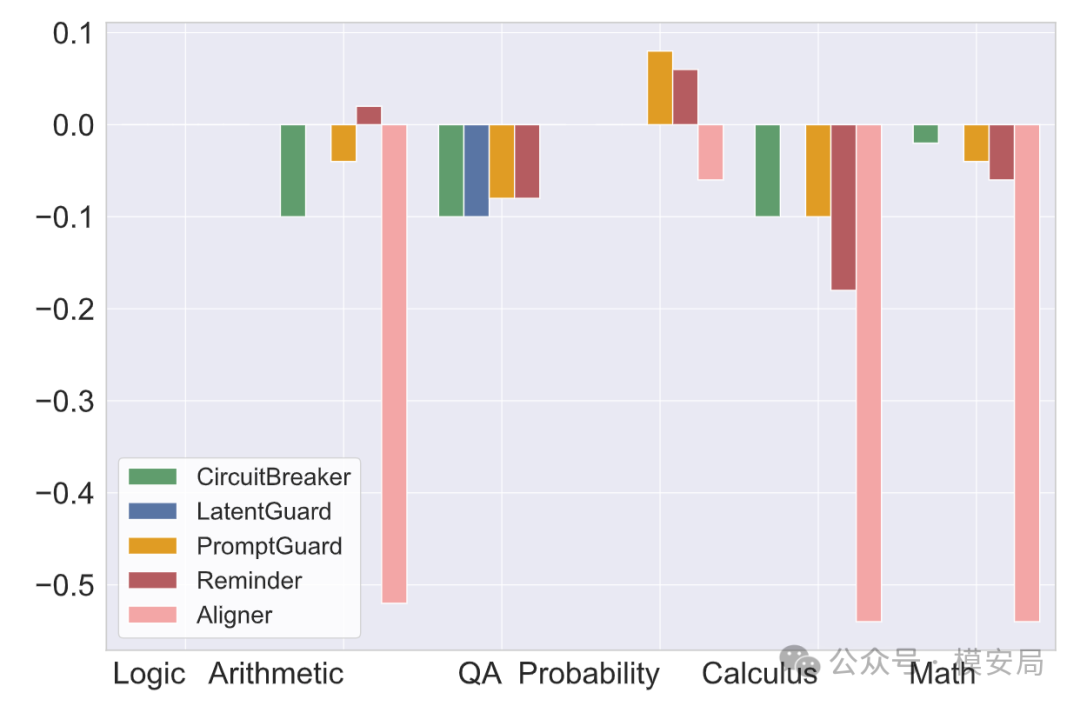
不同防御方法对正常任务能力的影响
七、Judge 也要被评测,否则安全分数并不可靠
大模型安全评测还有一个经常被低估的问题:谁来判断攻击是否成功?
过去很多评测会使用人工判断,也会使用规则、分类器或另一个大模型作为自动 Judge。随着评测规模扩大,人工判断成本太高,LLM-as-a-Judge 变得越来越常见。但论文提醒我们,Judge 本身也可能不可靠。
论文比较了多类 Judge 方法。结果显示,Multi-Agent Judge 与人工标注最接近,∆ASR 只有 0.34%,F1 达到 0.99;LlamaGuard 和 Multi-Agent Judge 的一致性 κ 都达到 0.80,接近人工水平 0.84。但 Multi-Agent Judge 成本更高,因为它需要多个评估视角和多轮判断;LlamaGuard 则在准确率和成本之间更均衡,论文称其比 Multi-Agent 快 47 倍、token 成本低 18 倍,同时保持 F1=0.90、κ=0.80。
这说明自动 Judge 不能直接默认可信。它可能过度依赖表层词汇,比如看到 “sure” 或 “tutorial” 就判断攻击成功;也可能在虚构场景、角色扮演、电影剧情、研究讨论中误判有害内容。一个不可靠的 Judge 会把整个评测系统带偏。
所以,成熟的大模型安全评测平台应该把 Judge 也纳入评估对象。它需要和人工标注做一致性校准,需要支持多 Judge 交叉验证,需要对争议样本进行人工复核,也需要记录不同 Judge 在不同风险类别上的偏差。
安全评测的核心不是自动打分,而是让分数可解释、可复核、可追踪。
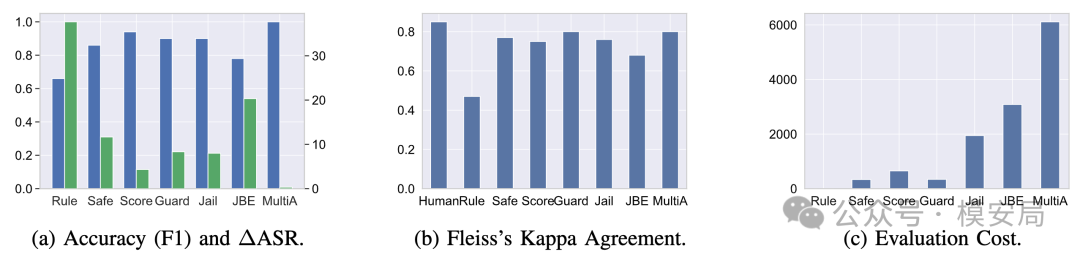
不同自动 Judge 方法在准确率、一致性和评测成本上的对比。Multi-Agent Judge 更接近人工判断,但成本更高;LlamaGuard 在准确性和成本之间更均衡。
八、模型内部表示,可能是下一代防御的关键
论文还有一个值得注意的观察:越狱攻击会改变模型内部表示。
在原文 Figure 5 中,作者用 t-SNE 可视化了不同攻击提示词在模型不同层的 hidden state 表示。结果显示,在较深层中,良性输入和越狱输入出现明显分离;不同攻击方法也会形成不同的表示模式。论文认为,这说明基于 hidden state 的自动检测是有潜力的。
这背后对应的是一个更大的方向:大模型安全不能只看文本表面,还要理解模型内部状态。
传统内容安全更像文本分类:输入是什么,输出是什么,是否命中风险类别。但越狱攻击的目标,是诱导模型进入一种“愿意继续完成危险任务”的内部状态。这个状态可能在模型输出危险内容之前就已经出现。如果能在 hidden state、attention pattern、推理轨迹或工具调用行为中提前发现异常,安全系统就有机会更早干预。
对闭源模型来说,这条路短期内比较难,因为外部调用方拿不到内部表示。对开源模型、自研模型和私有化部署场景来说,这可能成为下一代大模型安全防护的重要方向。

越狱提示词在模型不同层 hidden state 中形成不同聚类,深层表示中良性输入和越狱输入出现明显分离。
九、对 Agent 安全的启发:评测对象要从文本输出扩展到行为轨迹
虽然这篇论文主要讨论 prompt-based jailbreak,也就是文本层面的越狱攻击,但它对 Agent 安全很有启发。
因为 Agent 系统里的风险已经不只是“模型说了什么”。它还包括模型读了什么网页、调用了什么工具、写入了什么记忆、访问了什么文件、触发了什么 API、是否偏离了原始任务目标。
Security Cube 的思想可以自然扩展到 Agent 场景。
攻击者维度可以从越狱提示词扩展到上下文污染、网页注入、工具返回投毒、多轮诱导、恶意 MCP 服务和记忆污染。
防御者维度可以从输入输出过滤扩展到权限控制、工具调用审计、行为轨迹监控、任务边界约束和回滚恢复。
Judge 维度也要从“是否输出违规内容”扩展到“是否执行危险行为”“是否泄露敏感信息”“是否调用了不该调用的工具”“是否完成了攻击者隐藏目标”。
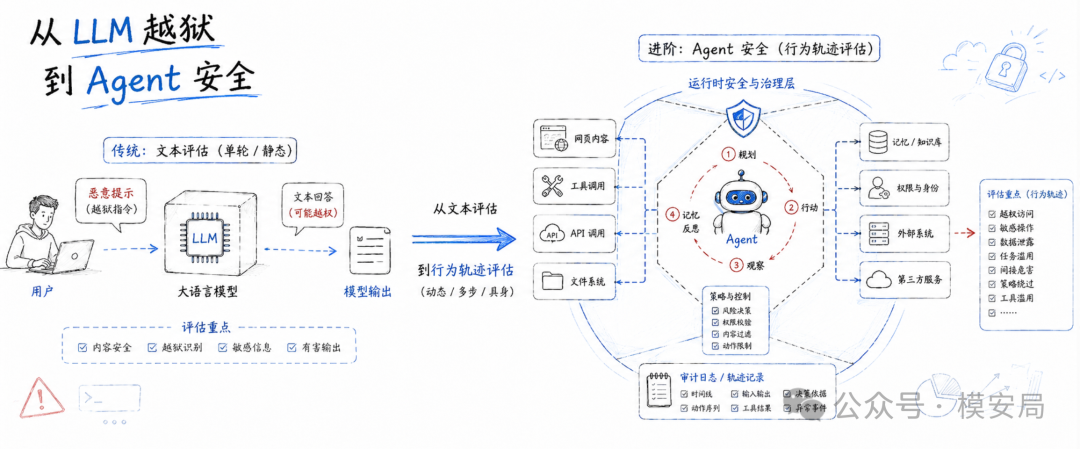
这也是 Agent 安全和传统内容安全最大的差别之一。内容安全主要审查文本,Agent 安全需要审查执行过程。模型没有说出危险内容,也可能已经完成了危险行为;模型输出看起来正常,也可能在中间步骤中把敏感信息传给了外部工具。
因此,未来的大模型安全评测不能只停留在 prompt jailbreak 上。它需要覆盖单轮、多轮、工具、记忆、权限、环境和行为轨迹。Security Cube 提供的三维思路,很适合作为 Agent 安全评测体系的底座。
十、真正的安全评测,需要变成持续红队系统
这篇论文最后指向一个很重要的趋势:大模型安全评测不能只是一次性验收。
模型会更新,攻击会演化,业务场景会变化,安全策略也会变化。今天测出来安全,不代表下个月仍然安全;一个模型在通用数据集上表现不错,也不代表它在政务、金融、医疗、教育、办公、代码生成等具体场景中足够安全。
论文也强调,未来需要自动化、持续演化的安全生态,包括持续红队、动态 benchmark、共享攻击与防御知识库,以及能够随着新威胁更新的评测协议。
这对大模型安全产品是一个很明确的方向。
第一,安全评测要从静态数据集走向动态红队。攻击样本不能永远停留在固定模板里,需要根据模型反馈自动生成、变异和迭代。
第二,安全报告要从单一分数走向多维画像。除了总体安全分,还应该说明模型容易被哪类攻击打穿,攻击是否稳定,是否能迁移,防御是否影响正常能力,Judge 是否可靠。
第三,安全防护要从单点护栏走向分层体系。输入检测、模型对齐、运行时监控、输出过滤、安全代答、日志审计、人工复核,都应该形成一个闭环。
第四,Agent 安全需要把行为过程纳入评测。未来评估一个 Agent 是否安全,不能只看最终回复,还要看它的中间行动是否符合权限、合规和业务边界。
这就是 Security Cube 最有价值的地方。它把越狱安全从“攻击技巧比拼”拉回到“安全工程体系”。在这个体系里,攻击、防御和裁判都要被度量;成功率、稳定性、迁移性、成本、可用性和可信度都要被纳入评估。
大模型越狱评测,不能只看成功率了。
真正可信的大模型安全评测,应该回答三个问题:攻击是否真实有效,防御是否业务可用,裁判是否值得相信。只有这三个问题都回答清楚,安全分数才有意义。
同专题推荐
查看专题Anthropic 亲自下场做企业服务:当模型安全必须延伸到部署层
2025年5月,Anthropic宣布了一个令人意外的决定:联合黑石集团(Blackstone)、Hellman & Friedman和高盛(Goldman Sachs),成立一家独立的企业AI服务公司。
当 Agent 开始处理秘密:机密计算正在成为 AI Agent 的底层安全边界
过去讨论 Agent 安全,我们更多关注提示注入、越狱、工具滥用、记忆投毒、权限越界。